 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKling-Omni Technical Report
Dec 18, 2025



We present Kling-Omni, a generalist generative framework designed to synthesize high-fidelity videos directly from multimodal visual language inputs. Adopting an end-to-end perspective, Kling-Omni bridges the functional separation among diverse video generation, editing, and intelligent reasoning tasks, integrating them into a holistic system. Unlike disjointed pipeline approaches, Kling-Omni supports a diverse range of user inputs, including text instructions, reference images, and video contexts, processing them into a unified multimodal representation to deliver cinematic-quality and highly-intelligent video content creation. To support these capabilities, we constructed a comprehensive data system that serves as the foundation for multimodal video creation. The framework is further empowered by efficient large-scale pre-training strategies and infrastructure optimizations for inference. Comprehensive evaluations reveal that Kling-Omni demonstrates exceptional capabilities in in-context generation, reasoning-based editing, and multimodal instruction following. Moving beyond a content creation tool, we believe Kling-Omni is a pivotal advancement toward multimodal world simulators capable of perceiving, reasoning, generating and interacting with the dynamic and complex worlds.
KlingAvatar 2.0 Technical Report
Dec 15, 2025Avatar video generation models have achieved remarkable progress in recent years. However, prior work exhibits limited efficiency in generating long-duration high-resolution videos, suffering from temporal drifting, quality degradation, and weak prompt following as video length increases. To address these challenges, we propose KlingAvatar 2.0, a spatio-temporal cascade framework that performs upscaling in both spatial resolution and temporal dimension. The framework first generates low-resolution blueprint video keyframes that capture global semantics and motion, and then refines them into high-resolution, temporally coherent sub-clips using a first-last frame strategy, while retaining smooth temporal transitions in long-form videos. To enhance cross-modal instruction fusion and alignment in extended videos, we introduce a Co-Reasoning Director composed of three modality-specific large language model (LLM) experts. These experts reason about modality priorities and infer underlying user intent, converting inputs into detailed storylines through multi-turn dialogue. A Negative Director further refines negative prompts to improve instruction alignment. Building on these components, we extend the framework to support ID-specific multi-character control. Extensive experiments demonstrate that our model effectively addresses the challenges of efficient, multimodally aligned long-form high-resolution video generation, delivering enhanced visual clarity, realistic lip-teeth rendering with accurate lip synchronization, strong identity preservation, and coherent multimodal instruction following.
Denoising Vision Transformer Autoencoder with Spectral Self-Regularization
Nov 16, 2025Variational autoencoders (VAEs) typically encode images into a compact latent space, reducing computational cost but introducing an optimization dilemma: a higher-dimensional latent space improves reconstruction fidelity but often hampers generative performance. Recent methods attempt to address this dilemma by regularizing high-dimensional latent spaces using external vision foundation models (VFMs). However, it remains unclear how high-dimensional VAE latents affect the optimization of generative models. To our knowledge, our analysis is the first to reveal that redundant high-frequency components in high-dimensional latent spaces hinder the training convergence of diffusion models and, consequently, degrade generation quality. To alleviate this problem, we propose a spectral self-regularization strategy to suppress redundant high-frequency noise while simultaneously preserving reconstruction quality. The resulting Denoising-VAE, a ViT-based autoencoder that does not rely on VFMs, produces cleaner, lower-noise latents, leading to improved generative quality and faster optimization convergence. We further introduce a spectral alignment strategy to facilitate the optimization of Denoising-VAE-based generative models. Our complete method enables diffusion models to converge approximately 2$\times$ faster than with SD-VAE, while achieving state-of-the-art reconstruction quality (rFID = 0.28, PSNR = 27.26) and competitive generation performance (gFID = 1.82) on the ImageNet 256$\times$256 benchmark.
