 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShape Anchor Guided Holistic Indoor Scene Understanding
Sep 20, 2023This paper proposes a shape anchor guided learning strategy (AncLearn) for robust holistic indoor scene understanding. We observe that the search space constructed by current methods for proposal feature grouping and instance point sampling often introduces massive noise to instance detection and mesh reconstruction. Accordingly, we develop AncLearn to generate anchors that dynamically fit instance surfaces to (i) unmix noise and target-related features for offering reliable proposals at the detection stage, and (ii) reduce outliers in object point sampling for directly providing well-structured geometry priors without segmentation during reconstruction. We embed AncLearn into a reconstruction-from-detection learning system (AncRec) to generate high-quality semantic scene models in a purely instance-oriented manner. Experiments conducted on the challenging ScanNetv2 dataset demonstrate that our shape anchor-based method consistently achieves state-of-the-art performance in terms of 3D object detection, layout estimation, and shape reconstruction. The code will be available at https://github.com/Geo-Tell/AncRec.
Holistic Geometric Feature Learning for Structured Reconstruction
Sep 18, 2023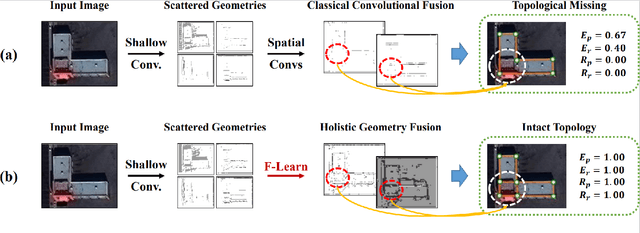


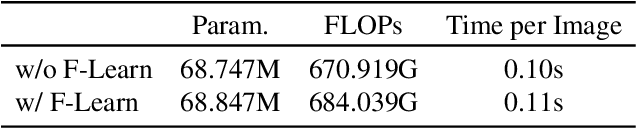
The inference of topological principles is a key problem in structured reconstruction. We observe that wrongly predicted topological relationships are often incurred by the lack of holistic geometry clues in low-level features. Inspired by the fact that massive signals can be compactly described with frequency analysis, we experimentally explore the efficiency and tendency of learning structure geometry in the frequency domain. Accordingly, we propose a frequency-domain feature learning strategy (F-Learn) to fuse scattered geometric fragments holistically for topology-intact structure reasoning. Benefiting from the parsimonious design, the F-Learn strategy can be easily deployed into a deep reconstructor with a lightweight model modification. Experiments demonstrate that the F-Learn strategy can effectively introduce structure awareness into geometric primitive detection and topology inference, bringing significant performance improvement to final structured reconstruction. Code and pre-trained models are available at https://github.com/Geo-Tell/F-Learn.
Unmixing Convolutional Features for Crisp Edge Detection
Nov 19, 2020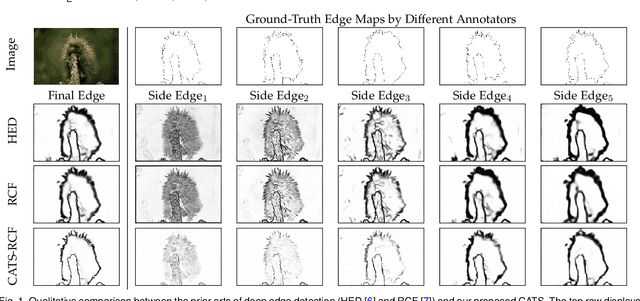
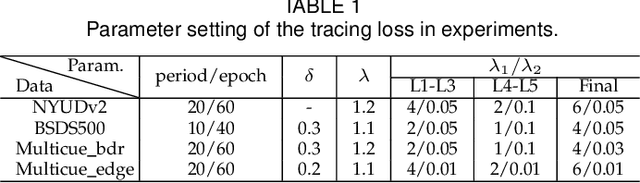
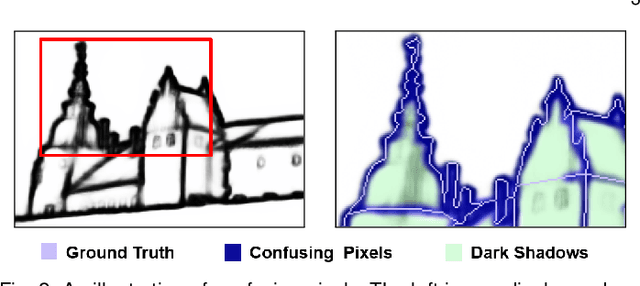
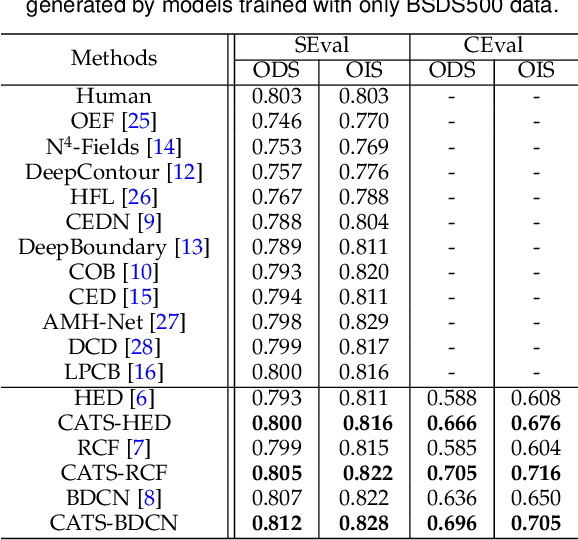
