 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaDe-GS: Rasterizing Depth in Gaussian Splatting
Jun 03, 2024
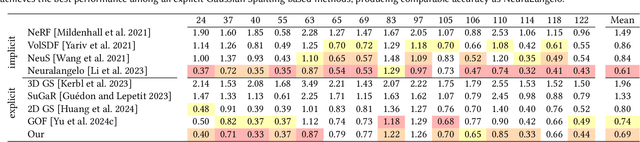
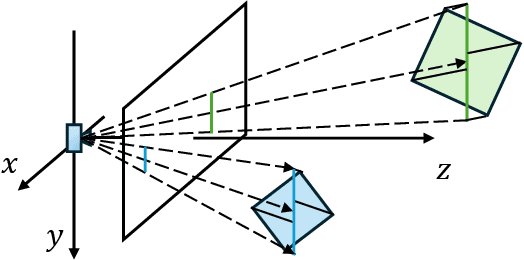
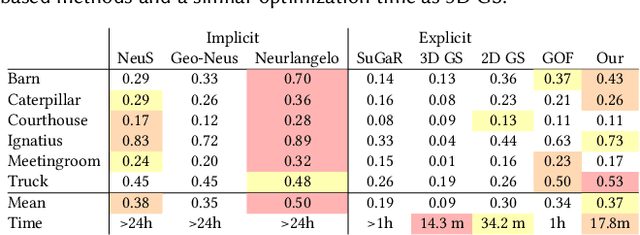
Gaussian Splatting (GS) has proven to be highly effective in novel view synthesis, achieving high-quality and real-time rendering. However, its potential for reconstructing detailed 3D shapes has not been fully explored. Existing methods often suffer from limited shape accuracy due to the discrete and unstructured nature of Gaussian splats, which complicates the shape extraction. While recent techniques like 2D GS have attempted to improve shape reconstruction, they often reformulate the Gaussian primitives in ways that reduce both rendering quality and computational efficiency. To address these problems, our work introduces a rasterized approach to render the depth maps and surface normal maps of general 3D Gaussian splats. Our method not only significantly enhances shape reconstruction accuracy but also maintains the computational efficiency intrinsic to Gaussian Splatting. Our approach achieves a Chamfer distance error comparable to NeuraLangelo on the DTU dataset and similar training and rendering time as traditional Gaussian Splatting on the Tanks & Temples dataset. Our method is a significant advancement in Gaussian Splatting and can be directly integrated into existing Gaussian Splatting-based methods.
A Real World Dataset for Multi-view 3D Reconstruction
Mar 22, 2022
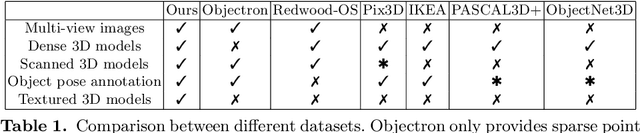
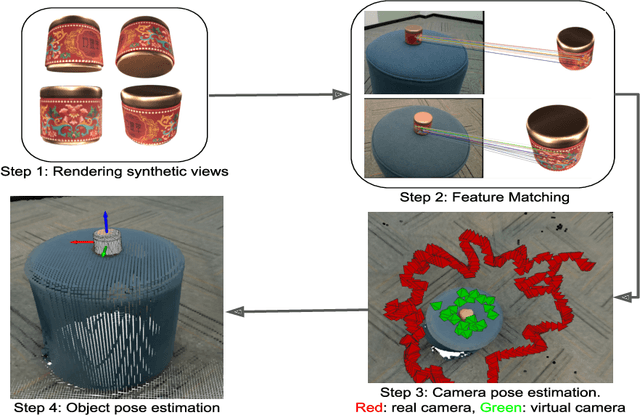
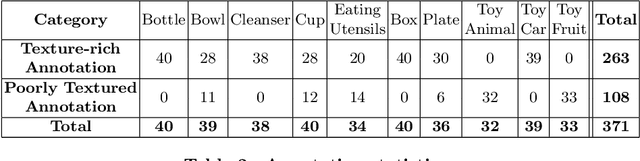
We present a dataset of 371 3D models of everyday tabletop objects along with their 320,000 real world RGB and depth images. Accurate annotations of camera poses and object poses for each image are performed in a semi-automated fashion to facilitate the use of the dataset for myriad 3D applications like shape reconstruction, object pose estimation, shape retrieval etc. We primarily focus on learned multi-view 3D reconstruction due to the lack of appropriate real world benchmark for the task and demonstrate that our dataset can fill that gap. The entire annotated dataset along with the source code for the annotation tools and evaluation baselines will be made publicly available.
MeshMVS: Multi-View Stereo Guided Mesh Reconstruction
Oct 17, 2020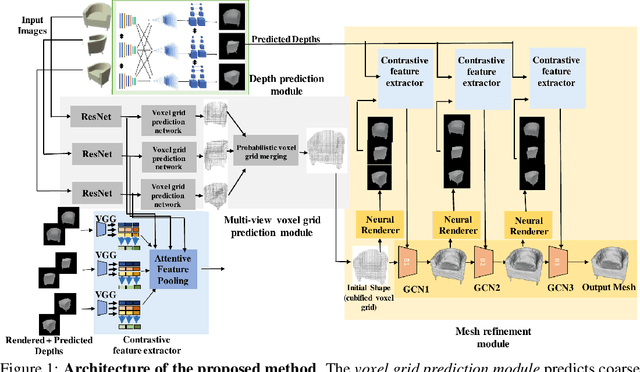
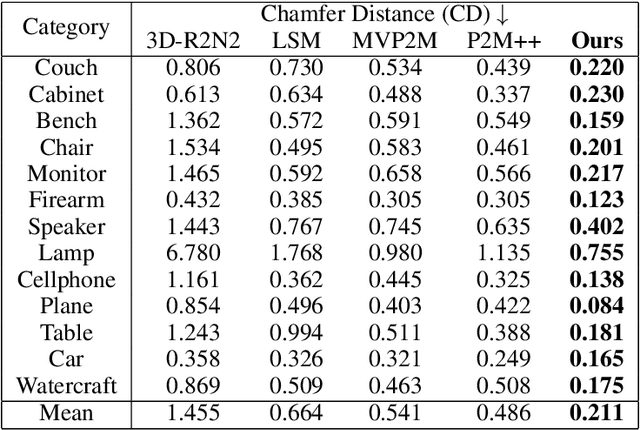


Deep learning based 3D shape generation methods generally utilize latent features extracted from color images to encode the objects' semantics and guide the shape generation process. These color image semantics only implicitly encode 3D information, potentially limiting the accuracy of the generated shapes. In this paper we propose a multi-view mesh generation method which incorporates geometry information in the color images explicitly by using the features from intermediate 2.5D depth representations of the input images and regularizing the 3D shapes against these depth images. Our system first predicts a coarse 3D volume from the color images by probabilistically merging voxel occupancy grids from individual views. Depth images corresponding to the multi-view color images are predicted which along with the rendered depth images of the coarse shape are used as a contrastive input whose features guide the refinement of the coarse shape through a series of graph convolution networks. Attention-based multi-view feature pooling is proposed to fuse the contrastive depth features from different viewpoints which are fed to the graph convolution networks. We validate the proposed multi-view mesh generation method on ShapeNet, where we obtain a significant improvement with 34% decrease in chamfer distance to ground truth and 14% increase in the F1-score compared with the state-of-the-art multi-view shape generation method.