VFRTok: Variable Frame Rates Video Tokenizer with Duration-Proportional Information Assumption
May 17, 2025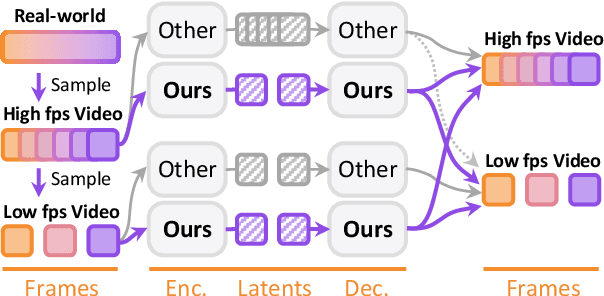
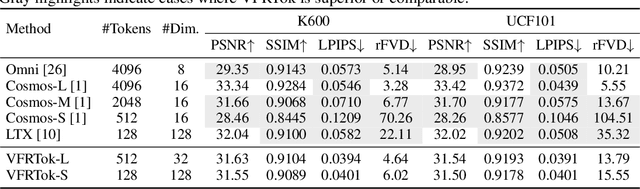
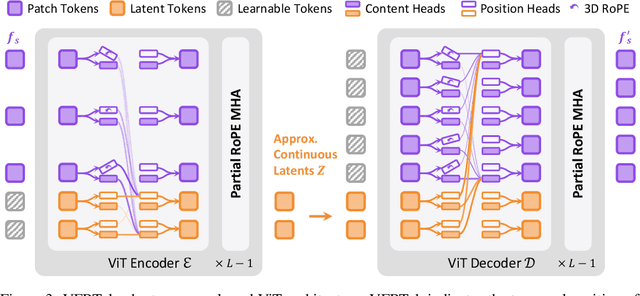
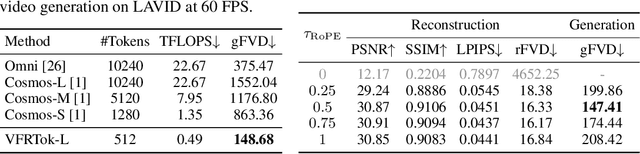
Modern video generation frameworks based on Latent Diffusion Models suffer from inefficiencies in tokenization due to the Frame-Proportional Information Assumption. Existing tokenizers provide fixed temporal compression rates, causing the computational cost of the diffusion model to scale linearly with the frame rate. The paper proposes the Duration-Proportional Information Assumption: the upper bound on the information capacity of a video is proportional to the duration rather than the number of frames. Based on this insight, the paper introduces VFRTok, a Transformer-based video tokenizer, that enables variable frame rate encoding and decoding through asymmetric frame rate training between the encoder and decoder. Furthermore, the paper proposes Partial Rotary Position Embeddings (RoPE) to decouple position and content modeling, which groups correlated patches into unified tokens. The Partial RoPE effectively improves content-awareness, enhancing the video generation capability. Benefiting from the compact and continuous spatio-temporal representation, VFRTok achieves competitive reconstruction quality and state-of-the-art generation fidelity while using only 1/8 tokens compared to existing tokenizers.
VIVID-10M: A Dataset and Baseline for Versatile and Interactive Video Local Editing
Nov 22, 2024



Diffusion-based image editing models have made remarkable progress in recent years. However, achieving high-quality video editing remains a significant challenge. One major hurdle is the absence of open-source, large-scale video editing datasets based on real-world data, as constructing such datasets is both time-consuming and costly. Moreover, video data requires a significantly larger number of tokens for representation, which substantially increases the training costs for video editing models. Lastly, current video editing models offer limited interactivity, often making it difficult for users to express their editing requirements effectively in a single attempt. To address these challenges, this paper introduces a dataset VIVID-10M and a baseline model VIVID. VIVID-10M is the first large-scale hybrid image-video local editing dataset aimed at reducing data construction and model training costs, which comprises 9.7M samples that encompass a wide range of video editing tasks. VIVID is a Versatile and Interactive VIdeo local eDiting model trained on VIVID-10M, which supports entity addition, modification, and deletion. At its core, a keyframe-guided interactive video editing mechanism is proposed, enabling users to iteratively edit keyframes and propagate it to other frames, thereby reducing latency in achieving desired outcomes. Extensive experimental evaluations show that our approach achieves state-of-the-art performance in video local editing, surpassing baseline methods in both automated metrics and user studies. The VIVID-10M dataset and the VIVID editing model will be available at \url{https://inkosizhong.github.io/VIVID/}.
