 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRespond to Change with Constancy: Instruction-tuning with LLM for Non-I.I.D. Network Traffic Classification
May 27, 2025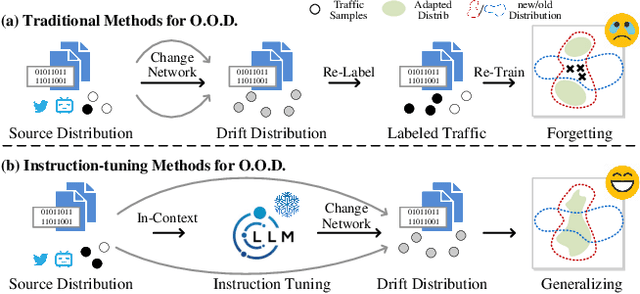
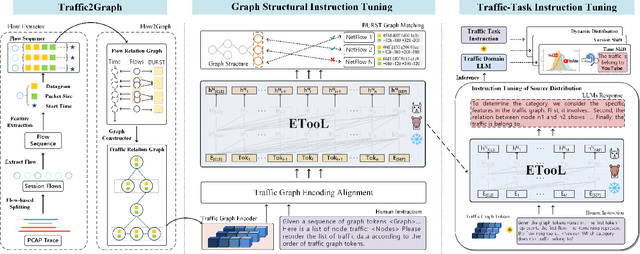
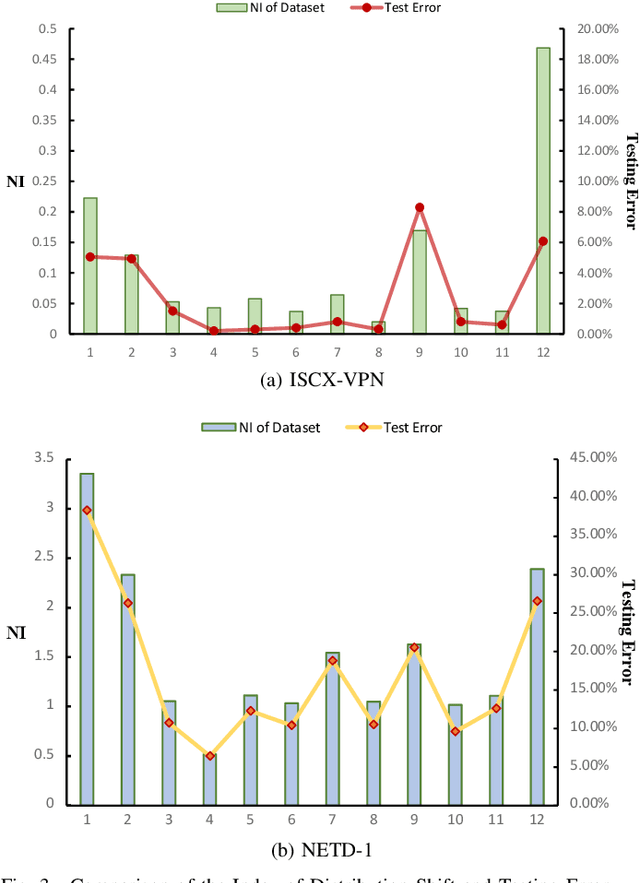
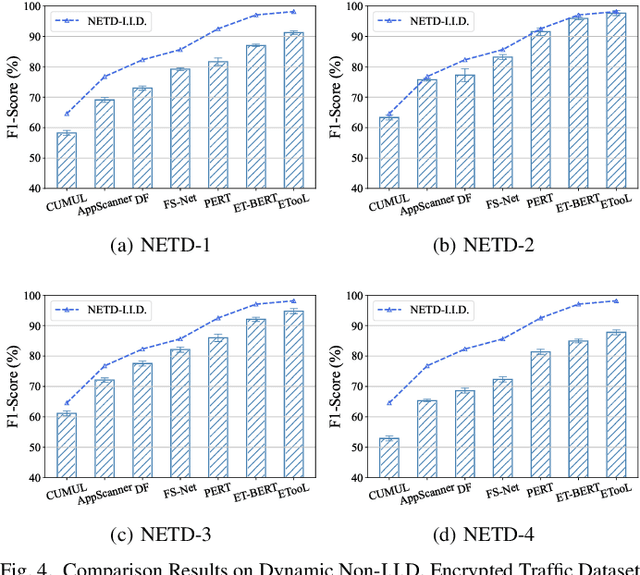
Encrypted traffic classification is highly challenging in network security due to the need for extracting robust features from content-agnostic traffic data. Existing approaches face critical issues: (i) Distribution drift, caused by reliance on the closedworld assumption, limits adaptability to realworld, shifting patterns; (ii) Dependence on labeled data restricts applicability where such data is scarce or unavailable. Large language models (LLMs) have demonstrated remarkable potential in offering generalizable solutions across a wide range of tasks, achieving notable success in various specialized fields. However, their effectiveness in traffic analysis remains constrained by challenges in adapting to the unique requirements of the traffic domain. In this paper, we introduce a novel traffic representation model named Encrypted Traffic Out-of-Distribution Instruction Tuning with LLM (ETooL), which integrates LLMs with knowledge of traffic structures through a self-supervised instruction tuning paradigm. This framework establishes connections between textual information and traffic interactions. ETooL demonstrates more robust classification performance and superior generalization in both supervised and zero-shot traffic classification tasks. Notably, it achieves significant improvements in F1 scores: APP53 (I.I.D.) to 93.19%(6.62%) and 92.11%(4.19%), APP53 (O.O.D.) to 74.88%(18.17%) and 72.13%(15.15%), and ISCX-Botnet (O.O.D.) to 95.03%(9.16%) and 81.95%(12.08%). Additionally, we construct NETD, a traffic dataset designed to support dynamic distributional shifts, and use it to validate ETooL's effectiveness under varying distributional conditions. Furthermore, we evaluate the efficiency gains achieved through ETooL's instruction tuning approach.
HiScene: Creating Hierarchical 3D Scenes with Isometric View Generation
