 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPATIALGEN: Layout-guided 3D Indoor Scene Generation
Sep 18, 2025
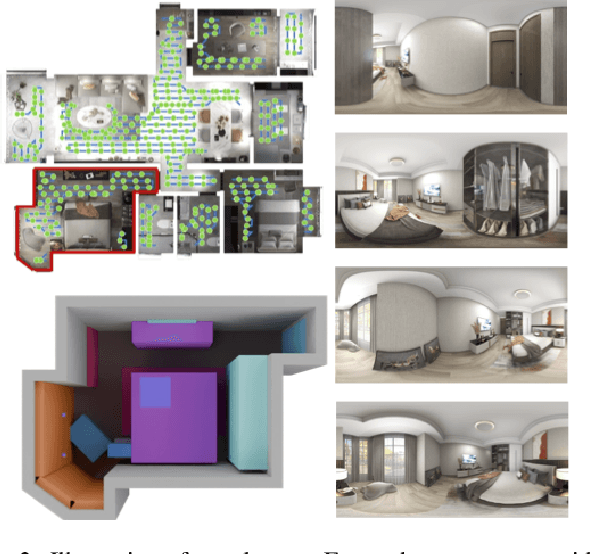
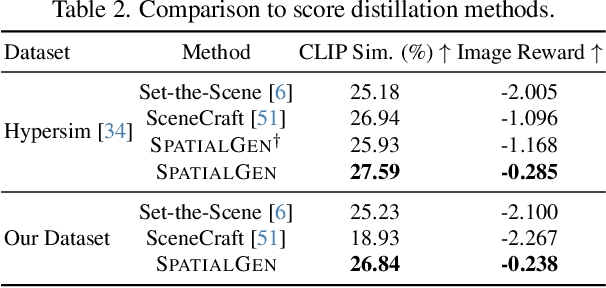
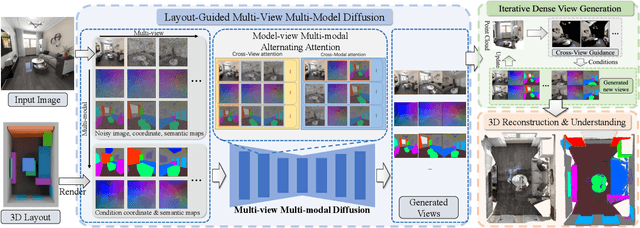
Creating high-fidelity 3D models of indoor environments is essential for applications in design, virtual reality, and robotics. However, manual 3D modeling remains time-consuming and labor-intensive. While recent advances in generative AI have enabled automated scene synthesis, existing methods often face challenges in balancing visual quality, diversity, semantic consistency, and user control. A major bottleneck is the lack of a large-scale, high-quality dataset tailored to this task. To address this gap, we introduce a comprehensive synthetic dataset, featuring 12,328 structured annotated scenes with 57,440 rooms, and 4.7M photorealistic 2D renderings. Leveraging this dataset, we present SpatialGen, a novel multi-view multi-modal diffusion model that generates realistic and semantically consistent 3D indoor scenes. Given a 3D layout and a reference image (derived from a text prompt), our model synthesizes appearance (color image), geometry (scene coordinate map), and semantic (semantic segmentation map) from arbitrary viewpoints, while preserving spatial consistency across modalities. SpatialGen consistently generates superior results to previous methods in our experiments. We are open-sourcing our data and models to empower the community and advance the field of indoor scene understanding and generation.
SpatialLM: Training Large Language Models for Structured Indoor Modeling
Jun 09, 2025
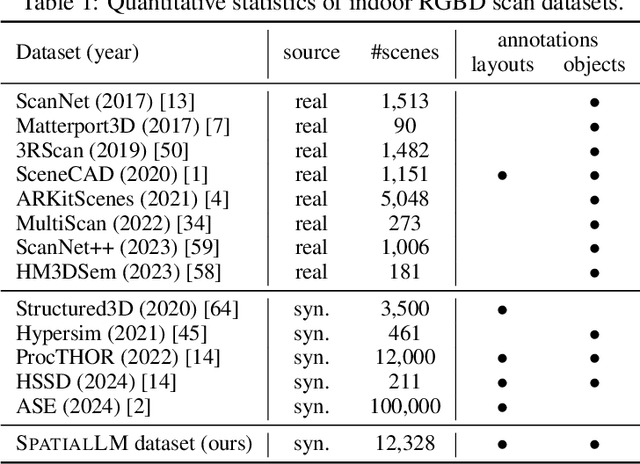

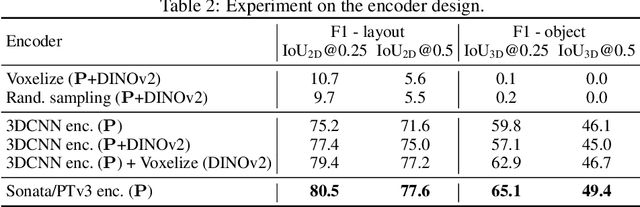
SpatialLM is a large language model designed to process 3D point cloud data and generate structured 3D scene understanding outputs. These outputs include architectural elements like walls, doors, windows, and oriented object boxes with their semantic categories. Unlike previous methods which exploit task-specific network designs, our model adheres to the standard multimodal LLM architecture and is fine-tuned directly from open-source LLMs. To train SpatialLM, we collect a large-scale, high-quality synthetic dataset consisting of the point clouds of 12,328 indoor scenes (54,778 rooms) with ground-truth 3D annotations, and conduct a careful study on various modeling and training decisions. On public benchmarks, our model gives state-of-the-art performance in layout estimation and competitive results in 3D object detection. With that, we show a feasible path for enhancing the spatial understanding capabilities of modern LLMs for applications in augmented reality, embodied robotics, and more.
