 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSat2Scene: 3D Urban Scene Generation from Satellite Images with Diffusion
Jan 19, 2024
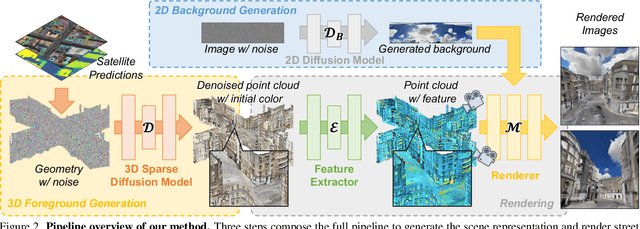
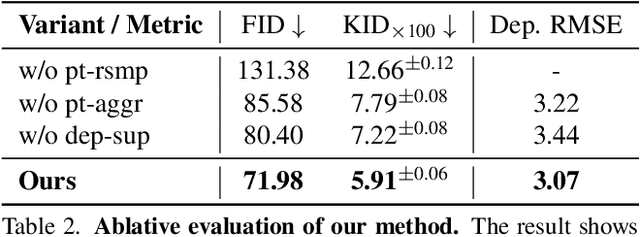

Directly generating scenes from satellite imagery offers exciting possibilities for integration into applications like games and map services. However, challenges arise from significant view changes and scene scale. Previous efforts mainly focused on image or video generation, lacking exploration into the adaptability of scene generation for arbitrary views. Existing 3D generation works either operate at the object level or are difficult to utilize the geometry obtained from satellite imagery. To overcome these limitations, we propose a novel architecture for direct 3D scene generation by introducing diffusion models into 3D sparse representations and combining them with neural rendering techniques. Specifically, our approach generates texture colors at the point level for a given geometry using a 3D diffusion model first, which is then transformed into a scene representation in a feed-forward manner. The representation can be utilized to render arbitrary views which would excel in both single-frame quality and inter-frame consistency. Experiments in two city-scale datasets show that our model demonstrates proficiency in generating photo-realistic street-view image sequences and cross-view urban scenes from satellite imagery.
CompNVS: Novel View Synthesis with Scene Completion
Jul 23, 2022

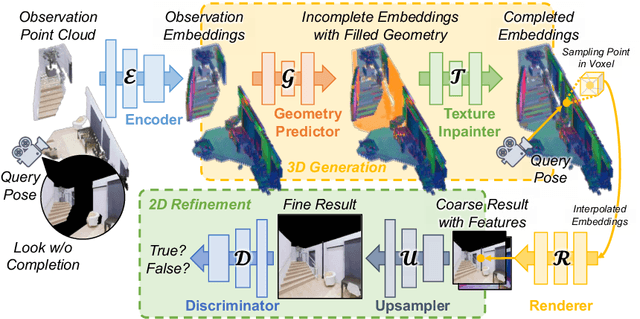

We introduce a scalable framework for novel view synthesis from RGB-D images with largely incomplete scene coverage. While generative neural approaches have demonstrated spectacular results on 2D images, they have not yet achieved similar photorealistic results in combination with scene completion where a spatial 3D scene understanding is essential. To this end, we propose a generative pipeline performing on a sparse grid-based neural scene representation to complete unobserved scene parts via a learned distribution of scenes in a 2.5D-3D-2.5D manner. We process encoded image features in 3D space with a geometry completion network and a subsequent texture inpainting network to extrapolate the missing area. Photorealistic image sequences can be finally obtained via consistency-relevant differentiable rendering. Comprehensive experiments show that the graphical outputs of our method outperform the state of the art, especially within unobserved scene parts.
Factorized and Controllable Neural Re-Rendering of Outdoor Scene for Photo Extrapolation
Jul 14, 2022