Apr 17, 2025Scene-level 3D generation represents a critical frontier in multimedia and computer graphics, yet existing approaches either suffer from limited object categories or lack editing flexibility for interactive applications. In this paper, we present HiScene, a novel hierarchical framework that bridges the gap between 2D image generation and 3D object generation and delivers high-fidelity scenes with compositional identities and aesthetic scene content. Our key insight is treating scenes as hierarchical "objects" under isometric views, where a room functions as a complex object that can be further decomposed into manipulatable items. This hierarchical approach enables us to generate 3D content that aligns with 2D representations while maintaining compositional structure. To ensure completeness and spatial alignment of each decomposed instance, we develop a video-diffusion-based amodal completion technique that effectively handles occlusions and shadows between objects, and introduce shape prior injection to ensure spatial coherence within the scene. Experimental results demonstrate that our method produces more natural object arrangements and complete object instances suitable for interactive applications, while maintaining physical plausibility and alignment with user inputs.
CFSynthesis: Controllable and Free-view 3D Human Video Synthesis
Dec 17, 2024



Human video synthesis aims to create lifelike characters in various environments, with wide applications in VR, storytelling, and content creation. While 2D diffusion-based methods have made significant progress, they struggle to generalize to complex 3D poses and varying scene backgrounds. To address these limitations, we introduce CFSynthesis, a novel framework for generating high-quality human videos with customizable attributes, including identity, motion, and scene configurations. Our method leverages a texture-SMPL-based representation to ensure consistent and stable character appearances across free viewpoints. Additionally, we introduce a novel foreground-background separation strategy that effectively decomposes the scene as foreground and background, enabling seamless integration of user-defined backgrounds. Experimental results on multiple datasets show that CFSynthesis not only achieves state-of-the-art performance in complex human animations but also adapts effectively to 3D motions in free-view and user-specified scenarios.
