 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoomVideo: Unifying Multimodal Inputs into Video Generation and Editing
Jun 04, 2026Developing unified video generation and editing models capable of interpreting interleaved multimodal inputs is a promising yet challenging frontier field. Existing unified frameworks predominantly rely on massive models (typically 13B parameters or more) and incorporate source video conditions for editing by concatenating sequence tokens. This concatenation inevitably doubles the sequence length, quadrupling the computational complexity of the self-attention mechanism and introducing prohibitive overhead. To address these bottlenecks, we present LoomVideo, a highly efficient 5B-parameter unified architecture for both video generation and editing. LoomVideo replaces the standard text encoder with a Multimodal Large Language Model (MLLM) and employs Deepstack injection mechanism to align multi-layer MLLM features with the Diffusion Transformer (DiT). Crucially, we introduce a zero-overhead Scale-and-Add conditioning approach for video editing. By scaling and directly adding the clean source video latent to the noised target latent, this elegant design eliminates the need for token concatenation, drastically reducing computational cost while maintaining robust capabilities for complex, non-rigid edits. Furthermore, a Negative Temporal RoPE strategy is seamlessly integrated to handle multiple reference images. Extensive experiments demonstrate that our compact 5B model achieves state-of-the-art or highly competitive performance across comprehensive benchmarks, exhibiting exceptional superiority in e-commerce and fashion generation scenarios. Benefiting from the zero-overhead conditioning mechanism, LoomVideo achieves at least a 5.41x acceleration in inference speed compared to models of similar capabilities, paving the way for highly practical and efficient video foundation models.
Muddit: Liberating Generation Beyond Text-to-Image with a Unified Discrete Diffusion Model
May 29, 2025Unified generation models aim to handle diverse tasks across modalities -- such as text generation, image generation, and vision-language reasoning -- within a single architecture and decoding paradigm. Autoregressive unified models suffer from slow inference due to sequential decoding, and non-autoregressive unified models suffer from weak generalization due to limited pretrained backbones. We introduce Muddit, a unified discrete diffusion transformer that enables fast and parallel generation across both text and image modalities. Unlike prior unified diffusion models trained from scratch, Muddit integrates strong visual priors from a pretrained text-to-image backbone with a lightweight text decoder, enabling flexible and high-quality multimodal generation under a unified architecture. Empirical results show that Muddit achieves competitive or superior performance compared to significantly larger autoregressive models in both quality and efficiency. The work highlights the potential of purely discrete diffusion, when equipped with strong visual priors, as a scalable and effective backbone for unified generation.
An Empirical Study of GPT-4o Image Generation Capabilities
Apr 08, 2025



The landscape of image generation has rapidly evolved, from early GAN-based approaches to diffusion models and, most recently, to unified generative architectures that seek to bridge understanding and generation tasks. Recent advances, especially the GPT-4o, have demonstrated the feasibility of high-fidelity multimodal generation, their architectural design remains mysterious and unpublished. This prompts the question of whether image and text generation have already been successfully integrated into a unified framework for those methods. In this work, we conduct an empirical study of GPT-4o's image generation capabilities, benchmarking it against leading open-source and commercial models. Our evaluation covers four main categories, including text-to-image, image-to-image, image-to-3D, and image-to-X generation, with more than 20 tasks. Our analysis highlights the strengths and limitations of GPT-4o under various settings, and situates it within the broader evolution of generative modeling. Through this investigation, we identify promising directions for future unified generative models, emphasizing the role of architectural design and data scaling.
Decouple and Track: Benchmarking and Improving Video Diffusion Transformers for Motion Transfer
Mar 21, 2025The motion transfer task involves transferring motion from a source video to newly generated videos, requiring the model to decouple motion from appearance. Previous diffusion-based methods primarily rely on separate spatial and temporal attention mechanisms within 3D U-Net. In contrast, state-of-the-art video Diffusion Transformers (DiT) models use 3D full attention, which does not explicitly separate temporal and spatial information. Thus, the interaction between spatial and temporal dimensions makes decoupling motion and appearance more challenging for DiT models. In this paper, we propose DeT, a method that adapts DiT models to improve motion transfer ability. Our approach introduces a simple yet effective temporal kernel to smooth DiT features along the temporal dimension, facilitating the decoupling of foreground motion from background appearance. Meanwhile, the temporal kernel effectively captures temporal variations in DiT features, which are closely related to motion. Moreover, we introduce explicit supervision along dense trajectories in the latent feature space to further enhance motion consistency. Additionally, we present MTBench, a general and challenging benchmark for motion transfer. We also introduce a hybrid motion fidelity metric that considers both the global and local motion similarity. Therefore, our work provides a more comprehensive evaluation than previous works. Extensive experiments on MTBench demonstrate that DeT achieves the best trade-off between motion fidelity and edit fidelity.
DiffSensei: Bridging Multi-Modal LLMs and Diffusion Models for Customized Manga Generation
Dec 10, 2024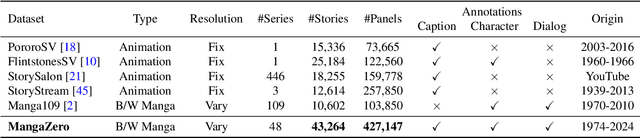

