 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Lane Segment Perception and Topology Reasoning with Crowdsourcing Trajectory Priors
Nov 26, 2024In autonomous driving, recent advances in lane segment perception provide autonomous vehicles with a comprehensive understanding of driving scenarios. Moreover, incorporating prior information input into such perception model represents an effective approach to ensure the robustness and accuracy. However, utilizing diverse sources of prior information still faces three key challenges: the acquisition of high-quality prior information, alignment between prior and online perception, efficient integration. To address these issues, we investigate prior augmentation from a novel perspective of trajectory priors. In this paper, we initially extract crowdsourcing trajectory data from Argoverse2 motion forecasting dataset and encode trajectory data into rasterized heatmap and vectorized instance tokens, then we incorporate such prior information into the online mapping model through different ways. Besides, with the purpose of mitigating the misalignment between prior and online perception, we design a confidence-based fusion module that takes alignment into account during the fusion process. We conduct extensive experiments on OpenLane-V2 dataset. The results indicate that our method's performance significantly outperforms the current state-of-the-art methods.
DiffMap: Enhancing Map Segmentation with Map Prior Using Diffusion Model
May 03, 2024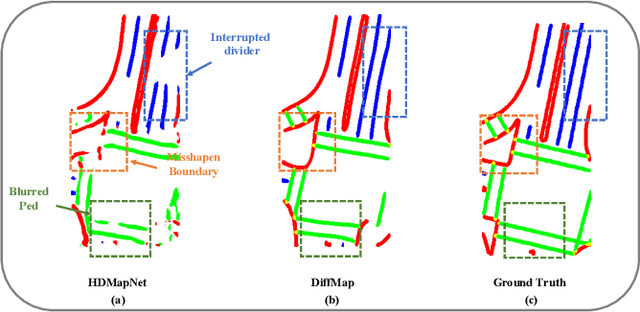
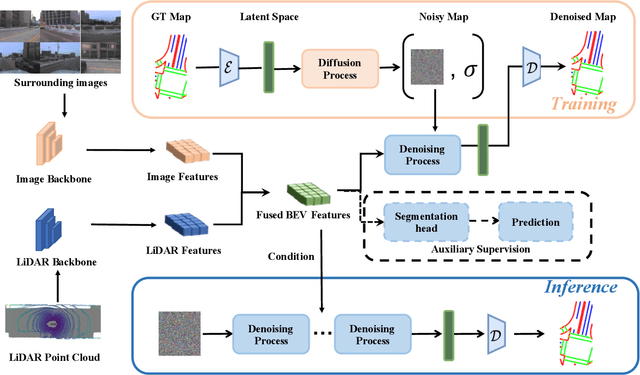
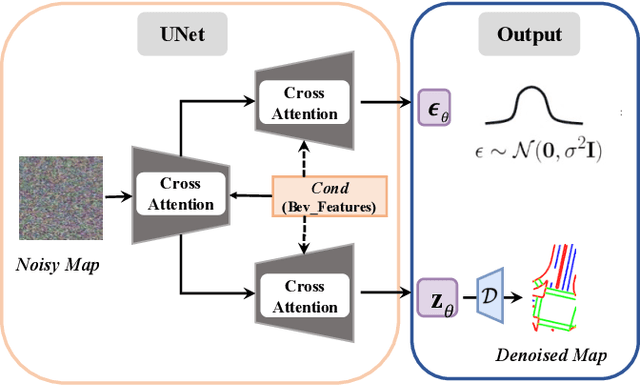