World-Consistent Data Generation for Vision-and-Language Navigation
Dec 09, 2024Vision-and-Language Navigation (VLN) is a challenging task that requires an agent to navigate through photorealistic environments following natural-language instructions. One main obstacle existing in VLN is data scarcity, leading to poor generalization performance over unseen environments. Tough data argumentation is a promising way for scaling up the dataset, how to generate VLN data both diverse and world-consistent remains problematic. To cope with this issue, we propose the world-consistent data generation (WCGEN), an efficacious data-augmentation framework satisfying both diversity and world-consistency, targeting at enhancing the generalizations of agents to novel environments. Roughly, our framework consists of two stages, the trajectory stage which leverages a point-cloud based technique to ensure spatial coherency among viewpoints, and the viewpoint stage which adopts a novel angle synthesis method to guarantee spatial and wraparound consistency within the entire observation. By accurately predicting viewpoint changes with 3D knowledge, our approach maintains the world-consistency during the generation procedure. Experiments on a wide range of datasets verify the effectiveness of our method, demonstrating that our data augmentation strategy enables agents to achieve new state-of-the-art results on all navigation tasks, and is capable of enhancing the VLN agents' generalization ability to unseen environments.
RaDe-GS: Rasterizing Depth in Gaussian Splatting
Jun 03, 2024
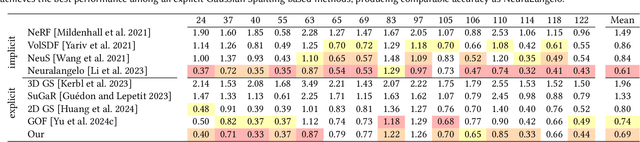
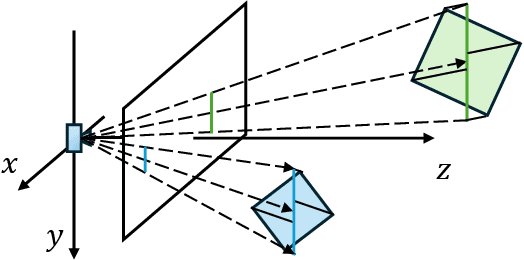
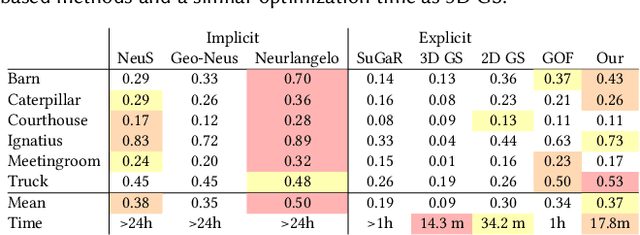
Gaussian Splatting (GS) has proven to be highly effective in novel view synthesis, achieving high-quality and real-time rendering. However, its potential for reconstructing detailed 3D shapes has not been fully explored. Existing methods often suffer from limited shape accuracy due to the discrete and unstructured nature of Gaussian splats, which complicates the shape extraction. While recent techniques like 2D GS have attempted to improve shape reconstruction, they often reformulate the Gaussian primitives in ways that reduce both rendering quality and computational efficiency. To address these problems, our work introduces a rasterized approach to render the depth maps and surface normal maps of general 3D Gaussian splats. Our method not only significantly enhances shape reconstruction accuracy but also maintains the computational efficiency intrinsic to Gaussian Splatting. Our approach achieves a Chamfer distance error comparable to NeuraLangelo on the DTU dataset and similar training and rendering time as traditional Gaussian Splatting on the Tanks & Temples dataset. Our method is a significant advancement in Gaussian Splatting and can be directly integrated into existing Gaussian Splatting-based methods.
