 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManipulation-skill Assessment from Videos with Spatial Attention Network
Paper and Code
Jan 09, 2019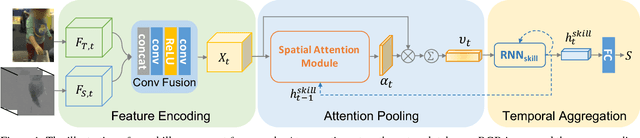
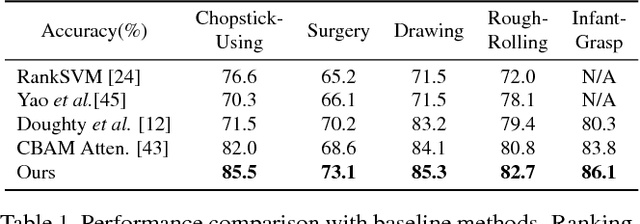
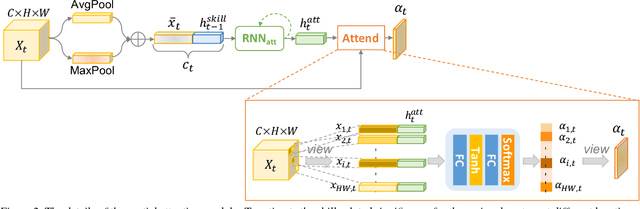
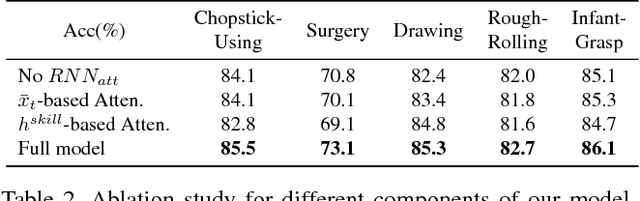
Recent advances in computer vision have made it possible to automatically assess from videos the manipulation skills of humans in performing a task, which has many important applications in domains such as health rehabilitation and manufacturing. However, previous methods used all video appearance as input and did not consider the attention mechanism humans use in assessing videos, which may limit their performance since only a part of video regions is critical for skill assessment. Our motivation here is to model human attention in videos that helps to focus on most relevant video regions for better skill assessment. In particular, we propose a novel deep model that learns spatial attention automatically from videos in an end-to-end manner. We evaluate our approach on a newly collected dataset of infant grasping task and four existing datasets of hand manipulation tasks. Experiment results demonstrate that state-of-the-art performance can be achieved by considering attention in automatic skill assessment.