 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncTrack: Reliable Visual Object Tracking with Uncertainty-Aware Prototype Memory Network
Mar 17, 2025
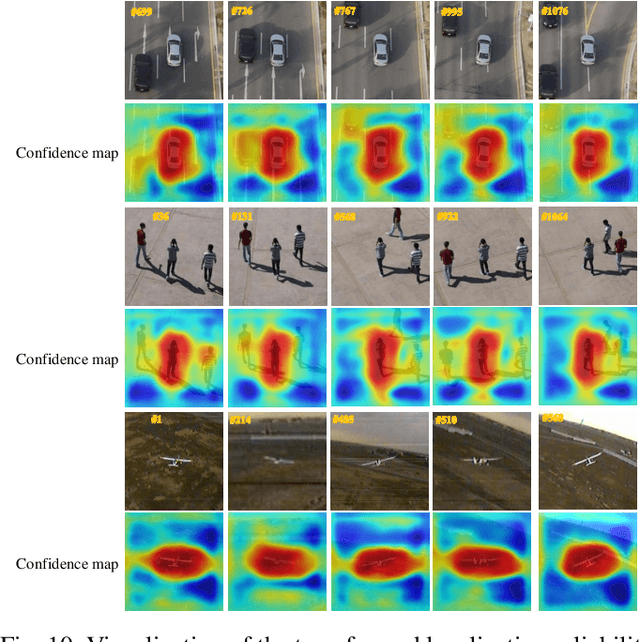

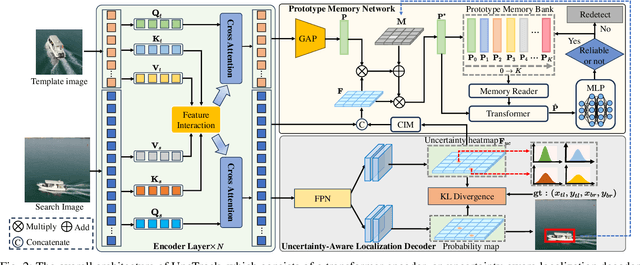
Transformer-based trackers have achieved promising success and become the dominant tracking paradigm due to their accuracy and efficiency. Despite the substantial progress, most of the existing approaches tackle object tracking as a deterministic coordinate regression problem, while the target localization uncertainty has been greatly overlooked, which hampers trackers' ability to maintain reliable target state prediction in challenging scenarios. To address this issue, we propose UncTrack, a novel uncertainty-aware transformer tracker that predicts the target localization uncertainty and incorporates this uncertainty information for accurate target state inference. Specifically, UncTrack utilizes a transformer encoder to perform feature interaction between template and search images. The output features are passed into an uncertainty-aware localization decoder (ULD) to coarsely predict the corner-based localization and the corresponding localization uncertainty. Then the localization uncertainty is sent into a prototype memory network (PMN) to excavate valuable historical information to identify whether the target state prediction is reliable or not. To enhance the template representation, the samples with high confidence are fed back into the prototype memory bank for memory updating, making the tracker more robust to challenging appearance variations. Extensive experiments demonstrate that our method outperforms other state-of-the-art methods. Our code is available at https://github.com/ManOfStory/UncTrack.
World-Consistent Data Generation for Vision-and-Language Navigation
Dec 09, 2024Vision-and-Language Navigation (VLN) is a challenging task that requires an agent to navigate through photorealistic environments following natural-language instructions. One main obstacle existing in VLN is data scarcity, leading to poor generalization performance over unseen environments. Tough data argumentation is a promising way for scaling up the dataset, how to generate VLN data both diverse and world-consistent remains problematic. To cope with this issue, we propose the world-consistent data generation (WCGEN), an efficacious data-augmentation framework satisfying both diversity and world-consistency, targeting at enhancing the generalizations of agents to novel environments. Roughly, our framework consists of two stages, the trajectory stage which leverages a point-cloud based technique to ensure spatial coherency among viewpoints, and the viewpoint stage which adopts a novel angle synthesis method to guarantee spatial and wraparound consistency within the entire observation. By accurately predicting viewpoint changes with 3D knowledge, our approach maintains the world-consistency during the generation procedure. Experiments on a wide range of datasets verify the effectiveness of our method, demonstrating that our data augmentation strategy enables agents to achieve new state-of-the-art results on all navigation tasks, and is capable of enhancing the VLN agents' generalization ability to unseen environments.
Feedback Graph Attention Convolutional Network for Medical Image Enhancement
Jun 24, 2020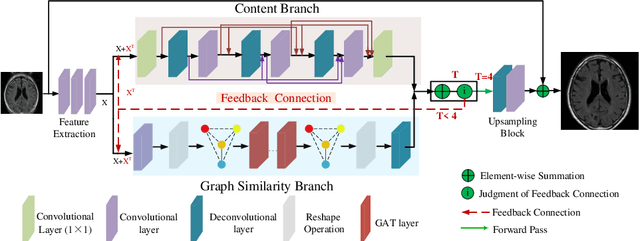
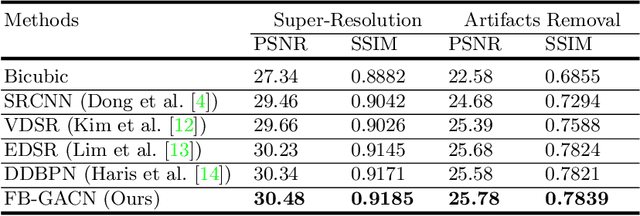
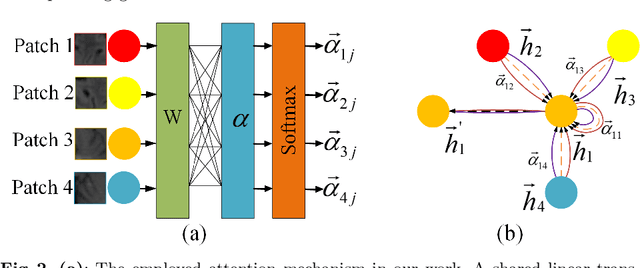

Artifacts, blur and noise are the common distortions degrading MRI images during the acquisition process, and deep neural networks have been demonstrated to help in improving image quality. To well exploit global structural information and texture details, we propose a novel biomedical image enhancement network, named Feedback Graph Attention Convolutional Network (FB-GACN). As a key innovation, we consider the global structure of an image by building a graph network from image sub-regions that we consider to be node features, linking them non-locally according to their similarity. The proposed model consists of three main parts: 1) The parallel graph similarity branch and content branch, where the graph similarity branch aims at exploiting the similarity and symmetry across different image sub-regions in low-resolution feature space and provides additional priors for the content branch to enhance texture details. 2) A feedback mechanism with a recurrent structure to refine low-level representations with high-level information and generate powerful high-level texture details by handling the feedback connections. 3) A reconstruction to remove the artifacts and recover super-resolution images by using the estimated sub-region correlation priors obtained from the graph similarity branch. We evaluate our method on two image enhancement tasks: i) cross-protocol super resolution of diffusion MRI; ii) artifact removal of FLAIR MR images. Experimental results demonstrate that the proposed algorithm outperforms the state-of-the-art methods.