 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Study on Visual Explanations for Spatio-temporal Networks
Paper and Code
May 01, 2020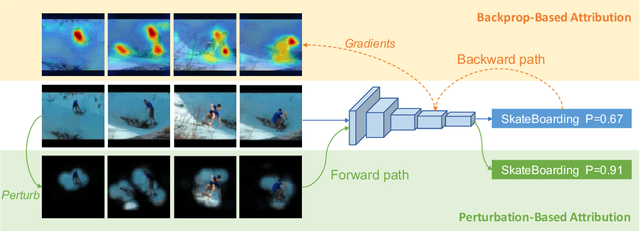

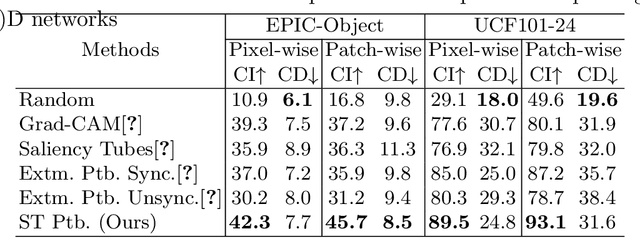
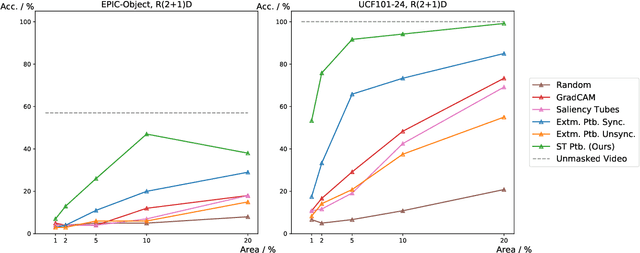
Identifying and visualizing regions that are significant for a given deep neural network model, i.e., attribution methods, is still a vital but challenging task, especially for spatio-temporal networks that process videos as input. Albeit some methods that have been proposed for video attribution, it is yet to be studied what types of network structures each video attribution method is suitable for. In this paper, we provide a comprehensive study of the existing video attribution methods of two categories, gradient-based and perturbation-based, for visual explanation of neural networks that take videos as the input (spatio-temporal networks). To perform this study, we extended a perturbation-based attribution method from 2D (images) to 3D (videos) and validated its effectiveness by mathematical analysis and experiments. For a more comprehensive analysis of existing video attribution methods, we introduce objective metrics that are complementary to existing subjective ones. Our experimental results indicate that attribution methods tend to show opposite performances on objective and subjective metrics.