 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWan-Animate: Unified Character Animation and Replacement with Holistic Replication
Sep 17, 2025

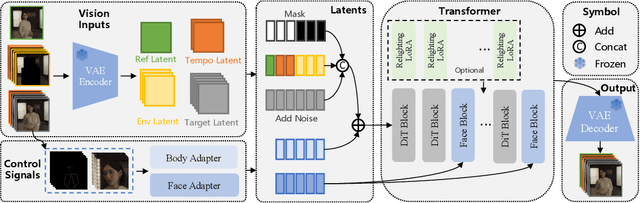
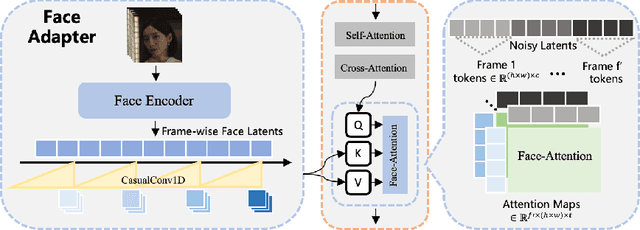
We introduce Wan-Animate, a unified framework for character animation and replacement. Given a character image and a reference video, Wan-Animate can animate the character by precisely replicating the expressions and movements of the character in the video to generate high-fidelity character videos. Alternatively, it can integrate the animated character into the reference video to replace the original character, replicating the scene's lighting and color tone to achieve seamless environmental integration. Wan-Animate is built upon the Wan model. To adapt it for character animation tasks, we employ a modified input paradigm to differentiate between reference conditions and regions for generation. This design unifies multiple tasks into a common symbolic representation. We use spatially-aligned skeleton signals to replicate body motion and implicit facial features extracted from source images to reenact expressions, enabling the generation of character videos with high controllability and expressiveness. Furthermore, to enhance environmental integration during character replacement, we develop an auxiliary Relighting LoRA. This module preserves the character's appearance consistency while applying the appropriate environmental lighting and color tone. Experimental results demonstrate that Wan-Animate achieves state-of-the-art performance. We are committed to open-sourcing the model weights and its source code.
EMO2: End-Effector Guided Audio-Driven Avatar Video Generation
Jan 18, 2025



In this paper, we propose a novel audio-driven talking head method capable of simultaneously generating highly expressive facial expressions and hand gestures. Unlike existing methods that focus on generating full-body or half-body poses, we investigate the challenges of co-speech gesture generation and identify the weak correspondence between audio features and full-body gestures as a key limitation. To address this, we redefine the task as a two-stage process. In the first stage, we generate hand poses directly from audio input, leveraging the strong correlation between audio signals and hand movements. In the second stage, we employ a diffusion model to synthesize video frames, incorporating the hand poses generated in the first stage to produce realistic facial expressions and body movements. Our experimental results demonstrate that the proposed method outperforms state-of-the-art approaches, such as CyberHost and Vlogger, in terms of both visual quality and synchronization accuracy. This work provides a new perspective on audio-driven gesture generation and a robust framework for creating expressive and natural talking head animations.
Make-A-Character: High Quality Text-to-3D Character Generation within Minutes
Dec 24, 2023



There is a growing demand for customized and expressive 3D characters with the emergence of AI agents and Metaverse, but creating 3D characters using traditional computer graphics tools is a complex and time-consuming task. To address these challenges, we propose a user-friendly framework named Make-A-Character (Mach) to create lifelike 3D avatars from text descriptions. The framework leverages the power of large language and vision models for textual intention understanding and intermediate image generation, followed by a series of human-oriented visual perception and 3D generation modules. Our system offers an intuitive approach for users to craft controllable, realistic, fully-realized 3D characters that meet their expectations within 2 minutes, while also enabling easy integration with existing CG pipeline for dynamic expressiveness. For more information, please visit the project page at https://human3daigc.github.io/MACH/.
A Real World Dataset for Multi-view 3D Reconstruction
Mar 22, 2022
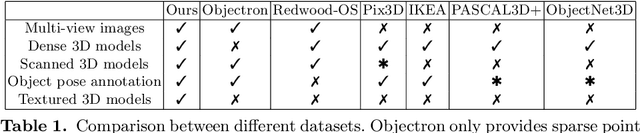
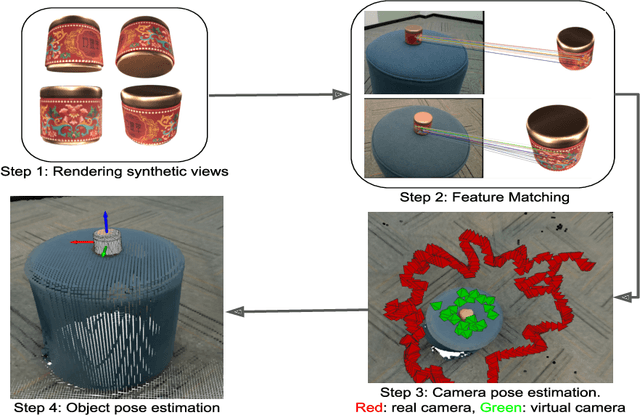
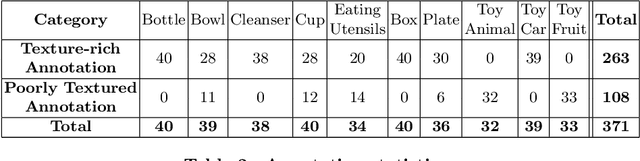
We present a dataset of 371 3D models of everyday tabletop objects along with their 320,000 real world RGB and depth images. Accurate annotations of camera poses and object poses for each image are performed in a semi-automated fashion to facilitate the use of the dataset for myriad 3D applications like shape reconstruction, object pose estimation, shape retrieval etc. We primarily focus on learned multi-view 3D reconstruction due to the lack of appropriate real world benchmark for the task and demonstrate that our dataset can fill that gap. The entire annotated dataset along with the source code for the annotation tools and evaluation baselines will be made publicly available.