DVIS++: Improved Decoupled Framework for Universal Video Segmentation
Dec 20, 2023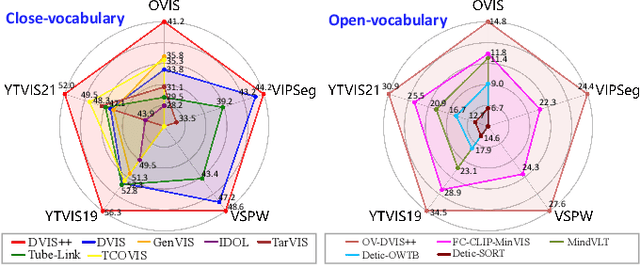
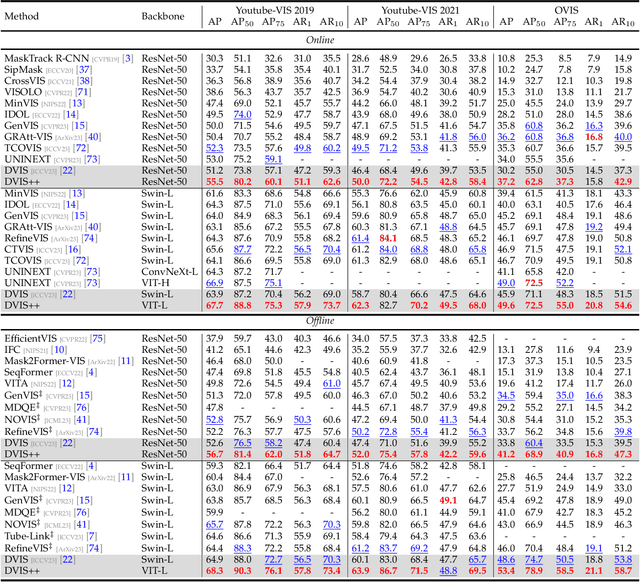
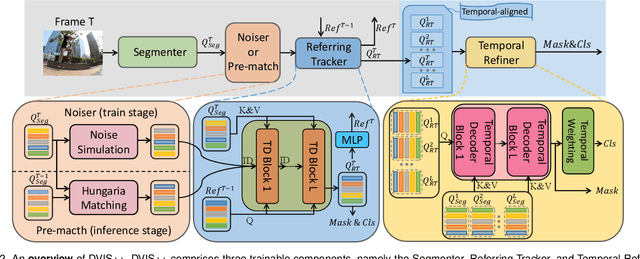
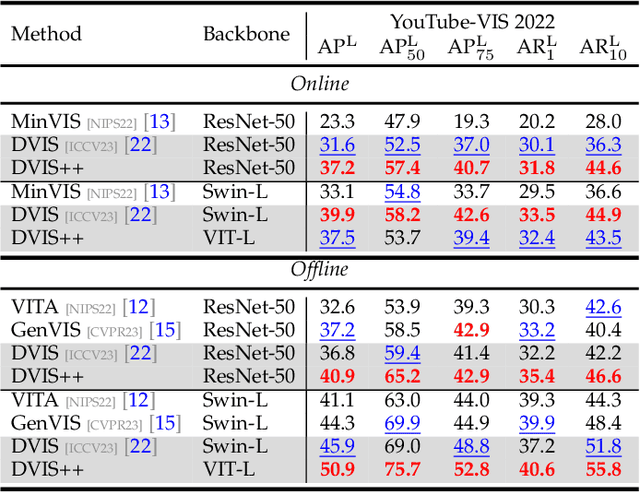
We present the \textbf{D}ecoupled \textbf{VI}deo \textbf{S}egmentation (DVIS) framework, a novel approach for the challenging task of universal video segmentation, including video instance segmentation (VIS), video semantic segmentation (VSS), and video panoptic segmentation (VPS). Unlike previous methods that model video segmentation in an end-to-end manner, our approach decouples video segmentation into three cascaded sub-tasks: segmentation, tracking, and refinement. This decoupling design allows for simpler and more effective modeling of the spatio-temporal representations of objects, especially in complex scenes and long videos. Accordingly, we introduce two novel components: the referring tracker and the temporal refiner. These components track objects frame by frame and model spatio-temporal representations based on pre-aligned features. To improve the tracking capability of DVIS, we propose a denoising training strategy and introduce contrastive learning, resulting in a more robust framework named DVIS++. Furthermore, we evaluate DVIS++ in various settings, including open vocabulary and using a frozen pre-trained backbone. By integrating CLIP with DVIS++, we present OV-DVIS++, the first open-vocabulary universal video segmentation framework. We conduct extensive experiments on six mainstream benchmarks, including the VIS, VSS, and VPS datasets. Using a unified architecture, DVIS++ significantly outperforms state-of-the-art specialized methods on these benchmarks in both close- and open-vocabulary settings. Code:~\url{https://github.com/zhang-tao-whu/DVIS_Plus}.
