 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld Action Models: The Next Frontier in Embodied AI
May 12, 2026Vision-Language-Action (VLA) models have achieved strong semantic generalization for embodied policy learning, yet they learn reactive observation-to-action mappings without explicitly modeling how the physical world evolves under intervention. A growing body of work addresses this limitation by integrating world models, predictive models of environment dynamics, into the action generation pipeline. We term this emerging paradigm World Action Models (WAMs): embodied foundation models that unify predictive state modeling with action generation, targeting a joint distribution over future states and actions rather than actions alone. However, the literature remains fragmented across architectures, learning objectives, and application scenarios, lacking a unified conceptual framework. We formally define WAMs and disambiguate them from related concepts, and trace the foundations and early integration of VLA and world model research that gave rise to this paradigm. We organize existing methods into a structured taxonomy of Cascaded and Joint WAMs, with further subdivision by generation modality, conditioning mechanism, and action decoding strategy. We systematically analyze the data ecosystem fueling WAMs development, spanning robot teleoperation, portable human demonstrations, simulation, and internet-scale egocentric video, and synthesize emerging evaluation protocols organized around visual fidelity, physical commonsense, and action plausibility. Overall, this survey provides the first systematic account of the WAMs landscape, clarifies key architectural paradigms and their trade-offs, and identifies open challenges and future opportunities for this rapidly evolving field.
SaSaSaSa2VA: 2nd Place of the 5th PVUW MeViS-Text Track
Mar 28, 2026Referring video object segmentation (RVOS) commonly grounds targets in videos based on static textual cues. MeViS benchmark extends this by incorporating motion-centric expressions (referring & reasoning motion expressions) and introducing no-target queries. Extending SaSaSa2VA, where increased input frames and [SEG] tokens already strengthen the Sa2VA backbone, we adopt a simple yet effective target existence-aware verification mechanism, leading to Still Awesome SaSaSa2VA (SaSaSaSa2VA). Despite its simplicity, the method achieves a final score of 89.19 in the 5th PVUW Challenge (MeViS-Text Track), securing 2nd place. Both quantitative results and ablations suggest that this existence-aware verification strategy is sufficient to unlock strong performance on motion-centric referring tasks.
SAMTok: Representing Any Mask with Two Words
Jan 22, 2026Pixel-wise capabilities are essential for building interactive intelligent systems. However, pixel-wise multi-modal LLMs (MLLMs) remain difficult to scale due to complex region-level encoders, specialized segmentation decoders, and incompatible training objectives. To address these challenges, we present SAMTok, a discrete mask tokenizer that converts any region mask into two special tokens and reconstructs the mask using these tokens with high fidelity. By treating masks as new language tokens, SAMTok enables base MLLMs (such as the QwenVL series) to learn pixel-wise capabilities through standard next-token prediction and simple reinforcement learning, without architectural modifications and specialized loss design. SAMTok builds on SAM2 and is trained on 209M diverse masks using a mask encoder and residual vector quantizer to produce discrete, compact, and information-rich tokens. With 5M SAMTok-formatted mask understanding and generation data samples, QwenVL-SAMTok attains state-of-the-art or comparable results on region captioning, region VQA, grounded conversation, referring segmentation, scene graph parsing, and multi-round interactive segmentation. We further introduce a textual answer-matching reward that enables efficient reinforcement learning for mask generation, delivering substantial improvements on GRES and GCG benchmarks. Our results demonstrate a scalable and straightforward paradigm for equipping MLLMs with strong pixel-wise capabilities. Our code and models are available.
Grasp Any Region: Towards Precise, Contextual Pixel Understanding for Multimodal LLMs
Oct 22, 2025While Multimodal Large Language Models (MLLMs) excel at holistic understanding, they struggle in capturing the dense world with complex scenes, requiring fine-grained analysis of intricate details and object inter-relationships. Region-level MLLMs have been a promising step. However, previous attempts are generally optimized to understand given regions in isolation, neglecting crucial global contexts. To address this, we introduce Grasp Any Region (GAR) for comprehen- sive region-level visual understanding. Empowered by an effective RoI-aligned feature replay technique, GAR supports (1) precise perception by leveraging necessary global contexts, and (2) modeling interactions between multiple prompts. Together, it then naturally achieves (3) advanced compositional reasoning to answer specific free-form questions about any region, shifting the paradigm from passive description to active dialogue. Moreover, we construct GAR-Bench, which not only provides a more accurate evaluation of single-region comprehension, but also, more importantly, measures interactions and complex reasoning across multiple regions. Extensive experiments have demonstrated that GAR-1B not only maintains the state-of-the-art captioning capabilities, e.g., outperforming DAM-3B +4.5 on DLC-Bench, but also excels at modeling relationships between multiple prompts with advanced comprehension capabilities, even surpassing InternVL3-78B on GAR-Bench-VQA. More importantly, our zero-shot GAR-8B even outperforms in-domain VideoRefer-7B on VideoRefer-BenchQ, indicating its strong capabilities can be easily transferred to videos.
