 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$ abla$-SDF: Learning Euclidean Signed Distance Functions Online with Gradient-Augmented Octree Interpolation and Neural Residual
Oct 21, 2025Estimation of signed distance functions (SDFs) from point cloud data has been shown to benefit many robot autonomy capabilities, including localization, mapping, motion planning, and control. Methods that support online and large-scale SDF reconstruction tend to rely on discrete volumetric data structures, which affect the continuity and differentiability of the SDF estimates. Recently, using implicit features, neural network methods have demonstrated high-fidelity and differentiable SDF reconstruction but they tend to be less efficient, can experience catastrophic forgetting and memory limitations in large environments, and are often restricted to truncated SDFs. This work proposes $\nabla$-SDF, a hybrid method that combines an explicit prior obtained from gradient-augmented octree interpolation with an implicit neural residual. Our method achieves non-truncated (Euclidean) SDF reconstruction with computational and memory efficiency comparable to volumetric methods and differentiability and accuracy comparable to neural network methods. Extensive experiments demonstrate that \methodname{} outperforms the state of the art in terms of accuracy and efficiency, providing a scalable solution for downstream tasks in robotics and computer vision.
MoManifold: Learning to Measure 3D Human Motion via Decoupled Joint Acceleration Manifolds
Sep 01, 2024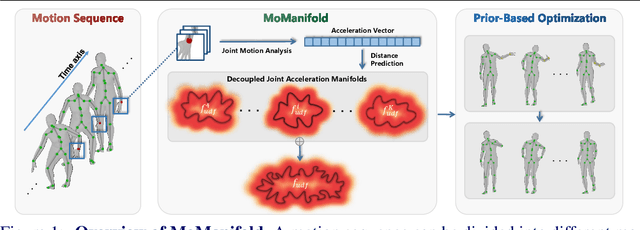
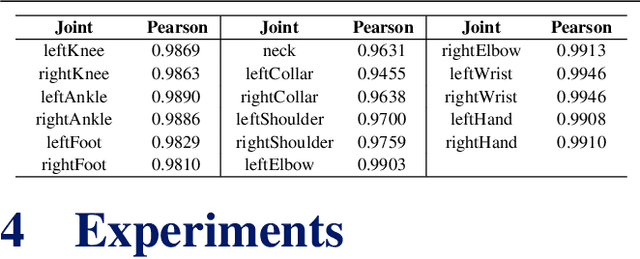


Incorporating temporal information effectively is important for accurate 3D human motion estimation and generation which have wide applications from human-computer interaction to AR/VR. In this paper, we present MoManifold, a novel human motion prior, which models plausible human motion in continuous high-dimensional motion space. Different from existing mathematical or VAE-based methods, our representation is designed based on the neural distance field, which makes human dynamics explicitly quantified to a score and thus can measure human motion plausibility. Specifically, we propose novel decoupled joint acceleration manifolds to model human dynamics from existing limited motion data. Moreover, we introduce a novel optimization method using the manifold distance as guidance, which facilitates a variety of motion-related tasks. Extensive experiments demonstrate that MoManifold outperforms existing SOTAs as a prior in several downstream tasks such as denoising real-world human mocap data, recovering human motion from partial 3D observations, mitigating jitters for SMPL-based pose estimators, and refining the results of motion in-betweening.
SINE: Semantic-driven Image-based NeRF Editing with Prior-guided Editing Field
Mar 25, 2023



