 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Lane Segment Perception and Topology Reasoning with Crowdsourcing Trajectory Priors
Nov 26, 2024In autonomous driving, recent advances in lane segment perception provide autonomous vehicles with a comprehensive understanding of driving scenarios. Moreover, incorporating prior information input into such perception model represents an effective approach to ensure the robustness and accuracy. However, utilizing diverse sources of prior information still faces three key challenges: the acquisition of high-quality prior information, alignment between prior and online perception, efficient integration. To address these issues, we investigate prior augmentation from a novel perspective of trajectory priors. In this paper, we initially extract crowdsourcing trajectory data from Argoverse2 motion forecasting dataset and encode trajectory data into rasterized heatmap and vectorized instance tokens, then we incorporate such prior information into the online mapping model through different ways. Besides, with the purpose of mitigating the misalignment between prior and online perception, we design a confidence-based fusion module that takes alignment into account during the fusion process. We conduct extensive experiments on OpenLane-V2 dataset. The results indicate that our method's performance significantly outperforms the current state-of-the-art methods.
DiffMap: Enhancing Map Segmentation with Map Prior Using Diffusion Model
May 03, 2024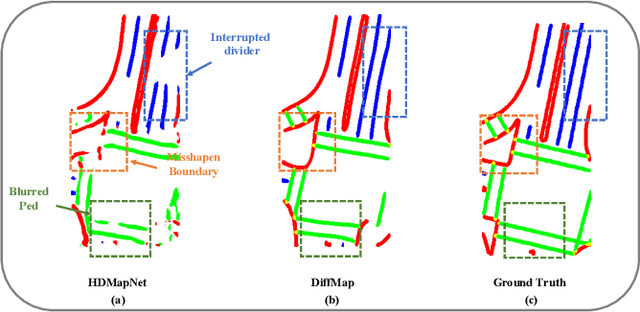
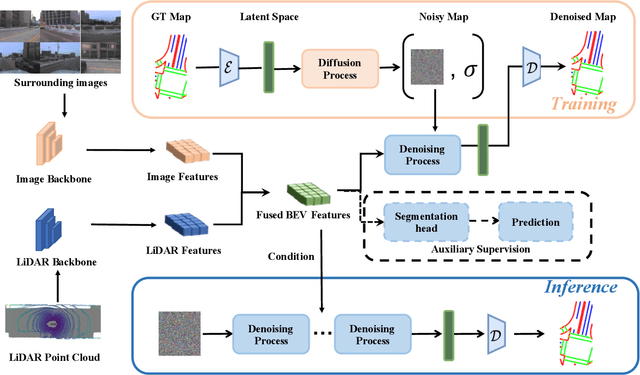
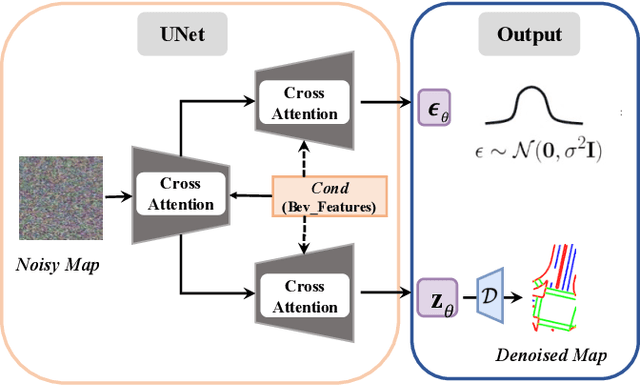

Constructing high-definition (HD) maps is a crucial requirement for enabling autonomous driving. In recent years, several map segmentation algorithms have been developed to address this need, leveraging advancements in Bird's-Eye View (BEV) perception. However, existing models still encounter challenges in producing realistic and consistent semantic map layouts. One prominent issue is the limited utilization of structured priors inherent in map segmentation masks. In light of this, we propose DiffMap, a novel approach specifically designed to model the structured priors of map segmentation masks using latent diffusion model. By incorporating this technique, the performance of existing semantic segmentation methods can be significantly enhanced and certain structural errors present in the segmentation outputs can be effectively rectified. Notably, the proposed module can be seamlessly integrated into any map segmentation model, thereby augmenting its capability to accurately delineate semantic information. Furthermore, through extensive visualization analysis, our model demonstrates superior proficiency in generating results that more accurately reflect real-world map layouts, further validating its efficacy in improving the quality of the generated maps.
LaneSegNet: Map Learning with Lane Segment Perception for Autonomous Driving
Dec 26, 2023A map, as crucial information for downstream applications of an autonomous driving system, is usually represented in lanelines or centerlines. However, existing literature on map learning primarily focuses on either detecting geometry-based lanelines or perceiving topology relationships of centerlines. Both of these methods ignore the intrinsic relationship of lanelines and centerlines, that lanelines bind centerlines. While simply predicting both types of lane in one model is mutually excluded in learning objective, we advocate lane segment as a new representation that seamlessly incorporates both geometry and topology information. Thus, we introduce LaneSegNet, the first end-to-end mapping network generating lane segments to obtain a complete representation of the road structure. Our algorithm features two key modifications. One is a lane attention module to capture pivotal region details within the long-range feature space. Another is an identical initialization strategy for reference points, which enhances the learning of positional priors for lane attention. On the OpenLane-V2 dataset, LaneSegNet outperforms previous counterparts by a substantial gain across three tasks, \textit{i.e.}, map element detection (+4.8 mAP), centerline perception (+6.9 DET$_l$), and the newly defined one, lane segment perception (+5.6 mAP). Furthermore, it obtains a real-time inference speed of 14.7 FPS. Code is accessible at https://github.com/OpenDriveLab/LaneSegNet.