 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSat2Scene: 3D Urban Scene Generation from Satellite Images with Diffusion
Jan 19, 2024
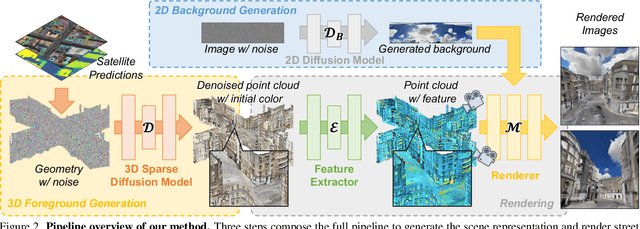
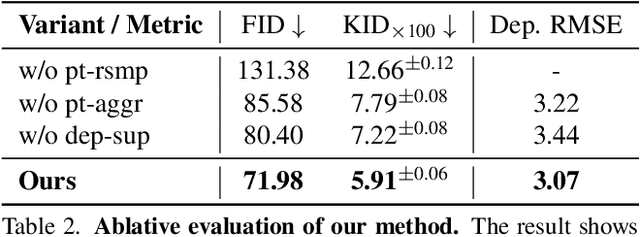

Directly generating scenes from satellite imagery offers exciting possibilities for integration into applications like games and map services. However, challenges arise from significant view changes and scene scale. Previous efforts mainly focused on image or video generation, lacking exploration into the adaptability of scene generation for arbitrary views. Existing 3D generation works either operate at the object level or are difficult to utilize the geometry obtained from satellite imagery. To overcome these limitations, we propose a novel architecture for direct 3D scene generation by introducing diffusion models into 3D sparse representations and combining them with neural rendering techniques. Specifically, our approach generates texture colors at the point level for a given geometry using a 3D diffusion model first, which is then transformed into a scene representation in a feed-forward manner. The representation can be utilized to render arbitrary views which would excel in both single-frame quality and inter-frame consistency. Experiments in two city-scale datasets show that our model demonstrates proficiency in generating photo-realistic street-view image sequences and cross-view urban scenes from satellite imagery.
Surgical tool classification and localization: results and methods from the MICCAI 2022 SurgToolLoc challenge
May 11, 2023



The ability to automatically detect and track surgical instruments in endoscopic videos can enable transformational interventions. Assessing surgical performance and efficiency, identifying skilled tool use and choreography, and planning operational and logistical aspects of OR resources are just a few of the applications that could benefit. Unfortunately, obtaining the annotations needed to train machine learning models to identify and localize surgical tools is a difficult task. Annotating bounding boxes frame-by-frame is tedious and time-consuming, yet large amounts of data with a wide variety of surgical tools and surgeries must be captured for robust training. Moreover, ongoing annotator training is needed to stay up to date with surgical instrument innovation. In robotic-assisted surgery, however, potentially informative data like timestamps of instrument installation and removal can be programmatically harvested. The ability to rely on tool installation data alone would significantly reduce the workload to train robust tool-tracking models. With this motivation in mind we invited the surgical data science community to participate in the challenge, SurgToolLoc 2022. The goal was to leverage tool presence data as weak labels for machine learning models trained to detect tools and localize them in video frames with bounding boxes. We present the results of this challenge along with many of the team's efforts. We conclude by discussing these results in the broader context of machine learning and surgical data science. The training data used for this challenge consisting of 24,695 video clips with tool presence labels is also being released publicly and can be accessed at https://console.cloud.google.com/storage/browser/isi-surgtoolloc-2022.
