 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAMTok: Representing Any Mask with Two Words
Jan 22, 2026Pixel-wise capabilities are essential for building interactive intelligent systems. However, pixel-wise multi-modal LLMs (MLLMs) remain difficult to scale due to complex region-level encoders, specialized segmentation decoders, and incompatible training objectives. To address these challenges, we present SAMTok, a discrete mask tokenizer that converts any region mask into two special tokens and reconstructs the mask using these tokens with high fidelity. By treating masks as new language tokens, SAMTok enables base MLLMs (such as the QwenVL series) to learn pixel-wise capabilities through standard next-token prediction and simple reinforcement learning, without architectural modifications and specialized loss design. SAMTok builds on SAM2 and is trained on 209M diverse masks using a mask encoder and residual vector quantizer to produce discrete, compact, and information-rich tokens. With 5M SAMTok-formatted mask understanding and generation data samples, QwenVL-SAMTok attains state-of-the-art or comparable results on region captioning, region VQA, grounded conversation, referring segmentation, scene graph parsing, and multi-round interactive segmentation. We further introduce a textual answer-matching reward that enables efficient reinforcement learning for mask generation, delivering substantial improvements on GRES and GCG benchmarks. Our results demonstrate a scalable and straightforward paradigm for equipping MLLMs with strong pixel-wise capabilities. Our code and models are available.
Opt3DGS: Optimizing 3D Gaussian Splatting with Adaptive Exploration and Curvature-Aware Exploitation
Nov 17, 20253D Gaussian Splatting (3DGS) has emerged as a leading framework for novel view synthesis, yet its core optimization challenges remain underexplored. We identify two key issues in 3DGS optimization: entrapment in suboptimal local optima and insufficient convergence quality. To address these, we propose Opt3DGS, a robust framework that enhances 3DGS through a two-stage optimization process of adaptive exploration and curvature-guided exploitation. In the exploration phase, an Adaptive Weighted Stochastic Gradient Langevin Dynamics (SGLD) method enhances global search to escape local optima. In the exploitation phase, a Local Quasi-Newton Direction-guided Adam optimizer leverages curvature information for precise and efficient convergence. Extensive experiments on diverse benchmark datasets demonstrate that Opt3DGS achieves state-of-the-art rendering quality by refining the 3DGS optimization process without modifying its underlying representation.
SIU3R: Simultaneous Scene Understanding and 3D Reconstruction Beyond Feature Alignment
Jul 03, 2025Simultaneous understanding and 3D reconstruction plays an important role in developing end-to-end embodied intelligent systems. To achieve this, recent approaches resort to 2D-to-3D feature alignment paradigm, which leads to limited 3D understanding capability and potential semantic information loss. In light of this, we propose SIU3R, the first alignment-free framework for generalizable simultaneous understanding and 3D reconstruction from unposed images. Specifically, SIU3R bridges reconstruction and understanding tasks via pixel-aligned 3D representation, and unifies multiple understanding tasks into a set of unified learnable queries, enabling native 3D understanding without the need of alignment with 2D models. To encourage collaboration between the two tasks with shared representation, we further conduct in-depth analyses of their mutual benefits, and propose two lightweight modules to facilitate their interaction. Extensive experiments demonstrate that our method achieves state-of-the-art performance not only on the individual tasks of 3D reconstruction and understanding, but also on the task of simultaneous understanding and 3D reconstruction, highlighting the advantages of our alignment-free framework and the effectiveness of the mutual benefit designs.
Dense360: Dense Understanding from Omnidirectional Panoramas
Jun 17, 2025Multimodal Large Language Models (MLLMs) require comprehensive visual inputs to achieve dense understanding of the physical world. While existing MLLMs demonstrate impressive world understanding capabilities through limited field-of-view (FOV) visual inputs (e.g., 70 degree), we take the first step toward dense understanding from omnidirectional panoramas. We first introduce an omnidirectional panoramas dataset featuring a comprehensive suite of reliability-scored annotations. Specifically, our dataset contains 160K panoramas with 5M dense entity-level captions, 1M unique referring expressions, and 100K entity-grounded panoramic scene descriptions. Compared to multi-view alternatives, panoramas can provide more complete, compact, and continuous scene representations through equirectangular projections (ERP). However, the use of ERP introduces two key challenges for MLLMs: i) spatial continuity along the circle of latitude, and ii) latitude-dependent variation in information density. We address these challenges through ERP-RoPE, a position encoding scheme specifically designed for panoramic ERP. In addition, we introduce Dense360-Bench, the first benchmark for evaluating MLLMs on omnidirectional captioning and grounding, establishing a comprehensive framework for advancing dense visual-language understanding in panoramic settings.
Pixel-SAIL: Single Transformer For Pixel-Grounded Understanding
Apr 14, 2025