Despite the great success in 2D editing using user-friendly tools, such as Photoshop, semantic strokes, or even text prompts, similar capabilities in 3D areas are still limited, either relying on 3D modeling skills or allowing editing within only a few categories. In this paper, we present a novel semantic-driven NeRF editing approach, which enables users to edit a neural radiance field with a single image, and faithfully delivers edited novel views with high fidelity and multi-view consistency. To achieve this goal, we propose a prior-guided editing field to encode fine-grained geometric and texture editing in 3D space, and develop a series of techniques to aid the editing process, including cyclic constraints with a proxy mesh to facilitate geometric supervision, a color compositing mechanism to stabilize semantic-driven texture editing, and a feature-cluster-based regularization to preserve the irrelevant content unchanged. Extensive experiments and editing examples on both real-world and synthetic data demonstrate that our method achieves photo-realistic 3D editing using only a single edited image, pushing the bound of semantic-driven editing in 3D real-world scenes. Our project webpage: https://zju3dv.github.io/sine/.
CompNVS: Novel View Synthesis with Scene Completion
Jul 23, 2022

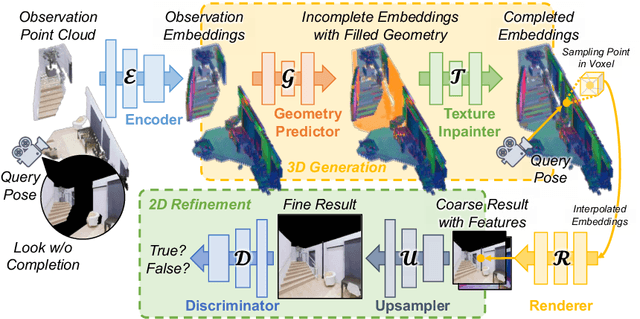

We introduce a scalable framework for novel view synthesis from RGB-D images with largely incomplete scene coverage. While generative neural approaches have demonstrated spectacular results on 2D images, they have not yet achieved similar photorealistic results in combination with scene completion where a spatial 3D scene understanding is essential. To this end, we propose a generative pipeline performing on a sparse grid-based neural scene representation to complete unobserved scene parts via a learned distribution of scenes in a 2.5D-3D-2.5D manner. We process encoded image features in 3D space with a geometry completion network and a subsequent texture inpainting network to extrapolate the missing area. Photorealistic image sequences can be finally obtained via consistency-relevant differentiable rendering. Comprehensive experiments show that the graphical outputs of our method outperform the state of the art, especially within unobserved scene parts.
LatentHuman: Shape-and-Pose Disentangled Latent Representation for Human Bodies
Nov 30, 2021
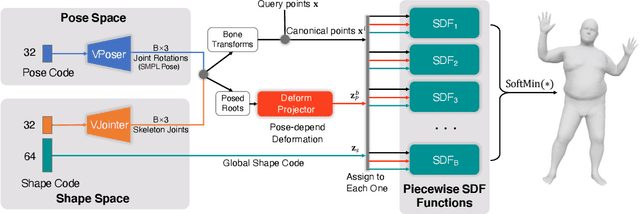
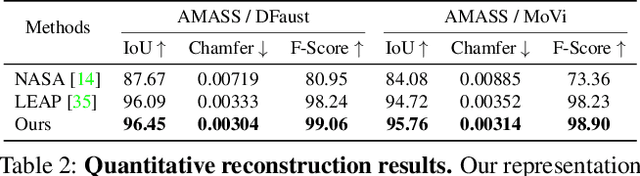

3D representation and reconstruction of human bodies have been studied for a long time in computer vision. Traditional methods rely mostly on parametric statistical linear models, limiting the space of possible bodies to linear combinations. It is only recently that some approaches try to leverage neural implicit representations for human body modeling, and while demonstrating impressive results, they are either limited by representation capability or not physically meaningful and controllable. In this work, we propose a novel neural implicit representation for the human body, which is fully differentiable and optimizable with disentangled shape and pose latent spaces. Contrary to prior work, our representation is designed based on the kinematic model, which makes the representation controllable for tasks like pose animation, while simultaneously allowing the optimization of shape and pose for tasks like 3D fitting and pose tracking. Our model can be trained and fine-tuned directly on non-watertight raw data with well-designed losses. Experiments demonstrate the improved 3D reconstruction performance over SoTA approaches and show the applicability of our method to shape interpolation, model fitting, pose tracking, and motion retargeting.