 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM$^2$-Miner: Multi-Agent Enhanced MCTS for Mobile GUI Agent Data Mining
Feb 05, 2026Graphical User Interface (GUI) agent is pivotal to advancing intelligent human-computer interaction paradigms. Constructing powerful GUI agents necessitates the large-scale annotation of high-quality user-behavior trajectory data (i.e., intent-trajectory pairs) for training. However, manual annotation methods and current GUI agent data mining approaches typically face three critical challenges: high construction cost, poor data quality, and low data richness. To address these issues, we propose M$^2$-Miner, the first low-cost and automated mobile GUI agent data-mining framework based on Monte Carlo Tree Search (MCTS). For better data mining efficiency and quality, we present a collaborative multi-agent framework, comprising InferAgent, OrchestraAgent, and JudgeAgent for guidance, acceleration, and evaluation. To further enhance the efficiency of mining and enrich intent diversity, we design an intent recycling strategy to extract extra valuable interaction trajectories. Additionally, a progressive model-in-the-loop training strategy is introduced to improve the success rate of data mining. Extensive experiments have demonstrated that the GUI agent fine-tuned using our mined data achieves state-of-the-art performance on several commonly used mobile GUI benchmarks. Our work will be released to facilitate the community research.
SparkUI-Parser: Enhancing GUI Perception with Robust Grounding and Parsing
Sep 05, 2025The existing Multimodal Large Language Models (MLLMs) for GUI perception have made great progress. However, the following challenges still exist in prior methods: 1) They model discrete coordinates based on text autoregressive mechanism, which results in lower grounding accuracy and slower inference speed. 2) They can only locate predefined sets of elements and are not capable of parsing the entire interface, which hampers the broad application and support for downstream tasks. To address the above issues, we propose SparkUI-Parser, a novel end-to-end framework where higher localization precision and fine-grained parsing capability of the entire interface are simultaneously achieved. Specifically, instead of using probability-based discrete modeling, we perform continuous modeling of coordinates based on a pre-trained Multimodal Large Language Model (MLLM) with an additional token router and coordinate decoder. This effectively mitigates the limitations inherent in the discrete output characteristics and the token-by-token generation process of MLLMs, consequently boosting both the accuracy and the inference speed. To further enhance robustness, a rejection mechanism based on a modified Hungarian matching algorithm is introduced, which empowers the model to identify and reject non-existent elements, thereby reducing false positives. Moreover, we present ScreenParse, a rigorously constructed benchmark to systematically assess structural perception capabilities of GUI models across diverse scenarios. Extensive experiments demonstrate that our approach consistently outperforms SOTA methods on ScreenSpot, ScreenSpot-v2, CAGUI-Grounding and ScreenParse benchmarks. The resources are available at https://github.com/antgroup/SparkUI-Parser.
GaussianUpdate: Continual 3D Gaussian Splatting Update for Changing Environments