Multimodal Large Language Models (MLLMs) achieve remarkable performance for fine-grained pixel-level understanding tasks. However, all the works rely heavily on extra components, such as vision encoder (CLIP), segmentation experts, leading to high system complexity and limiting model scaling. In this work, our goal is to explore a highly simplified MLLM without introducing extra components. Our work is motivated by the recent works on Single trAnsformer as a unified vIsion-Language Model (SAIL) design, where these works jointly learn vision tokens and text tokens in transformers. We present Pixel-SAIL, a single transformer for pixel-wise MLLM tasks. In particular, we present three technical improvements on the plain baseline. First, we design a learnable upsampling module to refine visual token features. Secondly, we propose a novel visual prompt injection strategy to enable the single transformer to understand visual prompt inputs and benefit from the early fusion of visual prompt embeddings and vision tokens. Thirdly, we introduce a vision expert distillation strategy to efficiently enhance the single transformer's fine-grained feature extraction capability. In addition, we have collected a comprehensive pixel understanding benchmark (PerBench), using a manual check. It includes three tasks: detailed object description, visual prompt-based question answering, and visual-text referring segmentation. Extensive experiments on four referring segmentation benchmarks, one visual prompt benchmark, and our PerBench show that our Pixel-SAIL achieves comparable or even better results with a much simpler pipeline. Code and model will be released at https://github.com/magic-research/Sa2VA.
Are They the Same? Exploring Visual Correspondence Shortcomings of Multimodal LLMs
Jan 08, 2025
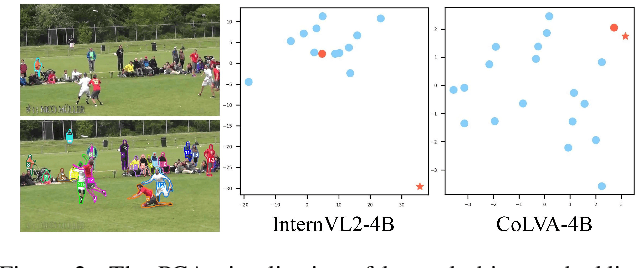


Recent advancements in multimodal models have shown a strong ability in visual perception, reasoning abilities, and vision-language understanding. However, studies on visual matching ability are missing, where finding the visual correspondence of objects is essential in vision research. Our research reveals that the matching capabilities in recent multimodal LLMs (MLLMs) still exhibit systematic shortcomings, even with current strong MLLMs models, GPT-4o. In particular, we construct a Multimodal Visual Matching (MMVM) benchmark to fairly benchmark over 30 different MLLMs. The MMVM benchmark is built from 15 open-source datasets and Internet videos with manual annotation. We categorize the data samples of MMVM benchmark into eight aspects based on the required cues and capabilities to more comprehensively evaluate and analyze current MLLMs. In addition, we have designed an automatic annotation pipeline to generate the MMVM SFT dataset, including 220K visual matching data with reasoning annotation. Finally, we present CoLVA, a novel contrastive MLLM with two novel technical designs: fine-grained vision expert with object-level contrastive learning and instruction augmentation strategy. CoLVA achieves 51.06\% overall accuracy (OA) on the MMVM benchmark, surpassing GPT-4o and baseline by 8.41\% and 23.58\% OA, respectively. The results show the effectiveness of our MMVM SFT dataset and our novel technical designs. Code, benchmark, dataset, and models are available at https://github.com/zhouyiks/CoLVA.
Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos
Jan 07, 2025