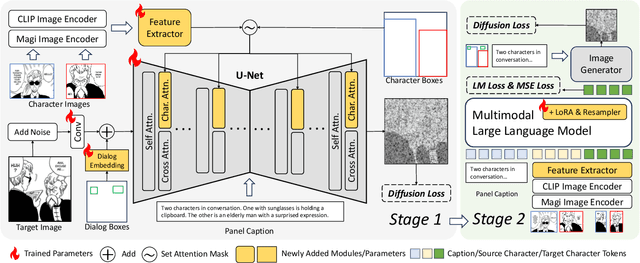
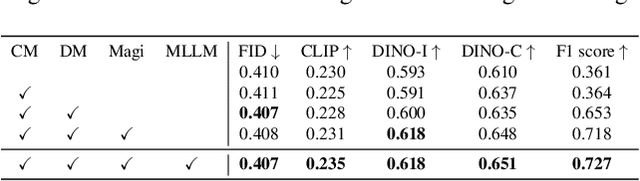
Story visualization, the task of creating visual narratives from textual descriptions, has seen progress with text-to-image generation models. However, these models often lack effective control over character appearances and interactions, particularly in multi-character scenes. To address these limitations, we propose a new task: \textbf{customized manga generation} and introduce \textbf{DiffSensei}, an innovative framework specifically designed for generating manga with dynamic multi-character control. DiffSensei integrates a diffusion-based image generator with a multimodal large language model (MLLM) that acts as a text-compatible identity adapter. Our approach employs masked cross-attention to seamlessly incorporate character features, enabling precise layout control without direct pixel transfer. Additionally, the MLLM-based adapter adjusts character features to align with panel-specific text cues, allowing flexible adjustments in character expressions, poses, and actions. We also introduce \textbf{MangaZero}, a large-scale dataset tailored to this task, containing 43,264 manga pages and 427,147 annotated panels, supporting the visualization of varied character interactions and movements across sequential frames. Extensive experiments demonstrate that DiffSensei outperforms existing models, marking a significant advancement in manga generation by enabling text-adaptable character customization. The project page is https://jianzongwu.github.io/projects/diffsensei/.
RelationBooth: Towards Relation-Aware Customized Object Generation
Oct 30, 2024



Customized image generation is crucial for delivering personalized content based on user-provided image prompts, aligning large-scale text-to-image diffusion models with individual needs. However, existing models often overlook the relationships between customized objects in generated images. Instead, this work addresses that gap by focusing on relation-aware customized image generation, which aims to preserve the identities from image prompts while maintaining the predicate relations described in text prompts. Specifically, we introduce RelationBooth, a framework that disentangles identity and relation learning through a well-curated dataset. Our training data consists of relation-specific images, independent object images containing identity information, and text prompts to guide relation generation. Then, we propose two key modules to tackle the two main challenges: generating accurate and natural relations, especially when significant pose adjustments are required, and avoiding object confusion in cases of overlap. First, we introduce a keypoint matching loss that effectively guides the model in adjusting object poses closely tied to their relationships. Second, we incorporate local features from the image prompts to better distinguish between objects, preventing confusion in overlapping cases. Extensive results on three benchmarks demonstrate the superiority of RelationBooth in generating precise relations while preserving object identities across a diverse set of objects and relations. The source code and trained models will be made available to the public.
Auto Cherry-Picker: Learning from High-quality Generative Data Driven by Language
Jun 28, 2024



Diffusion-based models have shown great potential in generating high-quality images with various layouts, which can benefit downstream perception tasks. However, a fully automatic layout generation driven only by language and a suitable metric for measuring multiple generated instances has not been well explored. In this work, we present Auto Cherry-Picker (ACP), a novel framework that generates high-quality multi-modal training examples to augment perception and multi-modal training. Starting with a simple list of natural language concepts, we prompt large language models (LLMs) to generate a detailed description and design reasonable layouts. Next, we use an off-the-shelf text-to-image model to generate multiple images. Then, the generated data are refined using a comprehensively designed metric to ensure quality. In particular, we present a new metric, Composite Layout and Image Score (CLIS), to evaluate the generated images fairly. Our synthetic high-quality examples boost performance in various scenarios by customizing the initial concept list, especially in addressing challenges associated with long-tailed distribution and imbalanced datasets. Experiment results on downstream tasks demonstrate that Auto Cherry-Picker can significantly improve the performance of existing models. In addition, we have thoroughly investigated the correlation between CLIS and performance gains in downstream tasks, and we find that a better CLIS score results in better performance. This finding shows the potential for evaluation metrics as the role for various visual perception and MLLM tasks. Code will be available.
MotionBooth: Motion-Aware Customized Text-to-Video Generation
Jun 25, 2024In this work, we present MotionBooth, an innovative framework designed for animating customized subjects with precise control over both object and camera movements. By leveraging a few images of a specific object, we efficiently fine-tune a text-to-video model to capture the object's shape and attributes accurately. Our approach presents subject region loss and video preservation loss to enhance the subject's learning performance, along with a subject token cross-attention loss to integrate the customized subject with motion control signals. Additionally, we propose training-free techniques for managing subject and camera motions during inference. In particular, we utilize cross-attention map manipulation to govern subject motion and introduce a novel latent shift module for camera movement control as well. MotionBooth excels in preserving the appearance of subjects while simultaneously controlling the motions in generated videos. Extensive quantitative and qualitative evaluations demonstrate the superiority and effectiveness of our method. Our project page is at https://jianzongwu.github.io/projects/motionbooth
Towards Language-Driven Video Inpainting via Multimodal Large Language Models
Jan 18, 2024