Dense360: Dense Understanding from Omnidirectional Panoramas
Jun 17, 2025Multimodal Large Language Models (MLLMs) require comprehensive visual inputs to achieve dense understanding of the physical world. While existing MLLMs demonstrate impressive world understanding capabilities through limited field-of-view (FOV) visual inputs (e.g., 70 degree), we take the first step toward dense understanding from omnidirectional panoramas. We first introduce an omnidirectional panoramas dataset featuring a comprehensive suite of reliability-scored annotations. Specifically, our dataset contains 160K panoramas with 5M dense entity-level captions, 1M unique referring expressions, and 100K entity-grounded panoramic scene descriptions. Compared to multi-view alternatives, panoramas can provide more complete, compact, and continuous scene representations through equirectangular projections (ERP). However, the use of ERP introduces two key challenges for MLLMs: i) spatial continuity along the circle of latitude, and ii) latitude-dependent variation in information density. We address these challenges through ERP-RoPE, a position encoding scheme specifically designed for panoramic ERP. In addition, we introduce Dense360-Bench, the first benchmark for evaluating MLLMs on omnidirectional captioning and grounding, establishing a comprehensive framework for advancing dense visual-language understanding in panoramic settings.
An Empirical Study of GPT-4o Image Generation Capabilities
Apr 08, 2025



The landscape of image generation has rapidly evolved, from early GAN-based approaches to diffusion models and, most recently, to unified generative architectures that seek to bridge understanding and generation tasks. Recent advances, especially the GPT-4o, have demonstrated the feasibility of high-fidelity multimodal generation, their architectural design remains mysterious and unpublished. This prompts the question of whether image and text generation have already been successfully integrated into a unified framework for those methods. In this work, we conduct an empirical study of GPT-4o's image generation capabilities, benchmarking it against leading open-source and commercial models. Our evaluation covers four main categories, including text-to-image, image-to-image, image-to-3D, and image-to-X generation, with more than 20 tasks. Our analysis highlights the strengths and limitations of GPT-4o under various settings, and situates it within the broader evolution of generative modeling. Through this investigation, we identify promising directions for future unified generative models, emphasizing the role of architectural design and data scaling.
Are They the Same? Exploring Visual Correspondence Shortcomings of Multimodal LLMs
Jan 08, 2025
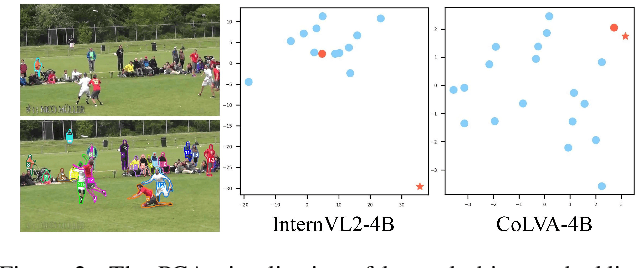


Recent advancements in multimodal models have shown a strong ability in visual perception, reasoning abilities, and vision-language understanding. However, studies on visual matching ability are missing, where finding the visual correspondence of objects is essential in vision research. Our research reveals that the matching capabilities in recent multimodal LLMs (MLLMs) still exhibit systematic shortcomings, even with current strong MLLMs models, GPT-4o. In particular, we construct a Multimodal Visual Matching (MMVM) benchmark to fairly benchmark over 30 different MLLMs. The MMVM benchmark is built from 15 open-source datasets and Internet videos with manual annotation. We categorize the data samples of MMVM benchmark into eight aspects based on the required cues and capabilities to more comprehensively evaluate and analyze current MLLMs. In addition, we have designed an automatic annotation pipeline to generate the MMVM SFT dataset, including 220K visual matching data with reasoning annotation. Finally, we present CoLVA, a novel contrastive MLLM with two novel technical designs: fine-grained vision expert with object-level contrastive learning and instruction augmentation strategy. CoLVA achieves 51.06\% overall accuracy (OA) on the MMVM benchmark, surpassing GPT-4o and baseline by 8.41\% and 23.58\% OA, respectively. The results show the effectiveness of our MMVM SFT dataset and our novel technical designs. Code, benchmark, dataset, and models are available at https://github.com/zhouyiks/CoLVA.
