 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVFRTok: Variable Frame Rates Video Tokenizer with Duration-Proportional Information Assumption
May 17, 2025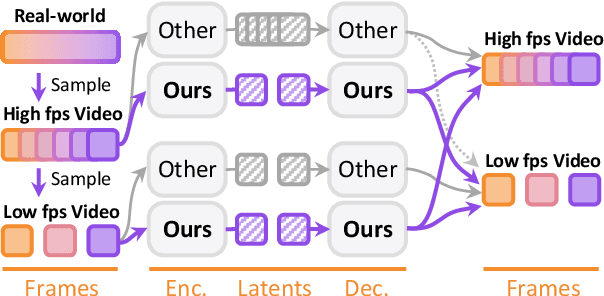
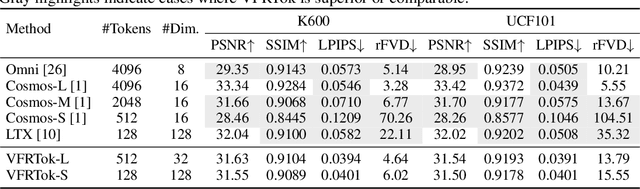
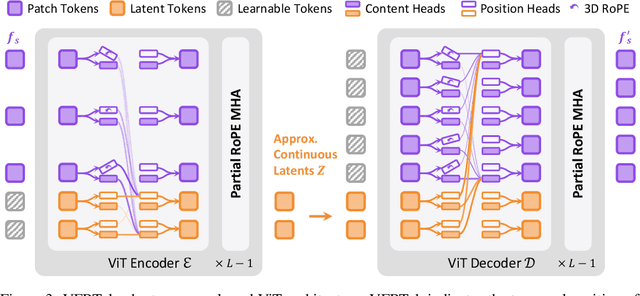
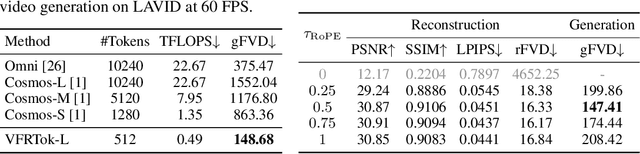
Modern video generation frameworks based on Latent Diffusion Models suffer from inefficiencies in tokenization due to the Frame-Proportional Information Assumption. Existing tokenizers provide fixed temporal compression rates, causing the computational cost of the diffusion model to scale linearly with the frame rate. The paper proposes the Duration-Proportional Information Assumption: the upper bound on the information capacity of a video is proportional to the duration rather than the number of frames. Based on this insight, the paper introduces VFRTok, a Transformer-based video tokenizer, that enables variable frame rate encoding and decoding through asymmetric frame rate training between the encoder and decoder. Furthermore, the paper proposes Partial Rotary Position Embeddings (RoPE) to decouple position and content modeling, which groups correlated patches into unified tokens. The Partial RoPE effectively improves content-awareness, enhancing the video generation capability. Benefiting from the compact and continuous spatio-temporal representation, VFRTok achieves competitive reconstruction quality and state-of-the-art generation fidelity while using only 1/8 tokens compared to existing tokenizers.
VIVID-10M: A Dataset and Baseline for Versatile and Interactive Video Local Editing
Nov 22, 2024



Diffusion-based image editing models have made remarkable progress in recent years. However, achieving high-quality video editing remains a significant challenge. One major hurdle is the absence of open-source, large-scale video editing datasets based on real-world data, as constructing such datasets is both time-consuming and costly. Moreover, video data requires a significantly larger number of tokens for representation, which substantially increases the training costs for video editing models. Lastly, current video editing models offer limited interactivity, often making it difficult for users to express their editing requirements effectively in a single attempt. To address these challenges, this paper introduces a dataset VIVID-10M and a baseline model VIVID. VIVID-10M is the first large-scale hybrid image-video local editing dataset aimed at reducing data construction and model training costs, which comprises 9.7M samples that encompass a wide range of video editing tasks. VIVID is a Versatile and Interactive VIdeo local eDiting model trained on VIVID-10M, which supports entity addition, modification, and deletion. At its core, a keyframe-guided interactive video editing mechanism is proposed, enabling users to iteratively edit keyframes and propagate it to other frames, thereby reducing latency in achieving desired outcomes. Extensive experimental evaluations show that our approach achieves state-of-the-art performance in video local editing, surpassing baseline methods in both automated metrics and user studies. The VIVID-10M dataset and the VIVID editing model will be available at \url{https://inkosizhong.github.io/VIVID/}.
Preprocessing Enhanced Image Compression for Machine Vision
Jun 12, 2022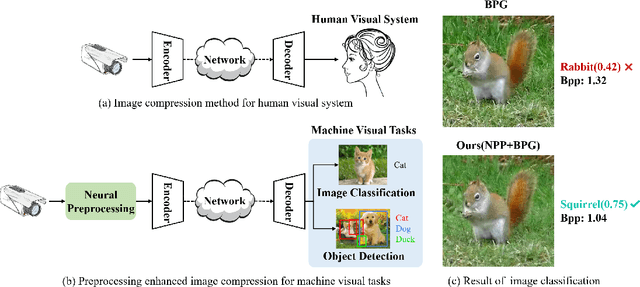
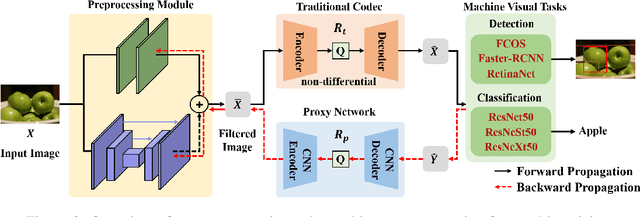

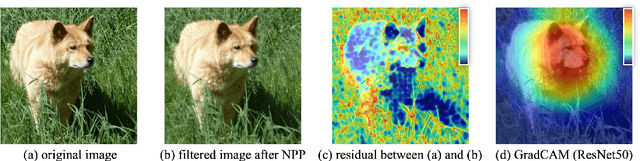
Recently, more and more images are compressed and sent to the back-end devices for the machine analysis tasks~(\textit{e.g.,} object detection) instead of being purely watched by humans. However, most traditional or learned image codecs are designed to minimize the distortion of the human visual system without considering the increased demand from machine vision systems. In this work, we propose a preprocessing enhanced image compression method for machine vision tasks to address this challenge. Instead of relying on the learned image codecs for end-to-end optimization, our framework is built upon the traditional non-differential codecs, which means it is standard compatible and can be easily deployed in practical applications. Specifically, we propose a neural preprocessing module before the encoder to maintain the useful semantic information for the downstream tasks and suppress the irrelevant information for bitrate saving. Furthermore, our neural preprocessing module is quantization adaptive and can be used in different compression ratios. More importantly, to jointly optimize the preprocessing module with the downstream machine vision tasks, we introduce the proxy network for the traditional non-differential codecs in the back-propagation stage. We provide extensive experiments by evaluating our compression method for two representative downstream tasks with different backbone networks. Experimental results show our method achieves a better trade-off between the coding bitrate and the performance of the downstream machine vision tasks by saving about 20% bitrate.