Constructing high-definition (HD) maps is a crucial requirement for enabling autonomous driving. In recent years, several map segmentation algorithms have been developed to address this need, leveraging advancements in Bird's-Eye View (BEV) perception. However, existing models still encounter challenges in producing realistic and consistent semantic map layouts. One prominent issue is the limited utilization of structured priors inherent in map segmentation masks. In light of this, we propose DiffMap, a novel approach specifically designed to model the structured priors of map segmentation masks using latent diffusion model. By incorporating this technique, the performance of existing semantic segmentation methods can be significantly enhanced and certain structural errors present in the segmentation outputs can be effectively rectified. Notably, the proposed module can be seamlessly integrated into any map segmentation model, thereby augmenting its capability to accurately delineate semantic information. Furthermore, through extensive visualization analysis, our model demonstrates superior proficiency in generating results that more accurately reflect real-world map layouts, further validating its efficacy in improving the quality of the generated maps.
RenderNet: Visual Relocalization Using Virtual Viewpoints in Large-Scale Indoor Environments
Jul 26, 2022
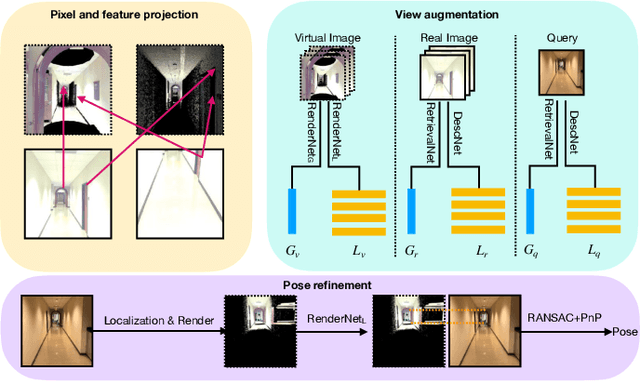
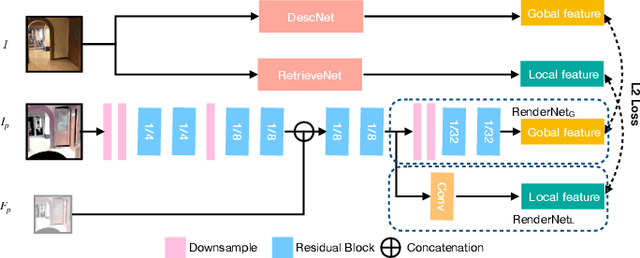

Visual relocalization has been a widely discussed problem in 3D vision: given a pre-constructed 3D visual map, the 6 DoF (Degrees-of-Freedom) pose of a query image is estimated. Relocalization in large-scale indoor environments enables attractive applications such as augmented reality and robot navigation. However, appearance changes fast in such environments when the camera moves, which is challenging for the relocalization system. To address this problem, we propose a virtual view synthesis-based approach, RenderNet, to enrich the database and refine poses regarding this particular scenario. Instead of rendering real images which requires high-quality 3D models, we opt to directly render the needed global and local features of virtual viewpoints and apply them in the subsequent image retrieval and feature matching operations respectively. The proposed method can largely improve the performance in large-scale indoor environments, e.g., achieving an improvement of 7.1\% and 12.2\% on the Inloc dataset.
AR Mapping: Accurate and Efficient Mapping for Augmented Reality
Mar 27, 2021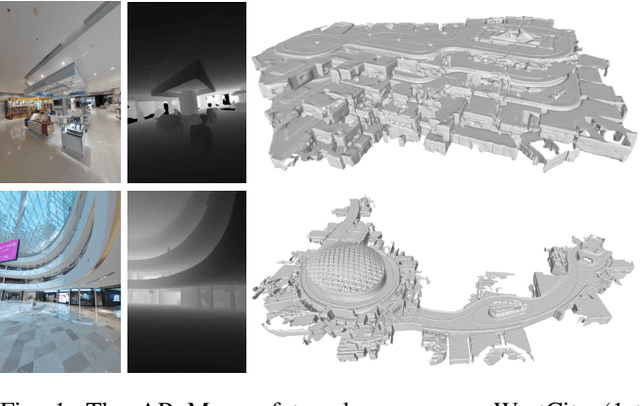