P2PFormer: A Primitive-to-polygon Method for Regular Building Contour Extraction from Remote Sensing Images
Jun 05, 2024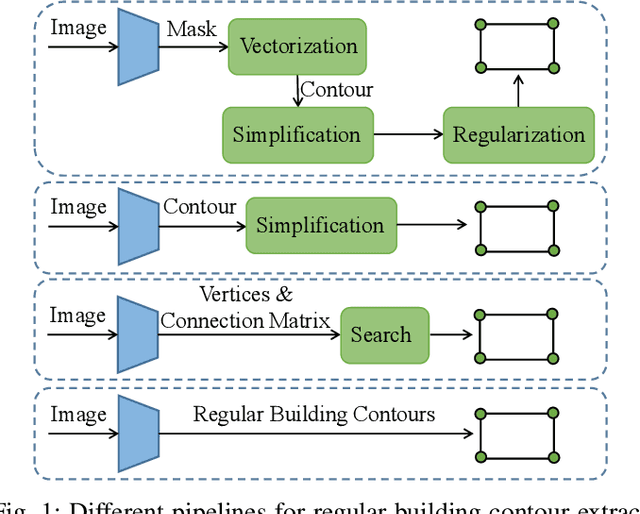



Extracting building contours from remote sensing imagery is a significant challenge due to buildings' complex and diverse shapes, occlusions, and noise. Existing methods often struggle with irregular contours, rounded corners, and redundancy points, necessitating extensive post-processing to produce regular polygonal building contours. To address these challenges, we introduce a novel, streamlined pipeline that generates regular building contours without post-processing. Our approach begins with the segmentation of generic geometric primitives (which can include vertices, lines, and corners), followed by the prediction of their sequence. This allows for the direct construction of regular building contours by sequentially connecting the segmented primitives. Building on this pipeline, we developed P2PFormer, which utilizes a transformer-based architecture to segment geometric primitives and predict their order. To enhance the segmentation of primitives, we introduce a unique representation called group queries. This representation comprises a set of queries and a singular query position, which improve the focus on multiple midpoints of primitives and their efficient linkage. Furthermore, we propose an innovative implicit update strategy for the query position embedding aimed at sharpening the focus of queries on the correct positions and, consequently, enhancing the quality of primitive segmentation. Our experiments demonstrate that P2PFormer achieves new state-of-the-art performance on the WHU, CrowdAI, and WHU-Mix datasets, surpassing the previous SOTA PolyWorld by a margin of 2.7 AP and 6.5 AP75 on the largest CrowdAI dataset. We intend to make the code and trained weights publicly available to promote their use and facilitate further research.
DVIS-DAQ: Improving Video Segmentation via Dynamic Anchor Queries
Apr 05, 2024Modern video segmentation methods adopt object queries to perform inter-frame association and demonstrate satisfactory performance in tracking continuously appearing objects despite large-scale motion and transient occlusion. However, they all underperform on newly emerging and disappearing objects that are common in the real world because they attempt to model object emergence and disappearance through feature transitions between background and foreground queries that have significant feature gaps. We introduce Dynamic Anchor Queries (DAQ) to shorten the transition gap between the anchor and target queries by dynamically generating anchor queries based on the features of potential candidates. Furthermore, we introduce a query-level object Emergence and Disappearance Simulation (EDS) strategy, which unleashes DAQ's potential without any additional cost. Finally, we combine our proposed DAQ and EDS with DVIS to obtain DVIS-DAQ. Extensive experiments demonstrate that DVIS-DAQ achieves a new state-of-the-art (SOTA) performance on five mainstream video segmentation benchmarks. Code and models are available at \url{https://github.com/SkyworkAI/DAQ-VS}.