Surgical Skill Assessment via Video Semantic Aggregation
Aug 04, 2022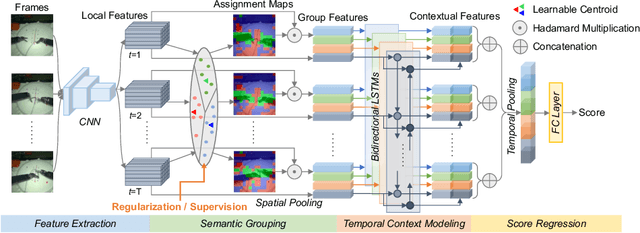
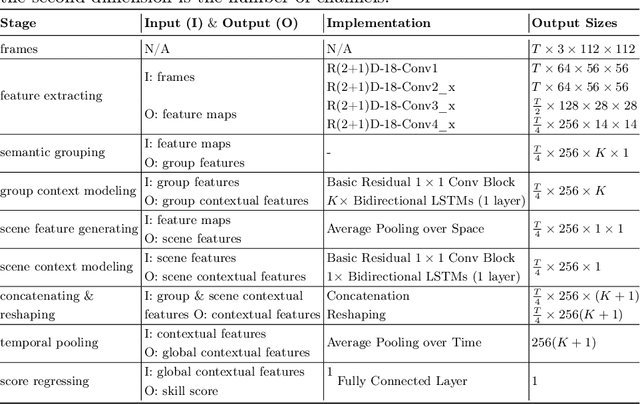
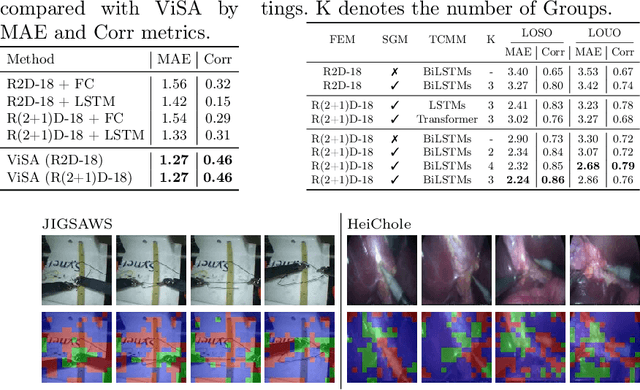
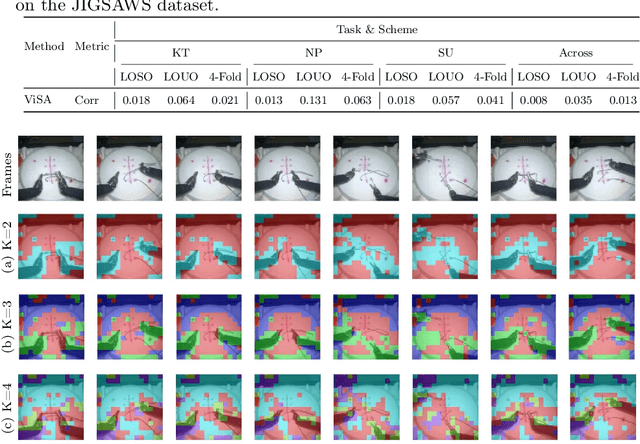
Automated video-based assessment of surgical skills is a promising task in assisting young surgical trainees, especially in poor-resource areas. Existing works often resort to a CNN-LSTM joint framework that models long-term relationships by LSTMs on spatially pooled short-term CNN features. However, this practice would inevitably neglect the difference among semantic concepts such as tools, tissues, and background in the spatial dimension, impeding the subsequent temporal relationship modeling. In this paper, we propose a novel skill assessment framework, Video Semantic Aggregation (ViSA), which discovers different semantic parts and aggregates them across spatiotemporal dimensions. The explicit discovery of semantic parts provides an explanatory visualization that helps understand the neural network's decisions. It also enables us to further incorporate auxiliary information such as the kinematic data to improve representation learning and performance. The experiments on two datasets show the competitiveness of ViSA compared to state-of-the-art methods. Source code is available at: bit.ly/MICCAI2022ViSA.
