 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLuoJiaHOG: A Hierarchy Oriented Geo-aware Image Caption Dataset for Remote Sensing Image-Text Retrival
Mar 16, 2024Image-text retrieval (ITR) plays a significant role in making informed decisions for various remote sensing (RS) applications. Nonetheless, creating ITR datasets containing vision and language modalities not only requires significant geo-spatial sampling area but also varing categories and detailed descriptions. To this end, we introduce an image caption dataset LuojiaHOG, which is geospatial-aware, label-extension-friendly and comprehensive-captioned. LuojiaHOG involves the hierarchical spatial sampling, extensible classification system to Open Geospatial Consortium (OGC) standards, and detailed caption generation. In addition, we propose a CLIP-based Image Semantic Enhancement Network (CISEN) to promote sophisticated ITR. CISEN consists of two components, namely dual-path knowledge transfer and progressive cross-modal feature fusion. Comprehensive statistics on LuojiaHOG reveal the richness in sampling diversity, labels quantity and descriptions granularity. The evaluation on LuojiaHOG is conducted across various state-of-the-art ITR models, including ALBEF, ALIGN, CLIP, FILIP, Wukong, GeoRSCLIP and CISEN. We use second- and third-level labels to evaluate these vision-language models through adapter-tuning and CISEN demonstrates superior performance. For instance, it achieves the highest scores with WMAP@5 of 88.47\% and 87.28\% on third-level ITR tasks, respectively. In particular, CISEN exhibits an improvement of approximately 1.3\% and 0.9\% in terms of WMAP@5 compared to its baseline. These findings highlight CISEN advancements accurately retrieving pertinent information across image and text. LuojiaHOG and CISEN can serve as a foundational resource for future RS image-text alignment research, facilitating a wide range of vision-language applications.
BuildMapper: A Fully Learnable Framework for Vectorized Building Contour Extraction
Nov 07, 2022



Deep learning based methods have significantly boosted the study of automatic building extraction from remote sensing images. However, delineating vectorized and regular building contours like a human does remains very challenging, due to the difficulty of the methodology, the diversity of building structures, and the imperfect imaging conditions. In this paper, we propose the first end-to-end learnable building contour extraction framework, named BuildMapper, which can directly and efficiently delineate building polygons just as a human does. BuildMapper consists of two main components: 1) a contour initialization module that generates initial building contours; and 2) a contour evolution module that performs both contour vertex deformation and reduction, which removes the need for complex empirical post-processing used in existing methods. In both components, we provide new ideas, including a learnable contour initialization method to replace the empirical methods, dynamic predicted and ground truth vertex pairing for the static vertex correspondence problem, and a lightweight encoder for vertex information extraction and aggregation, which benefit a general contour-based method; and a well-designed vertex classification head for building corner vertices detection, which casts light on direct structured building contour extraction. We also built a suitable large-scale building dataset, the WHU-Mix (vector) building dataset, to benefit the study of contour-based building extraction methods. The extensive experiments conducted on the WHU-Mix (vector) dataset, the WHU dataset, and the CrowdAI dataset verified that BuildMapper can achieve a state-of-the-art performance, with a higher mask average precision (AP) and boundary AP than both segmentation-based and contour-based methods.