DVIS++: Improved Decoupled Framework for Universal Video Segmentation
Dec 20, 2023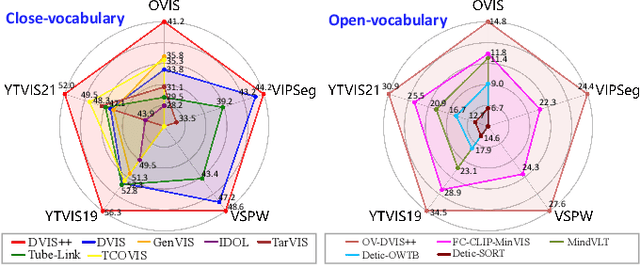
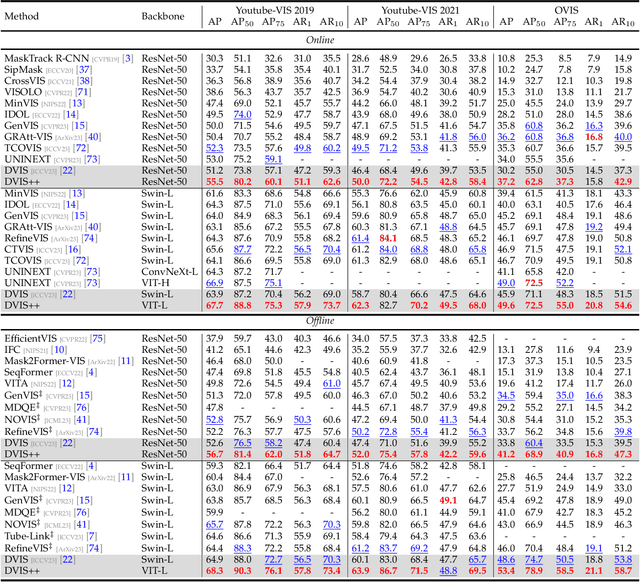
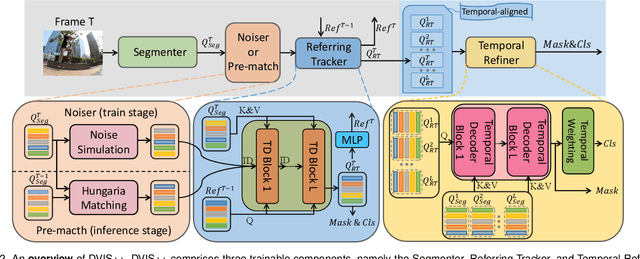
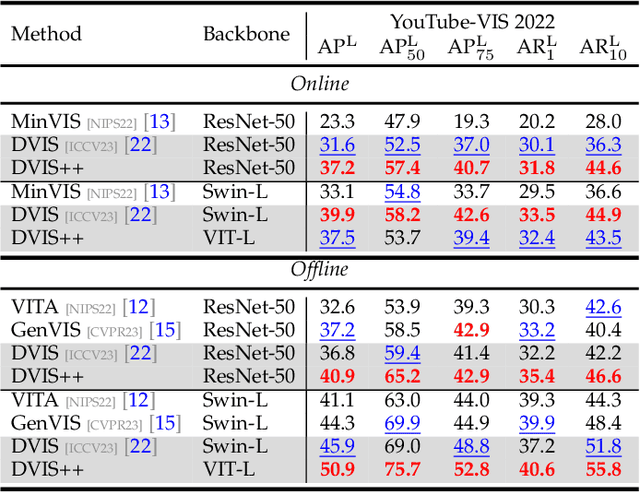
We present the \textbf{D}ecoupled \textbf{VI}deo \textbf{S}egmentation (DVIS) framework, a novel approach for the challenging task of universal video segmentation, including video instance segmentation (VIS), video semantic segmentation (VSS), and video panoptic segmentation (VPS). Unlike previous methods that model video segmentation in an end-to-end manner, our approach decouples video segmentation into three cascaded sub-tasks: segmentation, tracking, and refinement. This decoupling design allows for simpler and more effective modeling of the spatio-temporal representations of objects, especially in complex scenes and long videos. Accordingly, we introduce two novel components: the referring tracker and the temporal refiner. These components track objects frame by frame and model spatio-temporal representations based on pre-aligned features. To improve the tracking capability of DVIS, we propose a denoising training strategy and introduce contrastive learning, resulting in a more robust framework named DVIS++. Furthermore, we evaluate DVIS++ in various settings, including open vocabulary and using a frozen pre-trained backbone. By integrating CLIP with DVIS++, we present OV-DVIS++, the first open-vocabulary universal video segmentation framework. We conduct extensive experiments on six mainstream benchmarks, including the VIS, VSS, and VPS datasets. Using a unified architecture, DVIS++ significantly outperforms state-of-the-art specialized methods on these benchmarks in both close- and open-vocabulary settings. Code:~\url{https://github.com/zhang-tao-whu/DVIS_Plus}.