CompNVS: Novel View Synthesis with Scene Completion
Jul 23, 2022

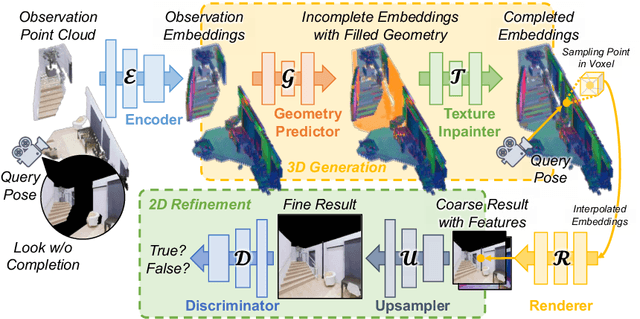

We introduce a scalable framework for novel view synthesis from RGB-D images with largely incomplete scene coverage. While generative neural approaches have demonstrated spectacular results on 2D images, they have not yet achieved similar photorealistic results in combination with scene completion where a spatial 3D scene understanding is essential. To this end, we propose a generative pipeline performing on a sparse grid-based neural scene representation to complete unobserved scene parts via a learned distribution of scenes in a 2.5D-3D-2.5D manner. We process encoded image features in 3D space with a geometry completion network and a subsequent texture inpainting network to extrapolate the missing area. Photorealistic image sequences can be finally obtained via consistency-relevant differentiable rendering. Comprehensive experiments show that the graphical outputs of our method outperform the state of the art, especially within unobserved scene parts.
Ego4D: Around the World in 3,000 Hours of Egocentric Video
Oct 13, 2021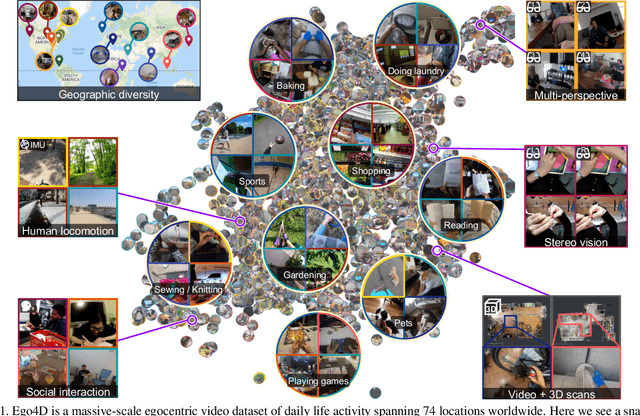
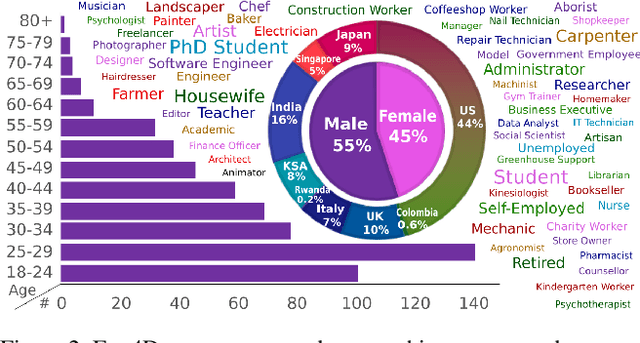

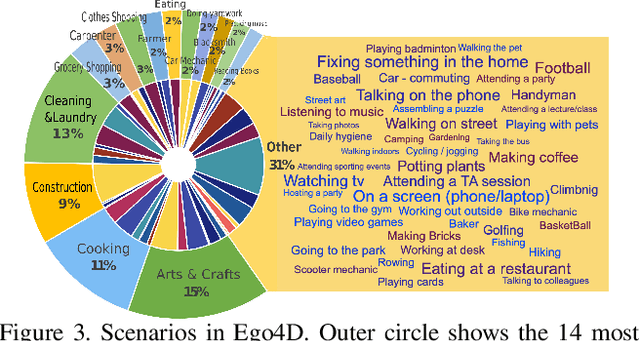
We introduce Ego4D, a massive-scale egocentric video dataset and benchmark suite. It offers 3,025 hours of daily-life activity video spanning hundreds of scenarios (household, outdoor, workplace, leisure, etc.) captured by 855 unique camera wearers from 74 worldwide locations and 9 different countries. The approach to collection is designed to uphold rigorous privacy and ethics standards with consenting participants and robust de-identification procedures where relevant. Ego4D dramatically expands the volume of diverse egocentric video footage publicly available to the research community. Portions of the video are accompanied by audio, 3D meshes of the environment, eye gaze, stereo, and/or synchronized videos from multiple egocentric cameras at the same