 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing through Satellite Images at Street Views
May 22, 2025This paper studies the task of SatStreet-view synthesis, which aims to render photorealistic street-view panorama images and videos given any satellite image and specified camera positions or trajectories. We formulate to learn neural radiance field from paired images captured from satellite and street viewpoints, which comes to be a challenging learning problem due to the sparse-view natural and the extremely-large viewpoint changes between satellite and street-view images. We tackle the challenges based on a task-specific observation that street-view specific elements, including the sky and illumination effects are only visible in street-view panoramas, and present a novel approach Sat2Density++ to accomplish the goal of photo-realistic street-view panoramas rendering by modeling these street-view specific in neural networks. In the experiments, our method is testified on both urban and suburban scene datasets, demonstrating that Sat2Density++ is capable of rendering photorealistic street-view panoramas that are consistent across multiple views and faithful to the satellite image.
Learning Deformable Hypothesis Sampling for Accurate PatchMatch Multi-View Stereo
Dec 26, 2023This paper introduces a learnable Deformable Hypothesis Sampler (DeformSampler) to address the challenging issue of noisy depth estimation for accurate PatchMatch Multi-View Stereo (MVS). We observe that the heuristic depth hypothesis sampling modes employed by PatchMatch MVS solvers are insensitive to (i) the piece-wise smooth distribution of depths across the object surface, and (ii) the implicit multi-modal distribution of depth prediction probabilities along the ray direction on the surface points. Accordingly, we develop DeformSampler to learn distribution-sensitive sample spaces to (i) propagate depths consistent with the scene's geometry across the object surface, and (ii) fit a Laplace Mixture model that approaches the point-wise probabilities distribution of the actual depths along the ray direction. We integrate DeformSampler into a learnable PatchMatch MVS system to enhance depth estimation in challenging areas, such as piece-wise discontinuous surface boundaries and weakly-textured regions. Experimental results on DTU and Tanks \& Temples datasets demonstrate its superior performance and generalization capabilities compared to state-of-the-art competitors. Code is available at https://github.com/Geo-Tell/DS-PMNet.
Shape Anchor Guided Holistic Indoor Scene Understanding
Sep 20, 2023This paper proposes a shape anchor guided learning strategy (AncLearn) for robust holistic indoor scene understanding. We observe that the search space constructed by current methods for proposal feature grouping and instance point sampling often introduces massive noise to instance detection and mesh reconstruction. Accordingly, we develop AncLearn to generate anchors that dynamically fit instance surfaces to (i) unmix noise and target-related features for offering reliable proposals at the detection stage, and (ii) reduce outliers in object point sampling for directly providing well-structured geometry priors without segmentation during reconstruction. We embed AncLearn into a reconstruction-from-detection learning system (AncRec) to generate high-quality semantic scene models in a purely instance-oriented manner. Experiments conducted on the challenging ScanNetv2 dataset demonstrate that our shape anchor-based method consistently achieves state-of-the-art performance in terms of 3D object detection, layout estimation, and shape reconstruction. The code will be available at https://github.com/Geo-Tell/AncRec.
ELKPPNet: An Edge-aware Neural Network with Large Kernel Pyramid Pooling for Learning Discriminative Features in Semantic Segmentation
Jun 27, 2019
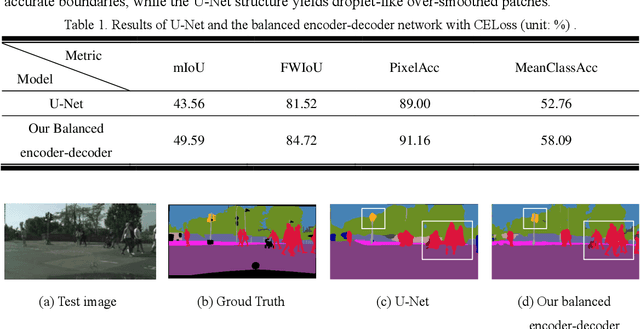
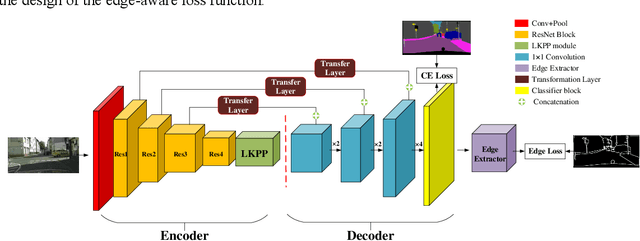
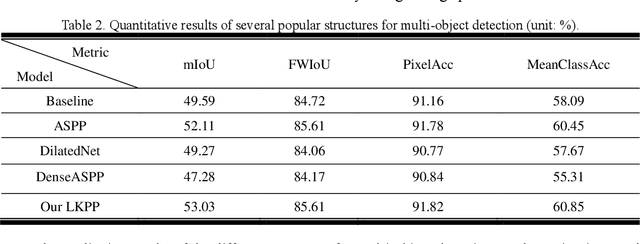
Semantic segmentation has been a hot topic across diverse research fields. Along with the success of deep convolutional neural networks, semantic segmentation has made great achievements and improvements, in terms of both urban scene parsing and indoor semantic segmentation. However, most of the state-of-the-art models are still faced with a challenge in discriminative feature learning, which limits the ability of a model to detect multi-scale objects and to guarantee semantic consistency inside one object or distinguish different adjacent objects with similar appearance. In this paper, a practical and efficient edge-aware neural network is presented for semantic segmentation. This end-to-end trainable engine consists of a new encoder-decoder network, a large kernel spatial pyramid pooling (LKPP) block, and an edge-aware loss function. The encoder-decoder network was designed as a balanced structure to narrow the semantic and resolution gaps in multi-level feature aggregation, while the LKPP block was constructed with a densely expanding receptive field for multi-scale feature extraction and fusion. Furthermore, the new powerful edge-aware loss function is proposed to refine the boundaries directly from the semantic segmentation prediction for more robust and discriminative features. The effectiveness of the proposed model was demonstrated using Cityscapes, CamVid, and NYUDv2 benchmark datasets. The performance of the two structures and the edge-aware loss function in ELKPPNet was validated on the Cityscapes dataset, while the complete ELKPPNet was evaluated on the CamVid and NYUDv2 datasets. A comparative analysis with the state-of-the-art methods under the same conditions confirmed the superiority of the proposed algorithm.