Unmixing Convolutional Features for Crisp Edge Detection
Nov 19, 2020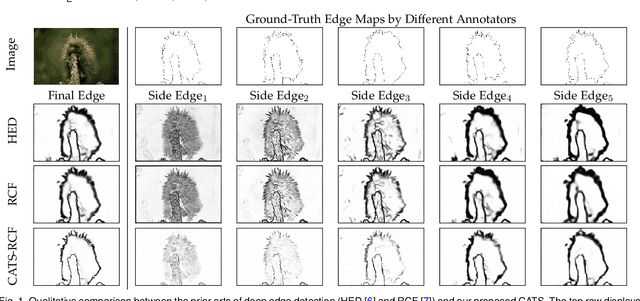
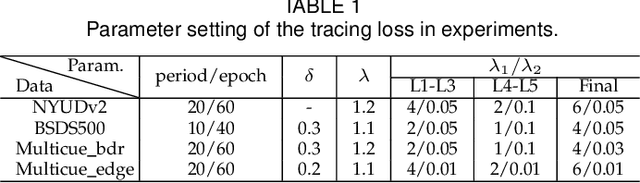
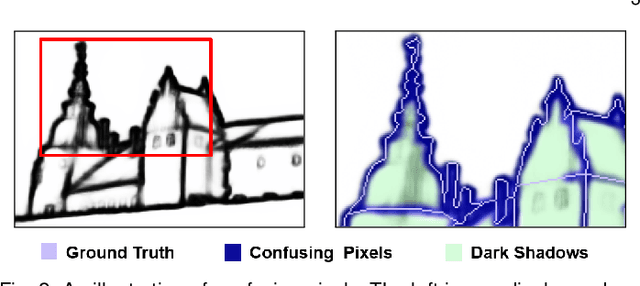
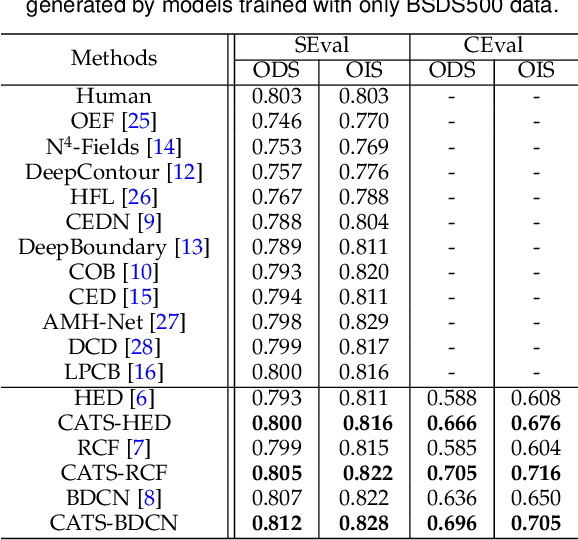
This paper presents a context-aware tracing strategy (CATS) for crisp edge detection with deep edge detectors, based on an observation that the localization ambiguity of deep edge detectors is mainly caused by the mixing phenomenon of convolutional neural networks: feature mixing in edge classification and side mixing during fusing side predictions. The CATS consists of two modules: a novel tracing loss that performs feature unmixing by tracing boundaries for better side edge learning, and a context-aware fusion block that tackles the side mixing by aggregating the complementary merits of learned side edges. Experiments demonstrate that the proposed CATS can be integrated into modern deep edge detectors to improve localization accuracy. With the vanilla VGG16 backbone, in terms of BSDS500 dataset, our CATS improves the F-measure (ODS) of the RCF and BDCN deep edge detectors by 12% and 6% respectively when evaluating without using the morphological non-maximal suppression scheme for edge detection.
ELKPPNet: An Edge-aware Neural Network with Large Kernel Pyramid Pooling for Learning Discriminative Features in Semantic Segmentation
Jun 27, 2019
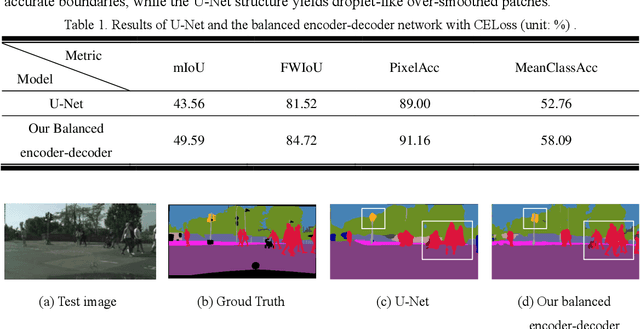
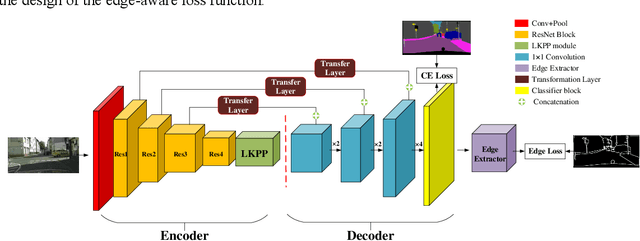
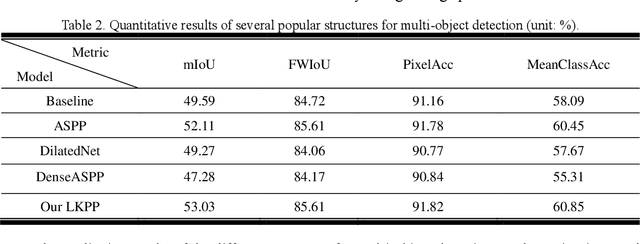
Semantic segmentation has been a hot topic across diverse research fields. Along with the success of deep convolutional neural networks, semantic segmentation has made great achievements and improvements, in terms of both urban scene parsing and indoor semantic segmentation. However, most of the state-of-the-art models are still faced with a challenge in discriminative feature learning, which limits the ability of a model to detect multi-scale objects and to guarantee semantic consistency inside one object or distinguish different adjacent objects with similar appearance. In this paper, a practical and efficient edge-aware neural network is presented for semantic segmentation. This end-to-end trainable engine consists of a new encoder-decoder network, a large kernel spatial pyramid pooling (LKPP) block, and an edge-aware loss function. The encoder-decoder network was designed as a balanced structure to narrow the semantic and resolution gaps in multi-level feature aggregation, while the LKPP block was constructed with a densely expanding receptive field for multi-scale feature extraction and fusion. Furthermore, the new powerful edge-aware loss function is proposed to refine the boundaries directly from the semantic segmentation prediction for more robust and discriminative features. The effectiveness of the proposed model was demonstrated using Cityscapes, CamVid, and NYUDv2 benchmark datasets. The performance of the two structures and the edge-aware loss function in ELKPPNet was validated on the Cityscapes dataset, while the complete ELKPPNet was evaluated on the CamVid and NYUDv2 datasets. A comparative analysis with the state-of-the-art methods under the same conditions confirmed the superiority of the proposed algorithm.
