 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKling-Avatar: Grounding Multimodal Instructions for Cascaded Long-Duration Avatar Animation Synthesis
Sep 11, 2025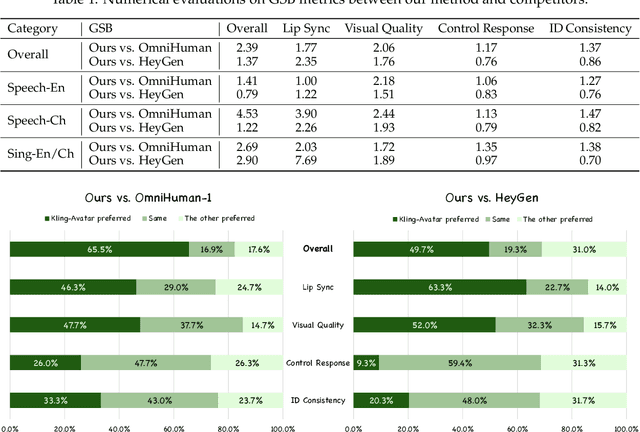
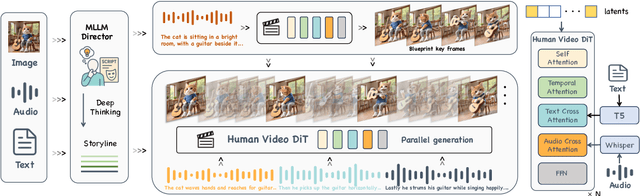


Recent advances in audio-driven avatar video generation have significantly enhanced audio-visual realism. However, existing methods treat instruction conditioning merely as low-level tracking driven by acoustic or visual cues, without modeling the communicative purpose conveyed by the instructions. This limitation compromises their narrative coherence and character expressiveness. To bridge this gap, we introduce Kling-Avatar, a novel cascaded framework that unifies multimodal instruction understanding with photorealistic portrait generation. Our approach adopts a two-stage pipeline. In the first stage, we design a multimodal large language model (MLLM) director that produces a blueprint video conditioned on diverse instruction signals, thereby governing high-level semantics such as character motion and emotions. In the second stage, guided by blueprint keyframes, we generate multiple sub-clips in parallel using a first-last frame strategy. This global-to-local framework preserves fine-grained details while faithfully encoding the high-level intent behind multimodal instructions. Our parallel architecture also enables fast and stable generation of long-duration videos, making it suitable for real-world applications such as digital human livestreaming and vlogging. To comprehensively evaluate our method, we construct a benchmark of 375 curated samples covering diverse instructions and challenging scenarios. Extensive experiments demonstrate that Kling-Avatar is capable of generating vivid, fluent, long-duration videos at up to 1080p and 48 fps, achieving superior performance in lip synchronization accuracy, emotion and dynamic expressiveness, instruction controllability, identity preservation, and cross-domain generalization. These results establish Kling-Avatar as a new benchmark for semantically grounded, high-fidelity audio-driven avatar synthesis.
MIDAS: Multimodal Interactive Digital-humAn Synthesis via Real-time Autoregressive Video Generation
Aug 28, 2025Recently, interactive digital human video generation has attracted widespread attention and achieved remarkable progress. However, building such a practical system that can interact with diverse input signals in real time remains challenging to existing methods, which often struggle with heavy computational cost and limited controllability. In this work, we introduce an autoregressive video generation framework that enables interactive multimodal control and low-latency extrapolation in a streaming manner. With minimal modifications to a standard large language model (LLM), our framework accepts multimodal condition encodings including audio, pose, and text, and outputs spatially and semantically coherent representations to guide the denoising process of a diffusion head. To support this, we construct a large-scale dialogue dataset of approximately 20,000 hours from multiple sources, providing rich conversational scenarios for training. We further introduce a deep compression autoencoder with up to 64$\times$ reduction ratio, which effectively alleviates the long-horizon inference burden of the autoregressive model. Extensive experiments on duplex conversation, multilingual human synthesis, and interactive world model highlight the advantages of our approach in low latency, high efficiency, and fine-grained multimodal controllability.
CFSynthesis: Controllable and Free-view 3D Human Video Synthesis
Dec 17, 2024



Human video synthesis aims to create lifelike characters in various environments, with wide applications in VR, storytelling, and content creation. While 2D diffusion-based methods have made significant progress, they struggle to generalize to complex 3D poses and varying scene backgrounds. To address these limitations, we introduce CFSynthesis, a novel framework for generating high-quality human videos with customizable attributes, including identity, motion, and scene configurations. Our method leverages a texture-SMPL-based representation to ensure consistent and stable character appearances across free viewpoints. Additionally, we introduce a novel foreground-background separation strategy that effectively decomposes the scene as foreground and background, enabling seamless integration of user-defined backgrounds. Experimental results on multiple datasets show that CFSynthesis not only achieves state-of-the-art performance in complex human animations but also adapts effectively to 3D motions in free-view and user-specified scenarios.
Coin3D: Controllable and Interactive 3D Assets Generation with Proxy-Guided Conditioning
May 13, 2024As humans, we aspire to create media content that is both freely willed and readily controlled. Thanks to the prominent development of generative techniques, we now can easily utilize 2D diffusion methods to synthesize images controlled by raw sketch or designated human poses, and even progressively edit/regenerate local regions with masked inpainting. However, similar workflows in 3D modeling tasks are still unavailable due to the lack of controllability and efficiency in 3D generation. In this paper, we present a novel controllable and interactive 3D assets modeling framework, named Coin3D. Coin3D allows users to control the 3D generation using a coarse geometry proxy assembled from basic shapes, and introduces an interactive generation workflow to support seamless local part editing while delivering responsive 3D object previewing within a few seconds. To this end, we develop several techniques, including the 3D adapter that applies volumetric coarse shape control to the diffusion model, proxy-bounded editing strategy for precise part editing, progressive volume cache to support responsive preview, and volume-SDS to ensure consistent mesh reconstruction. Extensive experiments of interactive generation and editing on diverse shape proxies demonstrate that our method achieves superior controllability and flexibility in the 3D assets generation task.