 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELKPPNet: An Edge-aware Neural Network with Large Kernel Pyramid Pooling for Learning Discriminative Features in Semantic Segmentation
Paper and Code

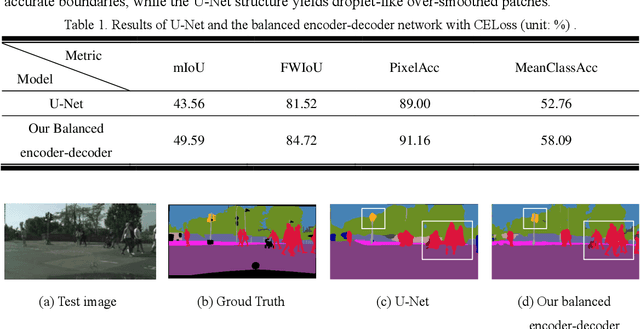
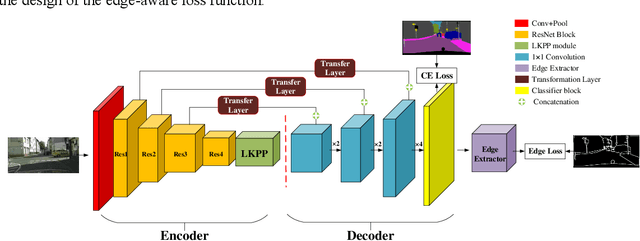
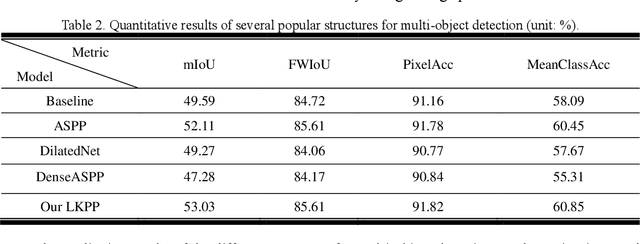
Semantic segmentation has been a hot topic across diverse research fields. Along with the success of deep convolutional neural networks, semantic segmentation has made great achievements and improvements, in terms of both urban scene parsing and indoor semantic segmentation. However, most of the state-of-the-art models are still faced with a challenge in discriminative feature learning, which limits the ability of a model to detect multi-scale objects and to guarantee semantic consistency inside one object or distinguish different adjacent objects with similar appearance. In this paper, a practical and efficient edge-aware neural network is presented for semantic segmentation. This end-to-end trainable engine consists of a new encoder-decoder network, a large kernel spatial pyramid pooling (LKPP) block, and an edge-aware loss function. The encoder-decoder network was designed as a balanced structure to narrow the semantic and resolution gaps in multi-level feature aggregation, while the LKPP block was constructed with a densely expanding receptive field for multi-scale feature extraction and fusion. Furthermore, the new powerful edge-aware loss function is proposed to refine the boundaries directly from the semantic segmentation prediction for more robust and discriminative features. The effectiveness of the proposed model was demonstrated using Cityscapes, CamVid, and NYUDv2 benchmark datasets. The performance of the two structures and the edge-aware loss function in ELKPPNet was validated on the Cityscapes dataset, while the complete ELKPPNet was evaluated on the CamVid and NYUDv2 datasets. A comparative analysis with the state-of-the-art methods under the same conditions confirmed the superiority of the proposed algorithm.