Aug 12, 2025Novel view synthesis with neural models has advanced rapidly in recent years, yet adapting these models to scene changes remains an open problem. Existing methods are either labor-intensive, requiring extensive model retraining, or fail to capture detailed types of changes over time. In this paper, we present GaussianUpdate, a novel approach that combines 3D Gaussian representation with continual learning to address these challenges. Our method effectively updates the Gaussian radiance fields with current data while preserving information from past scenes. Unlike existing methods, GaussianUpdate explicitly models different types of changes through a novel multi-stage update strategy. Additionally, we introduce a visibility-aware continual learning approach with generative replay, enabling self-aware updating without the need to store images. The experiments on the benchmark dataset demonstrate our method achieves superior and real-time rendering with the capability of visualizing changes over different times
SemTalk: Holistic Co-speech Motion Generation with Frame-level Semantic Emphasis
Dec 21, 2024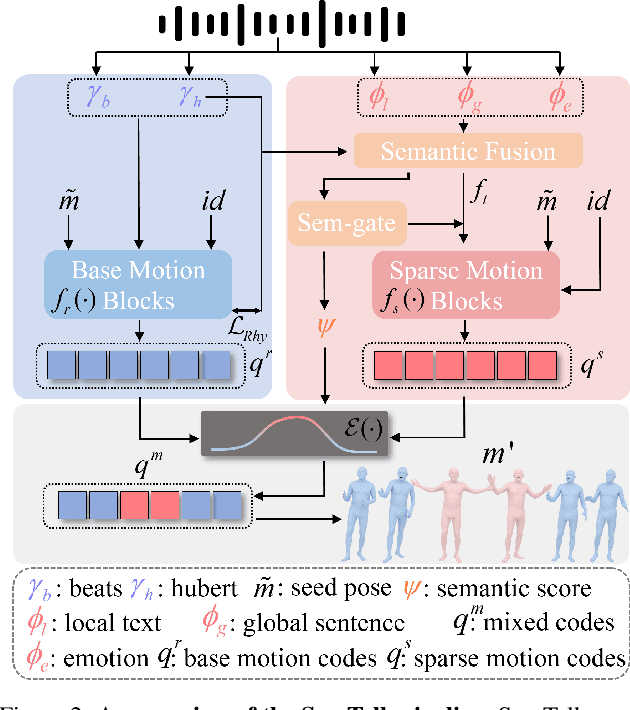
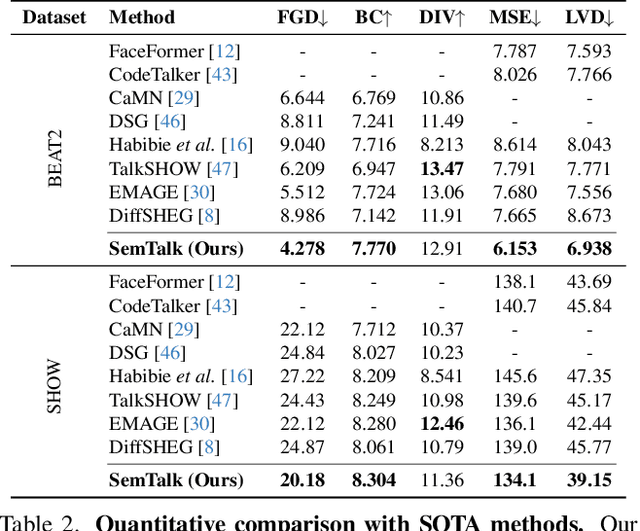
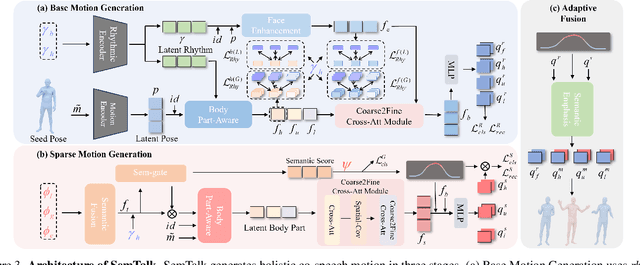

A good co-speech motion generation cannot be achieved without a careful integration of common rhythmic motion and rare yet essential semantic motion. In this work, we propose SemTalk for holistic co-speech motion generation with frame-level semantic emphasis. Our key insight is to separately learn general motions and sparse motions, and then adaptively fuse them. In particular, rhythmic consistency learning is explored to establish rhythm-related base motion, ensuring a coherent foundation that synchronizes gestures with the speech rhythm. Subsequently, textit{semantic emphasis learning is designed to generate semantic-aware sparse motion, focusing on frame-level semantic cues. Finally, to integrate sparse motion into the base motion and generate semantic-emphasized co-speech gestures, we further leverage a learned semantic score for adaptive synthesis. Qualitative and quantitative comparisons on two public datasets demonstrate that our method outperforms the state-of-the-art, delivering high-quality co-speech motion with enhanced semantic richness over a stable base motion.
Cascaded Dual Vision Transformer for Accurate Facial Landmark Detection
Nov 08, 2024Facial landmark detection is a fundamental problem in computer vision for many downstream applications. This paper introduces a new facial landmark detector based on vision transformers, which consists of two unique designs: Dual Vision Transformer (D-ViT) and Long Skip Connections (LSC). Based on the observation that the channel dimension of feature maps essentially represents the linear bases of the heatmap space, we propose learning the interconnections between these linear bases to model the inherent geometric relations among landmarks via Channel-split ViT. We integrate such channel-split ViT into the standard vision transformer (i.e., spatial-split ViT), forming our Dual Vision Transformer to constitute the prediction blocks. We also suggest using long skip connections to deliver low-level image features to all prediction blocks, thereby preventing useful information from being discarded by intermediate supervision. Extensive experiments are conducted to evaluate the performance of our proposal on the widely used benchmarks, i.e., WFLW, COFW, and 300W, demonstrating that our model outperforms the previous SOTAs across all three benchmarks.
