 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreet-view Panoramic Video Synthesis from a Single Satellite Image
Paper and Code

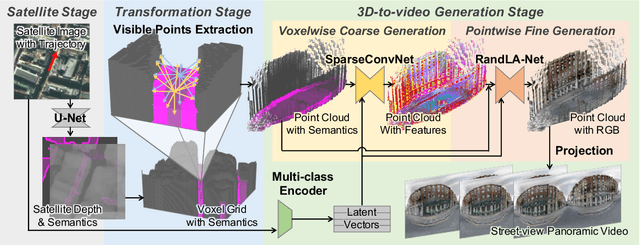


We present a novel method for synthesizing both temporally and geometrically consistent street-view panoramic video from a given single satellite image and camera trajectory. Existing cross-view synthesis approaches focus more on images, while video synthesis in such a case has not yet received enough attention. Single image synthesis approaches are not well suited for video synthesis since they lack temporal consistency which is a crucial property of videos. To this end, our approach explicitly creates a 3D point cloud representation of the scene and maintains dense 3D-2D correspondences across frames that reflect the geometric scene configuration inferred from the satellite view. We implement a cascaded network architecture with two hourglass modules for successive coarse and fine generation for colorizing the point cloud from the semantics and per-class latent vectors. By leveraging computed correspondences, the produced street-view video frames adhere to the 3D geometric scene structure and maintain temporal consistency. Qualitative and quantitative experiments demonstrate superior results compared to other state-of-the-art cross-view synthesis approaches that either lack temporal or geometric consistency. To the best of our knowledge, our work is the first work to synthesize cross-view images to video.