event. Furthermore, we present a host of new benchmark challenges centered around understanding the first-person visual experience in the past (querying an episodic memory), present (analyzing hand-object manipulation, audio-visual conversation, and social interactions), and future (forecasting activities). By publicly sharing this massive annotated dataset and benchmark suite, we aim to push the frontier of first-person perception. Project page: https://ego4d-data.org/
Spatio-Temporal Perturbations for Video Attribution
Sep 01, 2021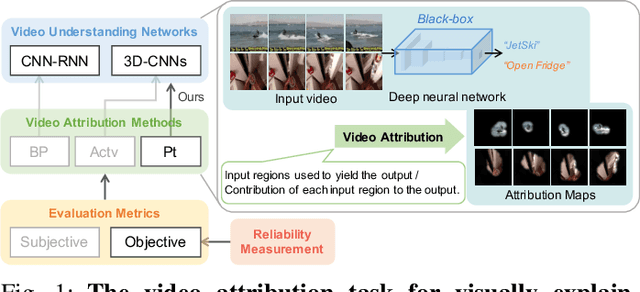

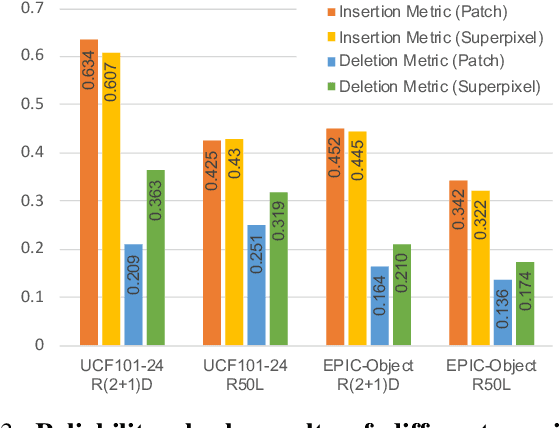
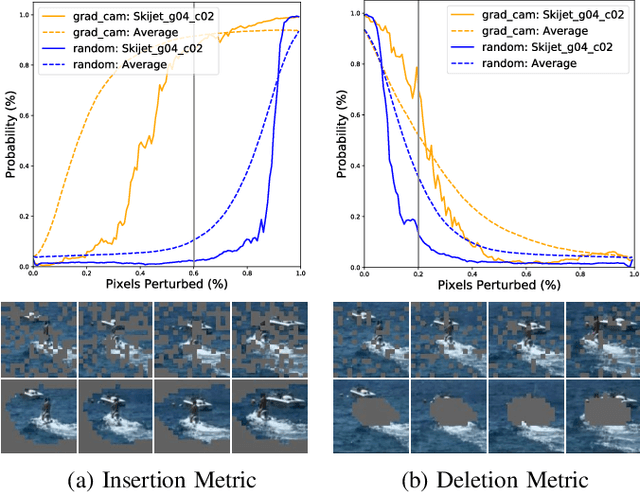
The attribution method provides a direction for interpreting opaque neural networks in a visual way by identifying and visualizing the input regions/pixels that dominate the output of a network. Regarding the attribution method for visually explaining video understanding networks, it is challenging because of the unique spatiotemporal dependencies existing in video inputs and the special 3D convolutional or recurrent structures of video understanding networks. However, most existing attribution methods focus on explaining networks taking a single image as input and a few works specifically devised for video attribution come short of dealing with diversified structures of video understanding networks. In this paper, we investigate a generic perturbation-based attribution method that is compatible with diversified video understanding networks. Besides, we propose a novel regularization term to enhance the method by constraining the smoothness of its attribution results in both spatial and temporal dimensions. In order to assess the effectiveness of different video attribution methods without relying on manual judgement, we introduce reliable objective metrics which are checked by a newly proposed reliability measurement. We verified the effectiveness of our method by both subjective and objective evaluation and comparison with multiple significant attribution methods.