This work presents Sa2VA, the first unified model for dense grounded understanding of both images and videos. Unlike existing multi-modal large language models, which are often limited to specific modalities and tasks, Sa2VA supports a wide range of image and video tasks, including referring segmentation and conversation, with minimal one-shot instruction tuning. Sa2VA combines SAM-2, a foundation video segmentation model, with LLaVA, an advanced vision-language model, and unifies text, image, and video into a shared LLM token space. Using the LLM, Sa2VA generates instruction tokens that guide SAM-2 in producing precise masks, enabling a grounded, multi-modal understanding of both static and dynamic visual content. Additionally, we introduce Ref-SAV, an auto-labeled dataset containing over 72k object expressions in complex video scenes, designed to boost model performance. We also manually validate 2k video objects in the Ref-SAV datasets to benchmark referring video object segmentation in complex environments. Experiments show that Sa2VA achieves state-of-the-art across multiple tasks, particularly in referring video object segmentation, highlighting its potential for complex real-world applications.
A Novel Shape Guided Transformer Network for Instance Segmentation in Remote Sensing Images
Dec 31, 2024



Instance segmentation performance in remote sensing images (RSIs) is significantly affected by two issues: how to extract accurate boundaries of objects from remote imaging through the dynamic atmosphere, and how to integrate the mutual information of related object instances scattered over a vast spatial region. In this study, we propose a novel Shape Guided Transformer Network (SGTN) to accurately extract objects at the instance level. Inspired by the global contextual modeling capacity of the self-attention mechanism, we propose an effective transformer encoder termed LSwin, which incorporates vertical and horizontal 1D global self-attention mechanisms to obtain better global-perception capacity for RSIs than the popular local-shifted-window based Swin Transformer. To achieve accurate instance mask segmentation, we introduce a shape guidance module (SGM) to emphasize the object boundary and shape information. The combination of SGM, which emphasizes the local detail information, and LSwin, which focuses on the global context relationships, achieve excellent RSI instance segmentation. Their effectiveness was validated through comprehensive ablation experiments. Especially, LSwin is proved better than the popular ResNet and Swin transformer encoder at the same level of efficiency. Compared to other instance segmentation methods, our SGTN achieves the highest average precision (AP) scores on two single-class public datasets (WHU dataset and BITCC dataset) and a multi-class public dataset (NWPU VHR-10 dataset). Code will be available at http://gpcv.whu.edu.cn/data/.
Online Temporal Fusion for Vectorized Map Construction in Mapless Autonomous Driving
Sep 01, 2024To reduce the reliance on high-definition (HD) maps, a growing trend in autonomous driving is leveraging on-board sensors to generate vectorized maps online. However, current methods are mostly constrained by processing only single-frame inputs, which hampers their robustness and effectiveness in complex scenarios. To overcome this problem, we propose an online map construction system that exploits the long-term temporal information to build a consistent vectorized map. First, the system efficiently fuses all historical road marking detections from an off-the-shelf network into a semantic voxel map, which is implemented using a hashing-based strategy to exploit the sparsity of road elements. Then reliable voxels are found by examining the fused information and incrementally clustered into an instance-level representation of road markings. Finally, the system incorporates domain knowledge to estimate the geometric and topological structures of roads, which can be directly consumed by the planning and control (PnC) module. Through experiments conducted in complicated urban environments, we have demonstrated that the output of our system is more consistent and accurate than the network output by a large margin and can be effectively used in a closed-loop autonomous driving system.
3D Gaussian Splatting for Large-scale 3D Surface Reconstruction from Aerial Images
Aug 31, 2024



Recently, 3D Gaussian Splatting (3DGS) has garnered significant attention. However, the unstructured nature of 3DGS poses challenges for large-scale surface reconstruction from aerial images. To address this gap, we propose the first large-scale surface reconstruction method for multi-view stereo (MVS) aerial images based on 3DGS, named Aerial Gaussian Splatting (AGS). Initially, we introduce a data chunking method tailored for large-scale aerial imagery, making the modern 3DGS technology feasible for surface reconstruction over extensive scenes. Additionally, we integrate the Ray-Gaussian Intersection method to obtain normal and depth information, facilitating geometric constraints. Finally, we introduce a multi-view geometric consistency constraint to enhance global geometric consistency and improve reconstruction accuracy. Our experiments on multiple datasets demonstrate for the first time that the GS-based technique can match traditional aerial MVS methods on geometric accuracy, and beat state-of-the-art GS-based methods on geometry and rendering quality.