Ctrl-Room: Controllable Text-to-3D Room Meshes Generation with Layout Constraints
Oct 09, 2023



Text-driven 3D indoor scene generation could be useful for gaming, film industry, and AR/VR applications. However, existing methods cannot faithfully capture the room layout, nor do they allow flexible editing of individual objects in the room. To address these problems, we present Ctrl-Room, which is able to generate convincing 3D rooms with designer-style layouts and high-fidelity textures from just a text prompt. Moreover, Ctrl-Room enables versatile interactive editing operations such as resizing or moving individual furniture items. Our key insight is to separate the modeling of layouts and appearance. %how to model the room that takes into account both scene texture and geometry at the same time. To this end, Our proposed method consists of two stages, a `Layout Generation Stage' and an `Appearance Generation Stage'. The `Layout Generation Stage' trains a text-conditional diffusion model to learn the layout distribution with our holistic scene code parameterization. Next, the `Appearance Generation Stage' employs a fine-tuned ControlNet to produce a vivid panoramic image of the room guided by the 3D scene layout and text prompt. In this way, we achieve a high-quality 3D room with convincing layouts and lively textures. Benefiting from the scene code parameterization, we can easily edit the generated room model through our mask-guided editing module, without expensive editing-specific training. Extensive experiments on the Structured3D dataset demonstrate that our method outperforms existing methods in producing more reasonable, view-consistent, and editable 3D rooms from natural language prompts.
PanoContext-Former: Panoramic Total Scene Understanding with a Transformer
May 21, 2023Panoramic image enables deeper understanding and more holistic perception of $360^\circ$ surrounding environment, which can naturally encode enriched scene context information compared to standard perspective image. Previous work has made lots of effort to solve the scene understanding task in a bottom-up form, thus each sub-task is processed separately and few correlations are explored in this procedure. In this paper, we propose a novel method using depth prior for holistic indoor scene understanding which recovers the objects' shapes, oriented bounding boxes and the 3D room layout simultaneously from a single panorama. In order to fully utilize the rich context information, we design a transformer-based context module to predict the representation and relationship among each component of the scene. In addition, we introduce a real-world dataset for scene understanding, including photo-realistic panoramas, high-fidelity depth images, accurately annotated room layouts, and oriented object bounding boxes and shapes. Experiments on the synthetic and real-world datasets demonstrate that our method outperforms previous panoramic scene understanding methods in terms of both layout estimation and 3D object detection.
RenderNet: Visual Relocalization Using Virtual Viewpoints in Large-Scale Indoor Environments
Jul 26, 2022
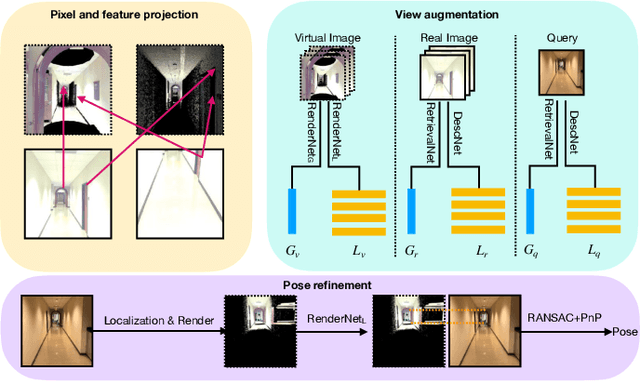
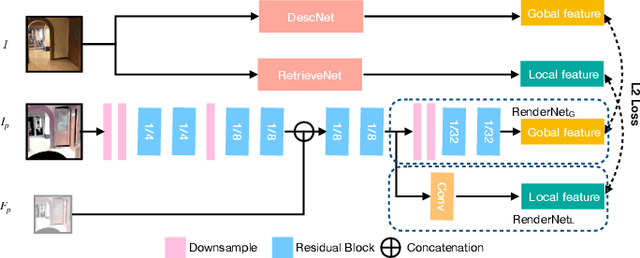

Visual relocalization has been a widely discussed problem in 3D vision: given a pre-constructed 3D visual map, the 6 DoF (Degrees-of-Freedom) pose of a query image is estimated. Relocalization in large-scale indoor environments enables attractive applications such as augmented reality and robot navigation. However, appearance changes fast in such environments when the camera moves, which is challenging for the relocalization system. To address this problem, we propose a virtual view synthesis-based approach, RenderNet, to enrich the database and refine poses regarding this particular scenario. Instead of rendering real images which requires high-quality 3D models, we opt to directly render the needed global and local features of virtual viewpoints and apply them in the subsequent image retrieval and feature matching operations respectively. The proposed method can largely improve the performance in large-scale indoor environments, e.g., achieving an improvement of 7.1\% and 12.2\% on the Inloc dataset.