TexPro: Text-guided PBR Texturing with Procedural Material Modeling
Oct 21, 2024
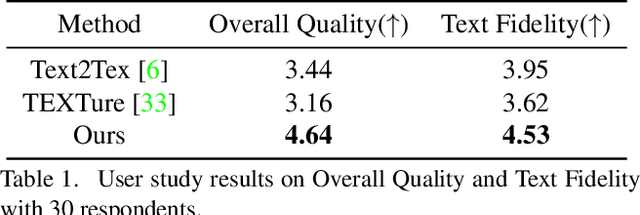
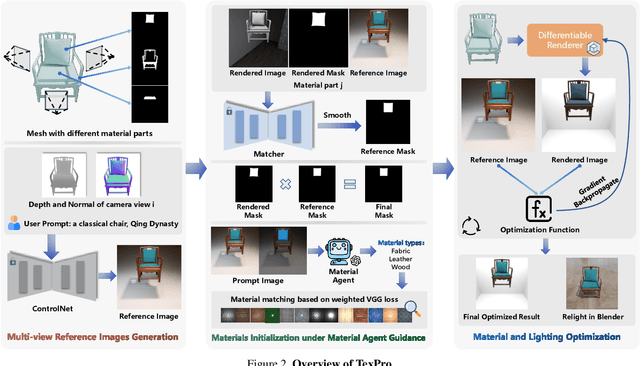
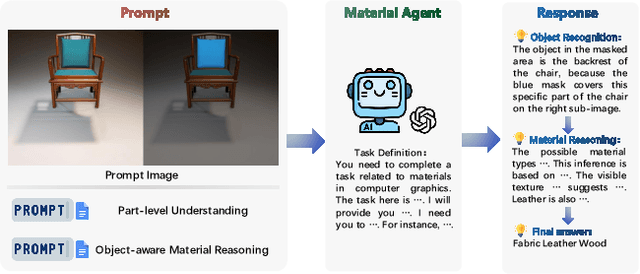
In this paper, we present TexPro, a novel method for high-fidelity material generation for input 3D meshes given text prompts. Unlike existing text-conditioned texture generation methods that typically generate RGB textures with baked lighting, TexPro is able to produce diverse texture maps via procedural material modeling, which enables physical-based rendering, relighting, and additional benefits inherent to procedural materials. Specifically, we first generate multi-view reference images given the input textual prompt by employing the latest text-to-image model. We then derive texture maps through a rendering-based optimization with recent differentiable procedural materials. To this end, we design several techniques to handle the misalignment between the generated multi-view images and 3D meshes, and introduce a novel material agent that enhances material classification and matching by exploring both part-level understanding and object-aware material reasoning. Experiments demonstrate the superiority of the proposed method over existing SOTAs and its capability of relighting.
Coin3D: Controllable and Interactive 3D Assets Generation with Proxy-Guided Conditioning
May 13, 2024As humans, we aspire to create media content that is both freely willed and readily controlled. Thanks to the prominent development of generative techniques, we now can easily utilize 2D diffusion methods to synthesize images controlled by raw sketch or designated human poses, and even progressively edit/regenerate local regions with masked inpainting. However, similar workflows in 3D modeling tasks are still unavailable due to the lack of controllability and efficiency in 3D generation. In this paper, we present a novel controllable and interactive 3D assets modeling framework, named Coin3D. Coin3D allows users to control the 3D generation using a coarse geometry proxy assembled from basic shapes, and introduces an interactive generation workflow to support seamless local part editing while delivering responsive 3D object previewing within a few seconds. To this end, we develop several techniques, including the 3D adapter that applies volumetric coarse shape control to the diffusion model, proxy-bounded editing strategy for precise part editing, progressive volume cache to support responsive preview, and volume-SDS to ensure consistent mesh reconstruction. Extensive experiments of interactive generation and editing on diverse shape proxies demonstrate that our method achieves superior controllability and flexibility in the 3D assets generation task.