TexPro: Text-guided PBR Texturing with Procedural Material Modeling
Oct 21, 2024
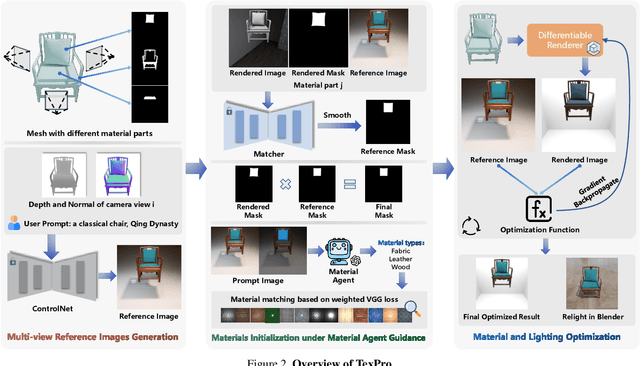
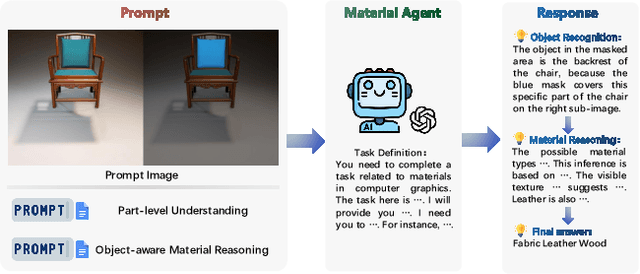
In this paper, we present TexPro, a novel method for high-fidelity material generation for input 3D meshes given text prompts. Unlike existing text-conditioned texture generation methods that typically generate RGB textures with baked lighting, TexPro is able to produce diverse texture maps via procedural material modeling, which enables physical-based rendering, relighting, and additional benefits inherent to procedural materials. Specifically, we first generate multi-view reference images given the input textual prompt by employing the latest text-to-image model. We then derive texture maps through a rendering-based optimization with recent differentiable procedural materials. To this end, we design several techniques to handle the misalignment between the generated multi-view images and 3D meshes, and introduce a novel material agent that enhances material classification and matching by exploring both part-level understanding and object-aware material reasoning. Experiments demonstrate the superiority of the proposed method over existing SOTAs and its capability of relighting.
MoManifold: Learning to Measure 3D Human Motion via Decoupled Joint Acceleration Manifolds
Sep 01, 2024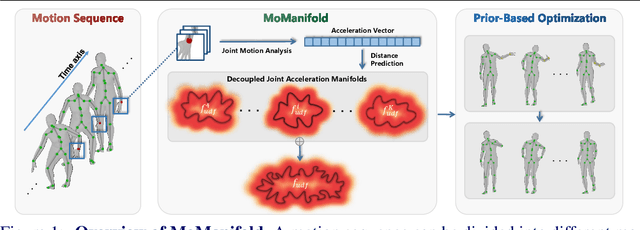
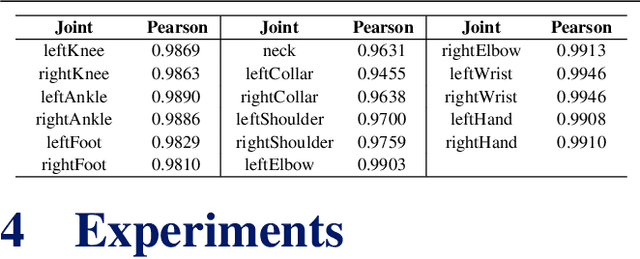


Incorporating temporal information effectively is important for accurate 3D human motion estimation and generation which have wide applications from human-computer interaction to AR/VR. In this paper, we present MoManifold, a novel human motion prior, which models plausible human motion in continuous high-dimensional motion space. Different from existing mathematical or VAE-based methods, our representation is designed based on the neural distance field, which makes human dynamics explicitly quantified to a score and thus can measure human motion plausibility. Specifically, we propose novel decoupled joint acceleration manifolds to model human dynamics from existing limited motion data. Moreover, we introduce a novel optimization method using the manifold distance as guidance, which facilitates a variety of motion-related tasks. Extensive experiments demonstrate that MoManifold outperforms existing SOTAs as a prior in several downstream tasks such as denoising real-world human mocap data, recovering human motion from partial 3D observations, mitigating jitters for SMPL-based pose estimators, and refining the results of motion in-betweening.