1st Place Solution for the 5th LSVOS Challenge: Video Instance Segmentation
Aug 28, 2023



Video instance segmentation is a challenging task that serves as the cornerstone of numerous downstream applications, including video editing and autonomous driving. In this report, we present further improvements to the SOTA VIS method, DVIS. First, we introduce a denoising training strategy for the trainable tracker, allowing it to achieve more stable and accurate object tracking in complex and long videos. Additionally, we explore the role of visual foundation models in video instance segmentation. By utilizing a frozen VIT-L model pre-trained by DINO v2, DVIS demonstrates remarkable performance improvements. With these enhancements, our method achieves 57.9 AP and 56.0 AP in the development and test phases, respectively, and ultimately ranked 1st in the VIS track of the 5th LSVOS Challenge. The code will be available at https://github.com/zhang-tao-whu/DVIS.
1st Place Solution for PVUW Challenge 2023: Video Panoptic Segmentation
Jun 08, 2023



Video panoptic segmentation is a challenging task that serves as the cornerstone of numerous downstream applications, including video editing and autonomous driving. We believe that the decoupling strategy proposed by DVIS enables more effective utilization of temporal information for both "thing" and "stuff" objects. In this report, we successfully validated the effectiveness of the decoupling strategy in video panoptic segmentation. Finally, our method achieved a VPQ score of 51.4 and 53.7 in the development and test phases, respectively, and ultimately ranked 1st in the VPS track of the 2nd PVUW Challenge. The code is available at https://github.com/zhang-tao-whu/DVIS
DVIS: Decoupled Video Instance Segmentation Framework
Jun 08, 2023Video instance segmentation (VIS) is a critical task with diverse applications, including autonomous driving and video editing. Existing methods often underperform on complex and long videos in real world, primarily due to two factors. Firstly, offline methods are limited by the tightly-coupled modeling paradigm, which treats all frames equally and disregards the interdependencies between adjacent frames. Consequently, this leads to the introduction of excessive noise during long-term temporal alignment. Secondly, online methods suffer from inadequate utilization of temporal information. To tackle these challenges, we propose a decoupling strategy for VIS by dividing it into three independent sub-tasks: segmentation, tracking, and refinement. The efficacy of the decoupling strategy relies on two crucial elements: 1) attaining precise long-term alignment outcomes via frame-by-frame association during tracking, and 2) the effective utilization of temporal information predicated on the aforementioned accurate alignment outcomes during refinement. We introduce a novel referring tracker and temporal refiner to construct the \textbf{D}ecoupled \textbf{VIS} framework (\textbf{DVIS}). DVIS achieves new SOTA performance in both VIS and VPS, surpassing the current SOTA methods by 7.3 AP and 9.6 VPQ on the OVIS and VIPSeg datasets, which are the most challenging and realistic benchmarks. Moreover, thanks to the decoupling strategy, the referring tracker and temporal refiner are super light-weight (only 1.69\% of the segmenter FLOPs), allowing for efficient training and inference on a single GPU with 11G memory. The code is available at \href{https://github.com/zhang-tao-whu/DVIS}{https://github.com/zhang-tao-whu/DVIS}.