DreamSpace: Dreaming Your Room Space with Text-Driven Panoramic Texture Propagation
Oct 19, 2023



Diffusion-based methods have achieved prominent success in generating 2D media. However, accomplishing similar proficiencies for scene-level mesh texturing in 3D spatial applications, e.g., XR/VR, remains constrained, primarily due to the intricate nature of 3D geometry and the necessity for immersive free-viewpoint rendering. In this paper, we propose a novel indoor scene texturing framework, which delivers text-driven texture generation with enchanting details and authentic spatial coherence. The key insight is to first imagine a stylized 360{\deg} panoramic texture from the central viewpoint of the scene, and then propagate it to the rest areas with inpainting and imitating techniques. To ensure meaningful and aligned textures to the scene, we develop a novel coarse-to-fine panoramic texture generation approach with dual texture alignment, which both considers the geometry and texture cues of the captured scenes. To survive from cluttered geometries during texture propagation, we design a separated strategy, which conducts texture inpainting in confidential regions and then learns an implicit imitating network to synthesize textures in occluded and tiny structural areas. Extensive experiments and the immersive VR application on real-world indoor scenes demonstrate the high quality of the generated textures and the engaging experience on VR headsets. Project webpage: https://ybbbbt.com/publication/dreamspace
DELTAR: Depth Estimation from a Light-weight ToF Sensor and RGB Image
Sep 27, 2022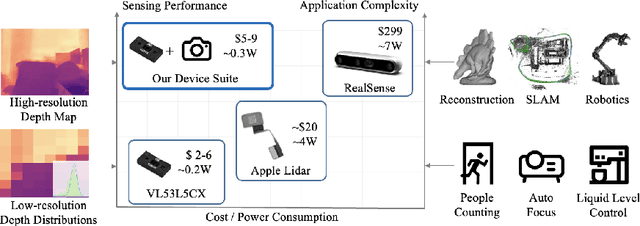
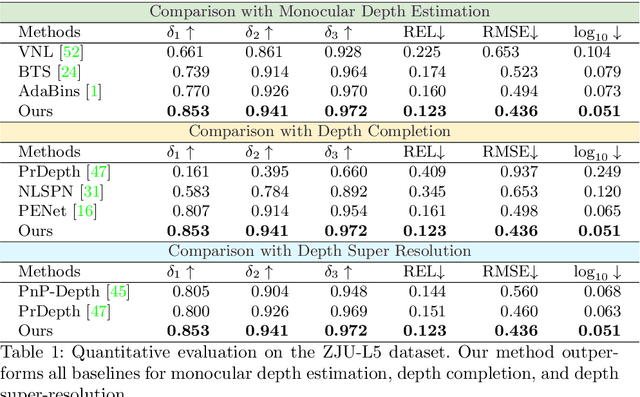
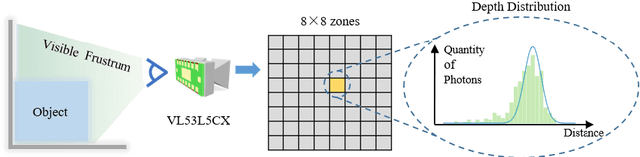
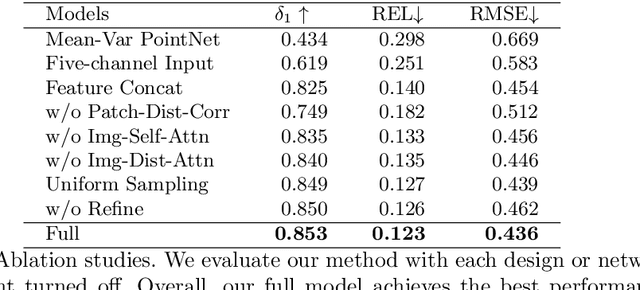
Light-weight time-of-flight (ToF) depth sensors are small, cheap, low-energy and have been massively deployed on mobile devices for the purposes like autofocus, obstacle detection, etc. However, due to their specific measurements (depth distribution in a region instead of the depth value at a certain pixel) and extremely low resolution, they are insufficient for applications requiring high-fidelity depth such as 3D reconstruction. In this paper, we propose DELTAR, a novel method to empower light-weight ToF sensors with the capability of measuring high resolution and accurate depth by cooperating with a color image. As the core of DELTAR, a feature extractor customized for depth distribution and an attention-based neural architecture is proposed to fuse the information from the color and ToF domain efficiently. To evaluate our system in real-world scenarios, we design a data collection device and propose a new approach to calibrate the RGB camera and ToF sensor. Experiments show that our method produces more accurate depth than existing frameworks designed for depth completion and depth super-resolution and achieves on par performance with a commodity-level RGB-D sensor. Code and data are available at https://zju3dv.github.io/deltar/.