Expanding an existing tourist photo from a partially captured scene to a full scene is one of the desired experiences for photography applications. Although photo extrapolation has been well studied, it is much more challenging to extrapolate a photo (i.e., selfie) from a narrow field of view to a wider one while maintaining a similar visual style. In this paper, we propose a factorized neural re-rendering model to produce photorealistic novel views from cluttered outdoor Internet photo collections, which enables the applications including controllable scene re-rendering, photo extrapolation and even extrapolated 3D photo generation. Specifically, we first develop a novel factorized re-rendering pipeline to handle the ambiguity in the decomposition of geometry, appearance and illumination. We also propose a composited training strategy to tackle the unexpected occlusion in Internet images. Moreover, to enhance photo-realism when extrapolating tourist photographs, we propose a novel realism augmentation process to complement appearance details, which automatically propagates the texture details from a narrow captured photo to the extrapolated neural rendered image. The experiments and photo editing examples on outdoor scenes demonstrate the superior performance of our proposed method in both photo-realism and downstream applications.
NVS-MonoDepth: Improving Monocular Depth Prediction with Novel View Synthesis
Dec 22, 2021
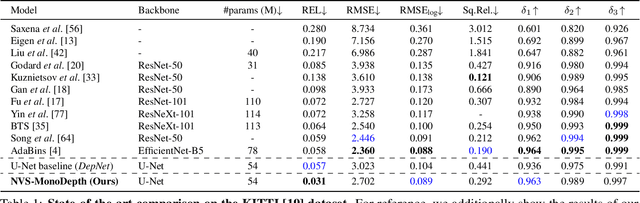
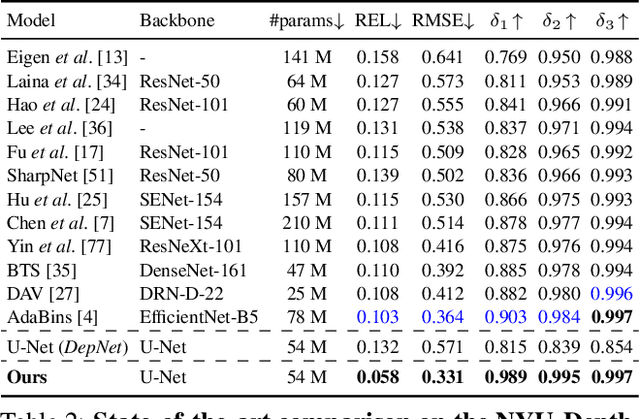
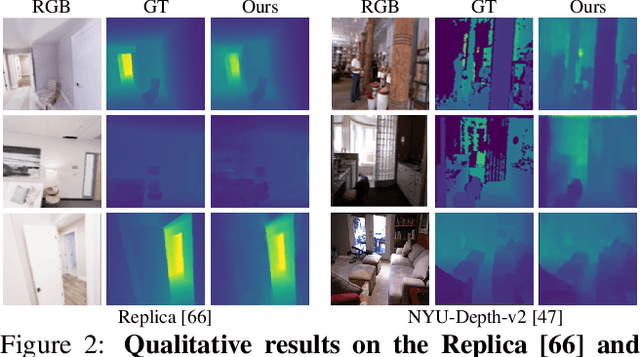
Building upon the recent progress in novel view synthesis, we propose its application to improve monocular depth estimation. In particular, we propose a novel training method split in three main steps. First, the prediction results of a monocular depth network are warped to an additional view point. Second, we apply an additional image synthesis network, which corrects and improves the quality of the warped RGB image. The output of this network is required to look as similar as possible to the ground-truth view by minimizing the pixel-wise RGB reconstruction error. Third, we reapply the same monocular depth estimation onto the synthesized second view point and ensure that the depth predictions are consistent with the associated ground truth depth. Experimental results prove that our method achieves state-of-the-art or comparable performance on the KITTI and NYU-Depth-v2 datasets with a lightweight and simple vanilla U-Net architecture.
* 8 pages (main paper), 9 pages (supplementary material), 14 figures, 4 tables
Spatio-Temporal Perturbations for Video Attribution
Sep 01, 2021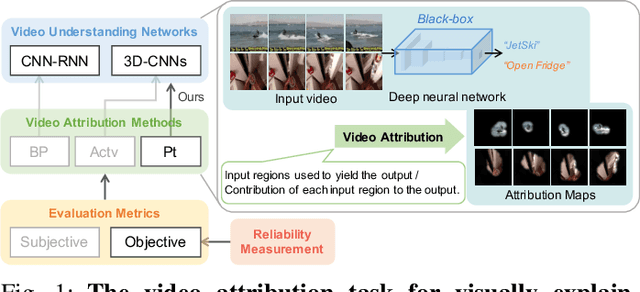