A Comprehensive Study on Visual Explanations for Spatio-temporal Networks
May 01, 2020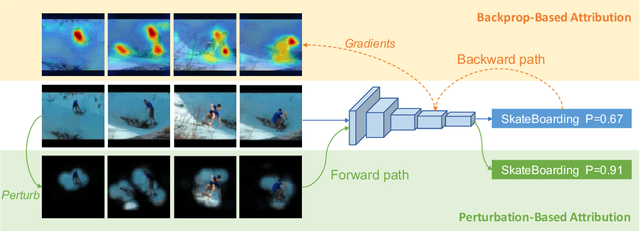

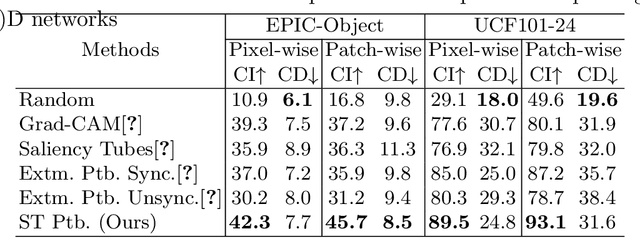
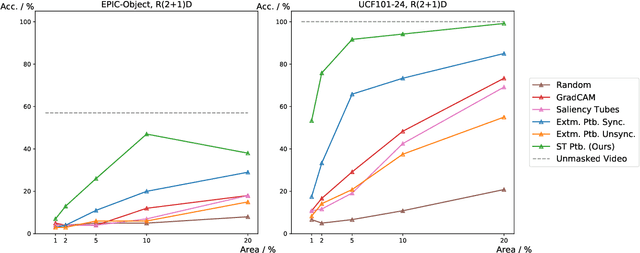
Identifying and visualizing regions that are significant for a given deep neural network model, i.e., attribution methods, is still a vital but challenging task, especially for spatio-temporal networks that process videos as input. Albeit some methods that have been proposed for video attribution, it is yet to be studied what types of network structures each video attribution method is suitable for. In this paper, we provide a comprehensive study of the existing video attribution methods of two categories, gradient-based and perturbation-based, for visual explanation of neural networks that take videos as the input (spatio-temporal networks). To perform this study, we extended a perturbation-based attribution method from 2D (images) to 3D (videos) and validated its effectiveness by mathematical analysis and experiments. For a more comprehensive analysis of existing video attribution methods, we introduce objective metrics that are complementary to existing subjective ones. Our experimental results indicate that attribution methods tend to show opposite performances on objective and subjective metrics.