This paper presents a context-aware tracing strategy (CATS) for crisp edge detection with deep edge detectors, based on an observation that the localization ambiguity of deep edge detectors is mainly caused by the mixing phenomenon of convolutional neural networks: feature mixing in edge classification and side mixing during fusing side predictions. The CATS consists of two modules: a novel tracing loss that performs feature unmixing by tracing boundaries for better side edge learning, and a context-aware fusion block that tackles the side mixing by aggregating the complementary merits of learned side edges. Experiments demonstrate that the proposed CATS can be integrated into modern deep edge detectors to improve localization accuracy. With the vanilla VGG16 backbone, in terms of BSDS500 dataset, our CATS improves the F-measure (ODS) of the RCF and BDCN deep edge detectors by 12% and 6% respectively when evaluating without using the morphological non-maximal suppression scheme for edge detection.
ELKPPNet: An Edge-aware Neural Network with Large Kernel Pyramid Pooling for Learning Discriminative Features in Semantic Segmentation
Jun 27, 2019
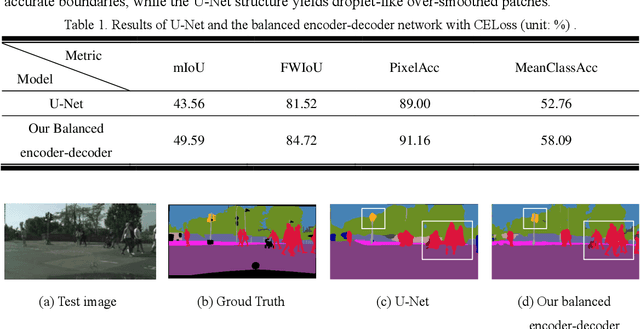
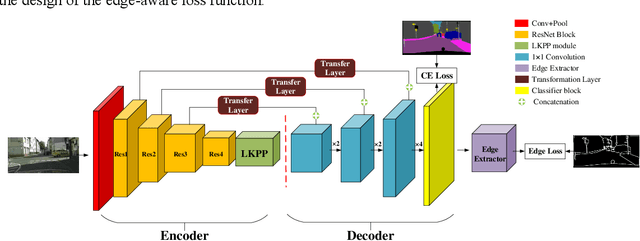
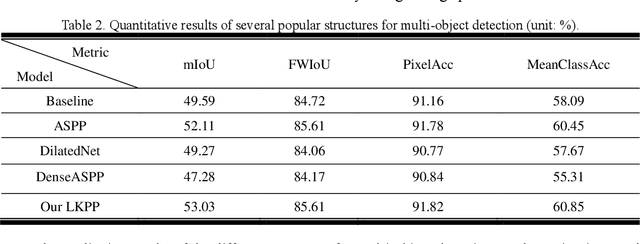
Semantic segmentation has been a hot topic across diverse research fields. Along with the success of deep convolutional neural networks, semantic segmentation has made great achievements and improvements, in terms of both urban scene parsing and indoor semantic segmentation. However, most of the state-of-the-art models are still faced with a challenge in discriminative feature learning, which limits the ability of a model to detect multi-scale objects and to guarantee semantic consistency inside one object or distinguish different adjacent objects with similar appearance. In this paper, a practical and efficient edge-aware neural network is presented for semantic segmentation. This end-to-end trainable engine consists of a new encoder-decoder network, a large kernel spatial pyramid pooling (LKPP) block, and an edge-aware loss function. The encoder-decoder network was designed as a balanced structure to narrow the semantic and resolution gaps in multi-level feature aggregation, while the LKPP block was constructed with a densely expanding receptive field for multi-scale feature extraction and fusion. Furthermore, the new powerful edge-aware loss function is proposed to refine the boundaries directly from the semantic segmentation prediction for more robust and discriminative features. The effectiveness of the proposed model was demonstrated using Cityscapes, CamVid, and NYUDv2 benchmark datasets. The performance of the two structures and the edge-aware loss function in ELKPPNet was validated on the Cityscapes dataset, while the complete ELKPPNet was evaluated on the CamVid and NYUDv2 datasets. A comparative analysis with the state-of-the-art methods under the same conditions confirmed the superiority of the proposed algorithm.