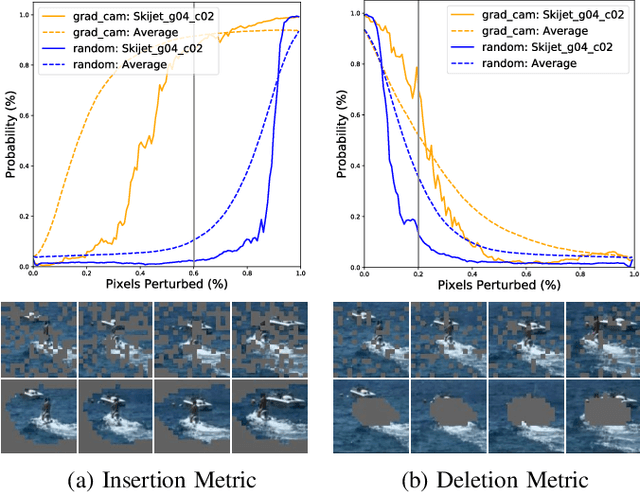
The attribution method provides a direction for interpreting opaque neural networks in a visual way by identifying and visualizing the input regions/pixels that dominate the output of a network. Regarding the attribution method for visually explaining video understanding networks, it is challenging because of the unique spatiotemporal dependencies existing in video inputs and the special 3D convolutional or recurrent structures of video understanding networks. However, most existing attribution methods focus on explaining networks taking a single image as input and a few works specifically devised for video attribution come short of dealing with diversified structures of video understanding networks. In this paper, we investigate a generic perturbation-based attribution method that is compatible with diversified video understanding networks. Besides, we propose a novel regularization term to enhance the method by constraining the smoothness of its attribution results in both spatial and temporal dimensions. In order to assess the effectiveness of different video attribution methods without relying on manual judgement, we introduce reliable objective metrics which are checked by a newly proposed reliability measurement. We verified the effectiveness of our method by both subjective and objective evaluation and comparison with multiple significant attribution methods.
Street-view Panoramic Video Synthesis from a Single Satellite Image
Dec 17, 2020
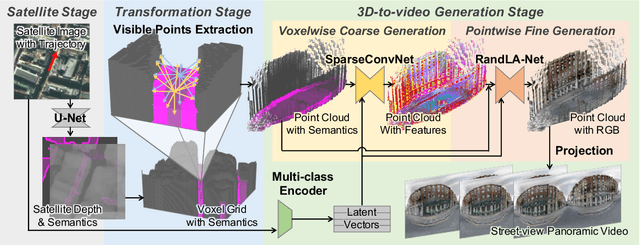


We present a novel method for synthesizing both temporally and geometrically consistent street-view panoramic video from a given single satellite image and camera trajectory. Existing cross-view synthesis approaches focus more on images, while video synthesis in such a case has not yet received enough attention. Single image synthesis approaches are not well suited for video synthesis since they lack temporal consistency which is a crucial property of videos. To this end, our approach explicitly creates a 3D point cloud representation of the scene and maintains dense 3D-2D correspondences across frames that reflect the geometric scene configuration inferred from the satellite view. We implement a cascaded network architecture with two hourglass modules for successive coarse and fine generation for colorizing the point cloud from the semantics and per-class latent vectors. By leveraging computed correspondences, the produced street-view video frames adhere to the 3D geometric scene structure and maintain temporal consistency. Qualitative and quantitative experiments demonstrate superior results compared to other state-of-the-art cross-view synthesis approaches that either lack temporal or geometric consistency. To the best of our knowledge, our work is the first work to synthesize cross-view images to video.
A Comprehensive Study on Visual Explanations for Spatio-temporal Networks
May 01, 2020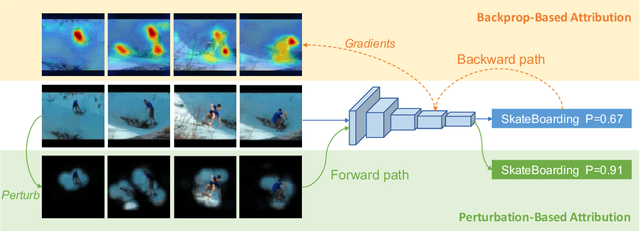