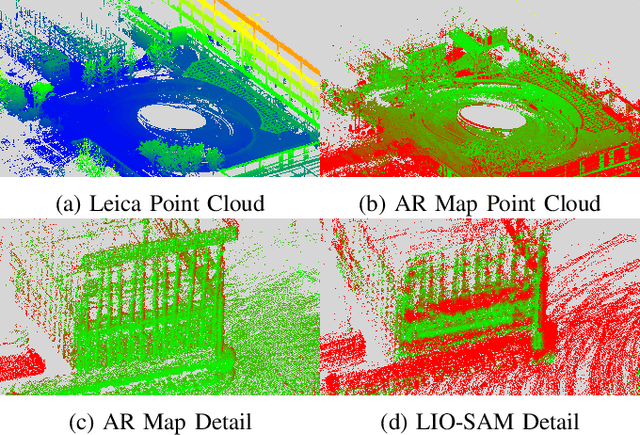

Augmented reality (AR) has gained increasingly attention from both research and industry communities. By overlaying digital information and content onto the physical world, AR enables users to experience the world in a more informative and efficient manner. As a major building block for AR systems, localization aims at determining the device's pose from a pre-built "map" consisting of visual and depth information in a known environment. While the localization problem has been widely studied in the literature, the "map" for AR systems is rarely discussed. In this paper, we introduce the AR Map for a specific scene to be composed of 1) color images with 6-DOF poses; 2) dense depth maps for each image and 3) a complete point cloud map. We then propose an efficient end-to-end solution to generating and evaluating AR Maps. Firstly, for efficient data capture, a backpack scanning device is presented with a unified calibration pipeline. Secondly, we propose an AR mapping pipeline which takes the input from the scanning device and produces accurate AR Maps. Finally, we present an approach to evaluating the accuracy of AR Maps with the help of the highly accurate reconstruction result from a high-end laser scanner. To the best of our knowledge, it is the first time to present an end-to-end solution to efficient and accurate mapping for AR applications.
Compact 3D Map-Based Monocular Localization Using Semantic Edge Alignment
Mar 27, 2021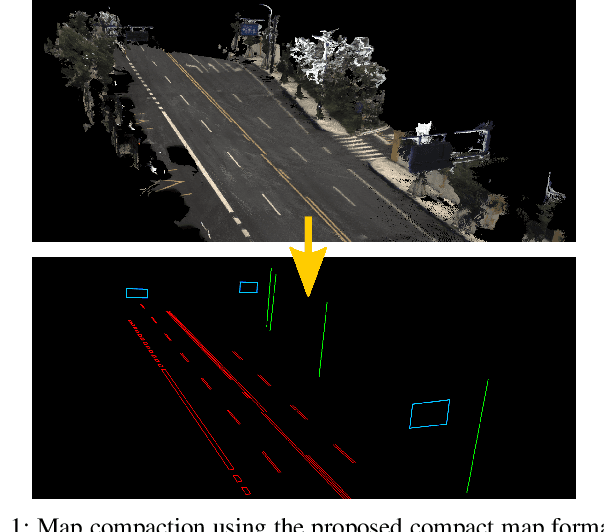
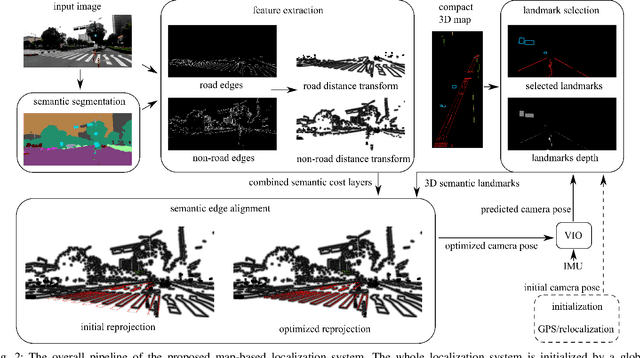

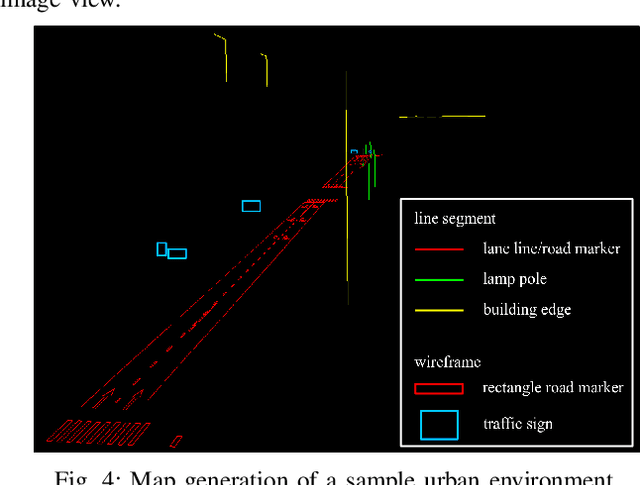
Accurate localization is fundamental to a variety of applications, such as navigation, robotics, autonomous driving, and Augmented Reality (AR). Different from incremental localization, global localization has no drift caused by error accumulation, which is desired in many application scenarios. In addition to GPS used in the open air, 3D maps are also widely used as alternative global localization references. In this paper, we propose a compact 3D map-based global localization system using a low-cost monocular camera and an IMU (Inertial Measurement Unit). The proposed compact map consists of two types of simplified elements with multiple semantic labels, which is well adaptive to various man-made environments like urban environments. Also, semantic edge features are used for the key image-map registration, which is robust against occlusion and long-term appearance changes in the environments. To further improve the localization performance, the key semantic edge alignment is formulated as an optimization problem based on initial poses predicted by an independent VIO (Visual-Inertial Odometry) module. The localization system is realized with modular design in real time. We evaluate the localization accuracy through real-world experimental results compared with ground truth, long-term localization performance is also demonstrated.