We introduce a new task -- language-driven video inpainting, which uses natural language instructions to guide the inpainting process. This approach overcomes the limitations of traditional video inpainting methods that depend on manually labeled binary masks, a process often tedious and labor-intensive. We present the Remove Objects from Videos by Instructions (ROVI) dataset, containing 5,650 videos and 9,091 inpainting results, to support training and evaluation for this task. We also propose a novel diffusion-based language-driven video inpainting framework, the first end-to-end baseline for this task, integrating Multimodal Large Language Models to understand and execute complex language-based inpainting requests effectively. Our comprehensive results showcase the dataset's versatility and the model's effectiveness in various language-instructed inpainting scenarios. We will make datasets, code, and models publicly available.
Towards Open Vocabulary Learning: A Survey
Jul 06, 2023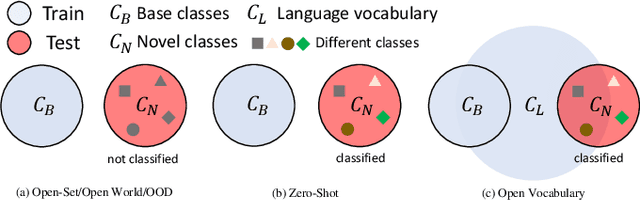
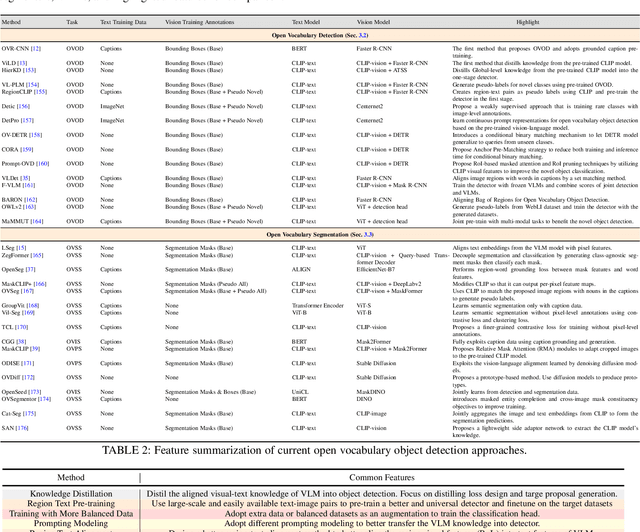
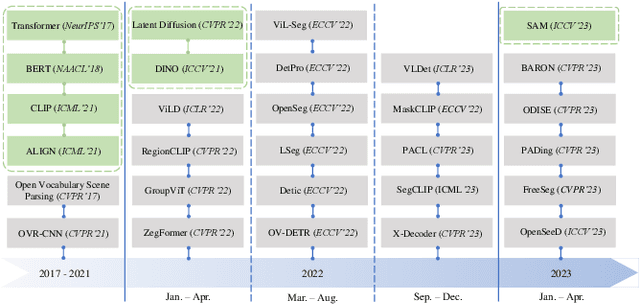

In the field of visual scene understanding, deep neural networks have made impressive advancements in various core tasks like segmentation, tracking, and detection. However, most approaches operate on the close-set assumption, meaning that the model can only identify pre-defined categories that are present in the training set. Recently, open vocabulary settings were proposed due to the rapid progress of vision language pre-training. These new approaches seek to locate and recognize categories beyond the annotated label space. The open vocabulary approach is more general, practical, and effective compared to weakly supervised and zero-shot settings. This paper provides a thorough review of open vocabulary learning, summarizing and analyzing recent developments in the field. In particular, we begin by comparing it to related concepts such as zero-shot learning, open-set recognition, and out-of-distribution detection. Then, we review several closely related tasks in the case of segmentation and detection, including long-tail problems, few-shot, and zero-shot settings. For the method survey, we first present the basic knowledge of detection and segmentation in close-set as the preliminary knowledge. Next, we examine various scenarios in which open vocabulary learning is used, identifying common design elements and core ideas. Then, we compare the recent detection and segmentation approaches in commonly used datasets and benchmarks. Finally, we conclude with insights, issues, and discussions regarding future research directions. To our knowledge, this is the first comprehensive literature review of open vocabulary learning. We keep tracing related works at https://github.com/jianzongwu/Awesome-Open-Vocabulary.