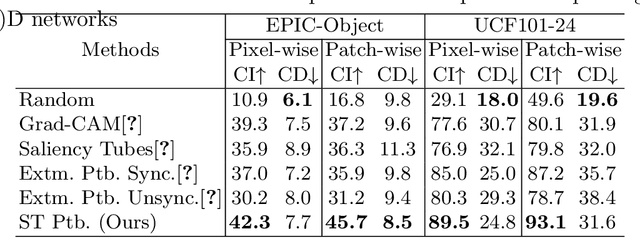
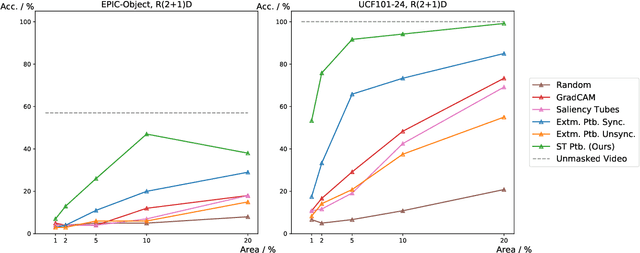
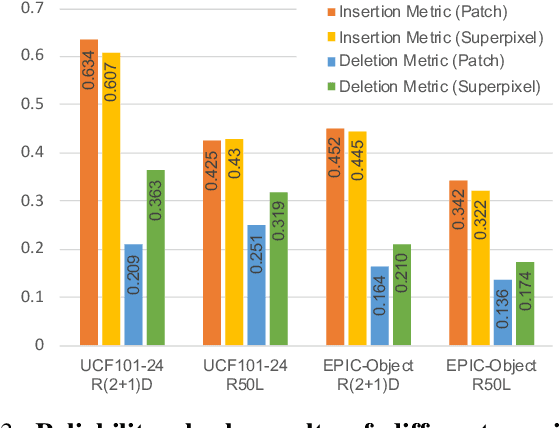
Identifying and visualizing regions that are significant for a given deep neural network model, i.e., attribution methods, is still a vital but challenging task, especially for spatio-temporal networks that process videos as input. Albeit some methods that have been proposed for video attribution, it is yet to be studied what types of network structures each video attribution method is suitable for. In this paper, we provide a comprehensive study of the existing video attribution methods of two categories, gradient-based and perturbation-based, for visual explanation of neural networks that take videos as the input (spatio-temporal networks). To perform this study, we extended a perturbation-based attribution method from 2D (images) to 3D (videos) and validated its effectiveness by mathematical analysis and experiments. For a more comprehensive analysis of existing video attribution methods, we introduce objective metrics that are complementary to existing subjective ones. Our experimental results indicate that attribution methods tend to show opposite performances on objective and subjective metrics.
PolyMapper: Extracting City Maps using Polygons
Dec 04, 2018

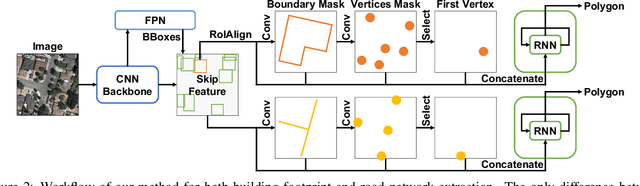

We propose a method to leapfrog pixel-wise, semantic segmentation of (aerial) images and predict objects in a vector representation directly. PolyMapper predicts maps of cities from aerial images as collections of polygons with a learnable framework. Instead of the usual multi-step procedure of semantic segmentation, shape improvement, conversion to polygons, and polygon refinement, our approach learns mappings with a single network architecture and directly outputs maps. We demonstrate that our method is capable of drawing polygons of buildings and road networks that very closely approximate the structure of existing online maps such as OpenStreetMap, and it does so in a fully automated manner. Validation on existing and novel large scale datasets of several cities show that our approach achieves good levels of performance.