Manipulation-skill Assessment from Videos with Spatial Attention Network
Jan 09, 2019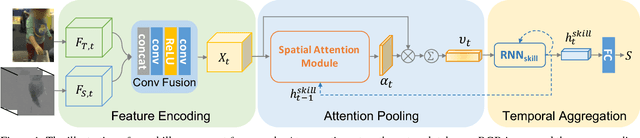
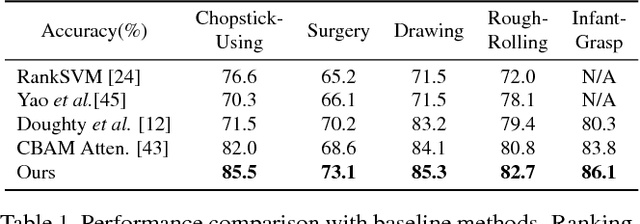
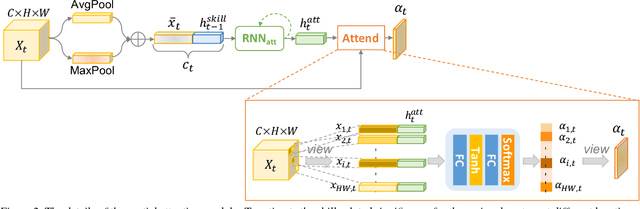
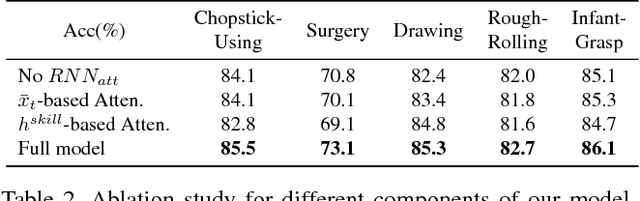
Recent advances in computer vision have made it possible to automatically assess from videos the manipulation skills of humans in performing a task, which has many important applications in domains such as health rehabilitation and manufacturing. However, previous methods used all video appearance as input and did not consider the attention mechanism humans use in assessing videos, which may limit their performance since only a part of video regions is critical for skill assessment. Our motivation here is to model human attention in videos that helps to focus on most relevant video regions for better skill assessment. In particular, we propose a novel deep model that learns spatial attention automatically from videos in an end-to-end manner. We evaluate our approach on a newly collected dataset of infant grasping task and four existing datasets of hand manipulation tasks. Experiment results demonstrate that state-of-the-art performance can be achieved by considering attention in automatic skill assessment.
Mutual Context Network for Jointly Estimating Egocentric Gaze and Actions
Jan 07, 2019
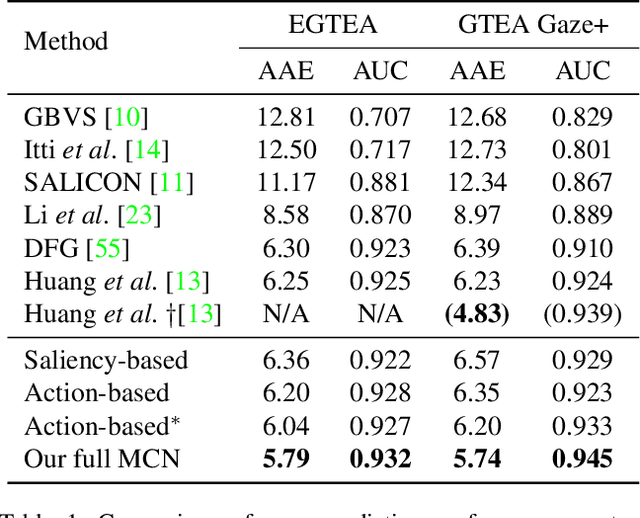
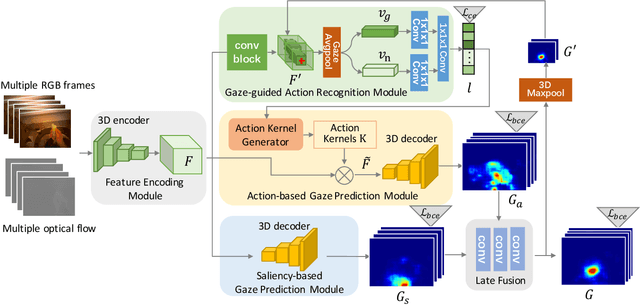
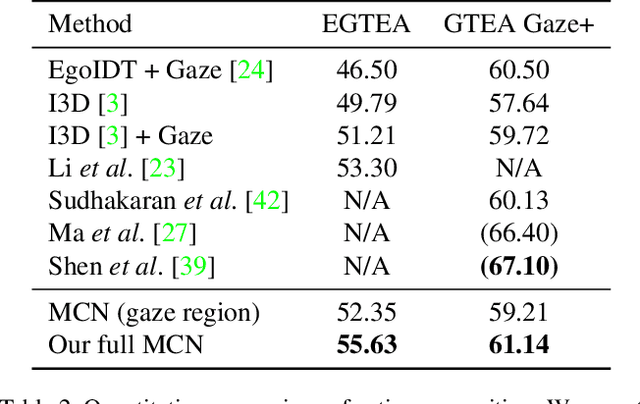
In this work, we address two coupled tasks of gaze prediction and action recognition in egocentric videos by exploring their mutual context. Our assumption is that in the procedure of performing a manipulation task, what a person is doing determines where the person is looking at, and the gaze point reveals gaze and non-gaze regions which contain important and complementary information about the undergoing action. We propose a novel mutual context network (MCN) that jointly learns action-dependent gaze prediction and gaze-guided action recognition in an end-to-end manner. Experiments on public egocentric video datasets demonstrate that our MCN achieves state-of-the-art performance of both gaze prediction and action recognition.