AR Mapping: Accurate and Efficient Mapping for Augmented Reality
Mar 27, 2021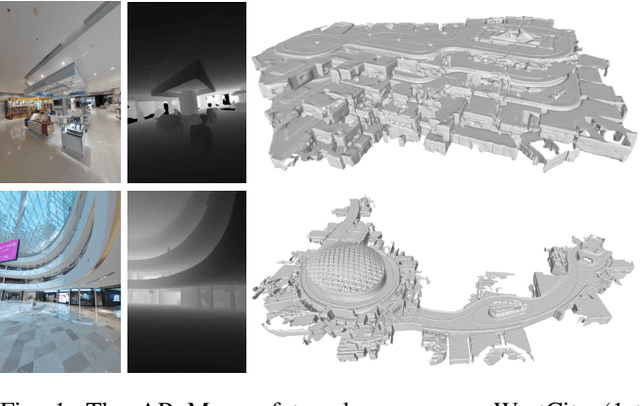

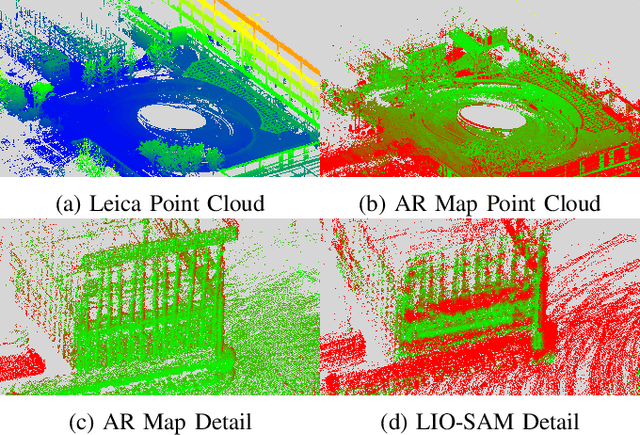

Augmented reality (AR) has gained increasingly attention from both research and industry communities. By overlaying digital information and content onto the physical world, AR enables users to experience the world in a more informative and efficient manner. As a major building block for AR systems, localization aims at determining the device's pose from a pre-built "map" consisting of visual and depth information in a known environment. While the localization problem has been widely studied in the literature, the "map" for AR systems is rarely discussed. In this paper, we introduce the AR Map for a specific scene to be composed of 1) color images with 6-DOF poses; 2) dense depth maps for each image and 3) a complete point cloud map. We then propose an efficient end-to-end solution to generating and evaluating AR Maps. Firstly, for efficient data capture, a backpack scanning device is presented with a unified calibration pipeline. Secondly, we propose an AR mapping pipeline which takes the input from the scanning device and produces accurate AR Maps. Finally, we present an approach to evaluating the accuracy of AR Maps with the help of the highly accurate reconstruction result from a high-end laser scanner. To the best of our knowledge, it is the first time to present an end-to-end solution to efficient and accurate mapping for AR applications.
Single-Shot is Enough: Panoramic Infrastructure Based Calibration of Multiple Cameras and 3D LiDARs
Mar 24, 2021
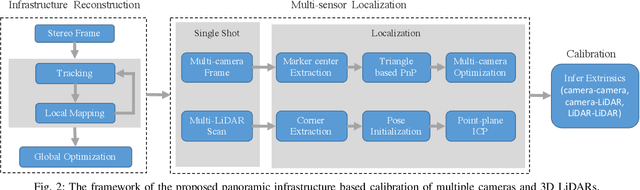
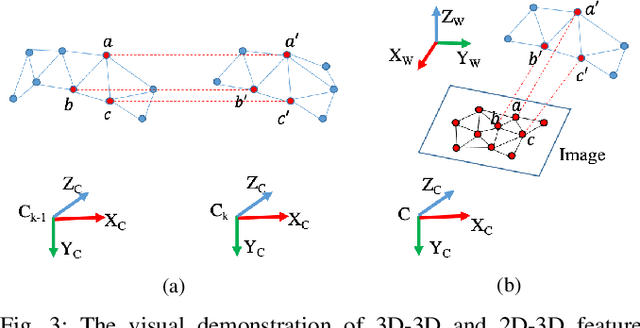

The integration of multiple cameras and 3D Li- DARs has become basic configuration of augmented reality devices, robotics, and autonomous vehicles. The calibration of multi-modal sensors is crucial for a system to properly function, but it remains tedious and impractical for mass production. Moreover, most devices require re-calibration after usage for certain period of time. In this paper, we propose a single-shot solution for calibrating extrinsic transformations among multiple cameras and 3D LiDARs. We establish a panoramic infrastructure, in which a camera or LiDAR can be robustly localized using data from single frame. Experiments are conducted on three devices with different camera-LiDAR configurations, showing that our approach achieved comparable calibration accuracy with the state-of-the-art approaches but with much greater efficiency.