 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWan-Animate: Unified Character Animation and Replacement with Holistic Replication
Sep 17, 2025

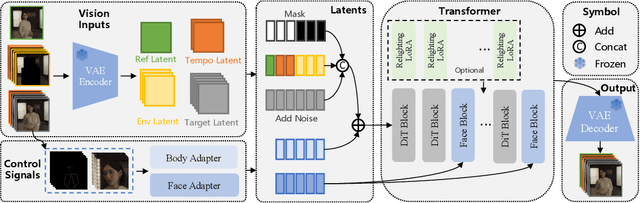
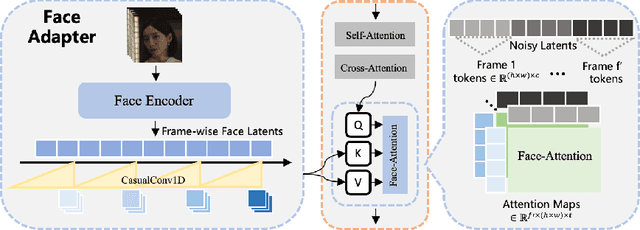
We introduce Wan-Animate, a unified framework for character animation and replacement. Given a character image and a reference video, Wan-Animate can animate the character by precisely replicating the expressions and movements of the character in the video to generate high-fidelity character videos. Alternatively, it can integrate the animated character into the reference video to replace the original character, replicating the scene's lighting and color tone to achieve seamless environmental integration. Wan-Animate is built upon the Wan model. To adapt it for character animation tasks, we employ a modified input paradigm to differentiate between reference conditions and regions for generation. This design unifies multiple tasks into a common symbolic representation. We use spatially-aligned skeleton signals to replicate body motion and implicit facial features extracted from source images to reenact expressions, enabling the generation of character videos with high controllability and expressiveness. Furthermore, to enhance environmental integration during character replacement, we develop an auxiliary Relighting LoRA. This module preserves the character's appearance consistency while applying the appropriate environmental lighting and color tone. Experimental results demonstrate that Wan-Animate achieves state-of-the-art performance. We are committed to open-sourcing the model weights and its source code.
EMO2: End-Effector Guided Audio-Driven Avatar Video Generation
Jan 18, 2025



In this paper, we propose a novel audio-driven talking head method capable of simultaneously generating highly expressive facial expressions and hand gestures. Unlike existing methods that focus on generating full-body or half-body poses, we investigate the challenges of co-speech gesture generation and identify the weak correspondence between audio features and full-body gestures as a key limitation. To address this, we redefine the task as a two-stage process. In the first stage, we generate hand poses directly from audio input, leveraging the strong correlation between audio signals and hand movements. In the second stage, we employ a diffusion model to synthesize video frames, incorporating the hand poses generated in the first stage to produce realistic facial expressions and body movements. Our experimental results demonstrate that the proposed method outperforms state-of-the-art approaches, such as CyberHost and Vlogger, in terms of both visual quality and synchronization accuracy. This work provides a new perspective on audio-driven gesture generation and a robust framework for creating expressive and natural talking head animations.
OutfitAnyone: Ultra-high Quality Virtual Try-On for Any Clothing and Any Person
Jul 23, 2024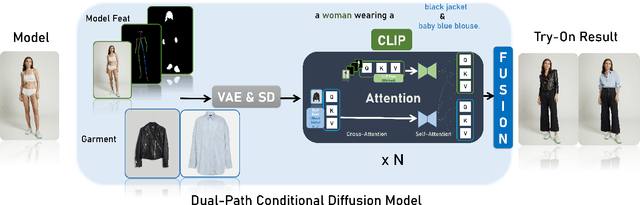
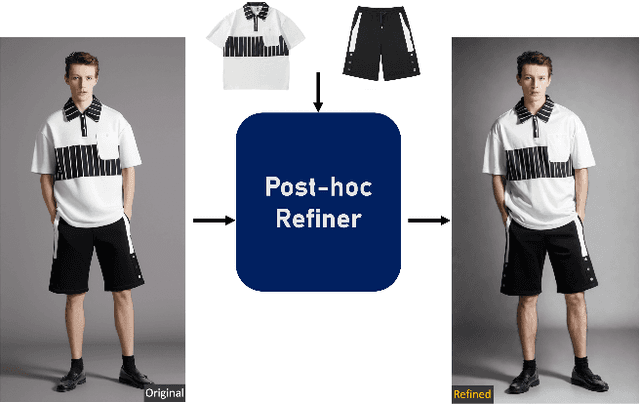


Virtual Try-On (VTON) has become a transformative technology, empowering users to experiment with fashion without ever having to physically try on clothing. However, existing methods often struggle with generating high-fidelity and detail-consistent results. While diffusion models, such as Stable Diffusion series, have shown their capability in creating high-quality and photorealistic images, they encounter formidable challenges in conditional generation scenarios like VTON. Specifically, these models struggle to maintain a balance between control and consistency when generating images for virtual clothing trials. OutfitAnyone addresses these limitations by leveraging a two-stream conditional diffusion model, enabling it to adeptly handle garment deformation for more lifelike results. It distinguishes itself with scalability-modulating factors such as pose, body shape and broad applicability, extending from anime to in-the-wild images. OutfitAnyone's performance in diverse scenarios underscores its utility and readiness for real-world deployment. For more details and animated results, please see \url{https://humanaigc.github.io/outfit-anyone/}.
EMO: Emote Portrait Alive - Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions
Feb 27, 2024In this work, we tackle the challenge of enhancing the realism and expressiveness in talking head video generation by focusing on the dynamic and nuanced relationship between audio cues and facial movements. We identify the limitations of traditional techniques that often fail to capture the full spectrum of human expressions and the uniqueness of individual facial styles. To address these issues, we propose EMO, a novel framework that utilizes a direct audio-to-video synthesis approach, bypassing the need for intermediate 3D models or facial landmarks. Our method ensures seamless frame transitions and consistent identity preservation throughout the video, resulting in highly expressive and lifelike animations. Experimental results demonsrate that EMO is able to produce not only convincing speaking videos but also singing videos in various styles, significantly outperforming existing state-of-the-art methodologies in terms of expressiveness and realism.
RenderIH: A Large-scale Synthetic Dataset for 3D Interacting Hand Pose Estimation
Sep 27, 2023The current interacting hand (IH) datasets are relatively simplistic in terms of background and texture, with hand joints being annotated by a machine annotator, which may result in inaccuracies, and the diversity of pose distribution is limited. However, the variability of background, pose distribution, and texture can greatly influence the generalization ability. Therefore, we present a large-scale synthetic dataset RenderIH for interacting hands with accurate and diverse pose annotations. The dataset contains 1M photo-realistic images with varied backgrounds, perspectives, and hand textures. To generate natural and diverse interacting poses, we propose a new pose optimization algorithm. Additionally, for better pose estimation accuracy, we introduce a transformer-based pose estimation network, TransHand, to leverage the correlation between interacting hands and verify the effectiveness of RenderIH in improving results. Our dataset is model-agnostic and can improve more accuracy of any hand pose estimation method in comparison to other real or synthetic datasets. Experiments have shown that pretraining on our synthetic data can significantly decrease the error from 6.76mm to 5.79mm, and our Transhand surpasses contemporary methods. Our dataset and code are available at https://github.com/adwardlee/RenderIH.