Predicting Gaze in Egocentric Video by Learning Task-dependent Attention Transition
Jul 20, 2018
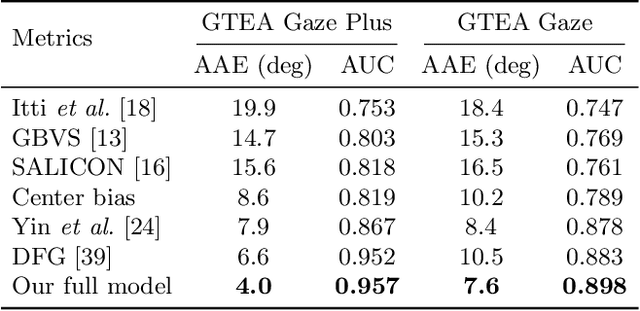
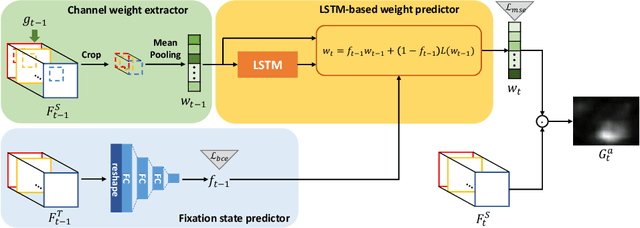
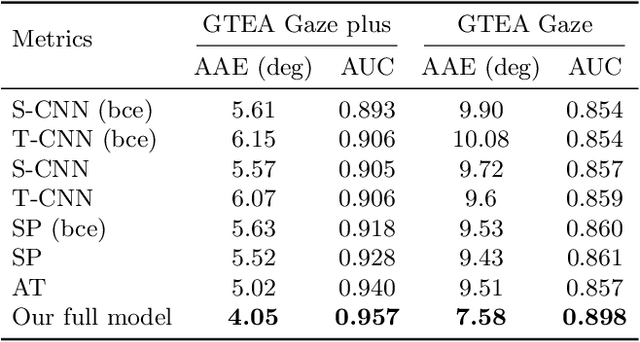
We present a new computational model for gaze prediction in egocentric videos by exploring patterns in temporal shift of gaze fixations (attention transition) that are dependent on egocentric manipulation tasks. Our assumption is that the high-level context of how a task is completed in a certain way has a strong influence on attention transition and should be modeled for gaze prediction in natural dynamic scenes. Specifically, we propose a hybrid model based on deep neural networks which integrates task-dependent attention transition with bottom-up saliency prediction. In particular, the task-dependent attention transition is learned with a recurrent neural network to exploit the temporal context of gaze fixations, e.g. looking at a cup after moving gaze away from a grasped bottle. Experiments on public egocentric activity datasets show that our model significantly outperforms state-of-the-art gaze prediction methods and is able to learn meaningful transition of human attention.