RSI-CB: A Large Scale Remote Sensing Image Classification Benchmark via Crowdsource Data
Jun 11, 2017
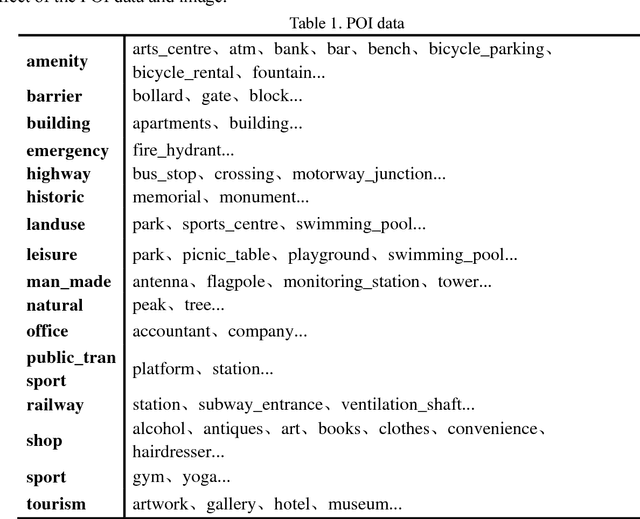

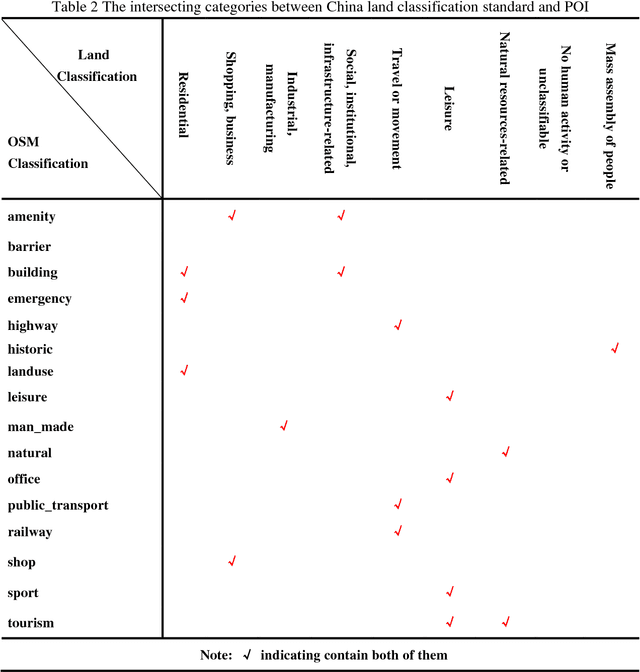
Remote sensing image classification is a fundamental task in remote sensing image processing. Remote sensing field still lacks of such a large-scale benchmark compared to ImageNet, Place2. We propose a remote sensing image classification benchmark (RSI-CB) based on crowd-source data which is massive, scalable, and diversity. Using crowdsource data, we can efficiently annotate ground objects in remotes sensing image by point of interests, vectors data from OSM or other crowd-source data. Based on this method, we construct a worldwide large-scale benchmark for remote sensing image classification. In this benchmark, there are two sub datasets with 256 * 256 and 128 * 128 size respectively since different convolution neural networks requirement different image size. The former sub dataset contains 6 categories with 35 subclasses with total of more than 24,000 images; the later one contains 6 categories with 45 subclasses with total of more than 36,000 images. The six categories are agricultural land, construction land and facilities, transportation and facilities, water and water conservancy facilities, woodland and other land, and each category has several subclasses. This classification system is defined according to the national standard of land use classification in China, and is inspired by the hierarchy mechanism of ImageNet. Finally, we have done a large number of experiments to compare RSI-CB with SAT-4, UC-Merced datasets on handcrafted features, such as such as SIFT, and classical CNN models, such as AlexNet, VGG, GoogleNet, and ResNet. We also show CNN models trained by RSI-CB have good performance when transfer to other dataset, i.e. UC-Merced, and good generalization ability. The experiments show that RSI-CB is more suitable as a benchmark for remote sensing image classification task than other ones in big data era, and can be potentially used in practical applications.