 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAMP: Lift Image-Editing as General 3D Priors for Open-world Manipulation
Apr 09, 2026Human-like generalization in open-world remains a fundamental challenge for robotic manipulation. Existing learning-based methods, including reinforcement learning, imitation learning, and vision-language-action-models (VLAs), often struggle with novel tasks and unseen environments. Another promising direction is to explore generalizable representations that capture fine-grained spatial and geometric relations for open-world manipulation. While large-language-model (LLMs) and vision-language-model (VLMs) provide strong semantic reasoning based on language or annotated 2D representations, their limited 3D awareness restricts their applicability to fine-grained manipulation. To address this, we propose LAMP, which lifts image-editing as 3D priors to extract inter-object 3D transformations as continuous, geometry-aware representations. Our key insight is that image-editing inherently encodes rich 2D spatial cues, and lifting these implicit cues into 3D transformations provides fine-grained and accurate guidance for open-world manipulation. Extensive experiments demonstrate that \codename delivers precise 3D transformations and achieves strong zero-shot generalization in open-world manipulation. Project page: https://zju3dv.github.io/LAMP/.
HyperOffload: Graph-Driven Hierarchical Memory Management for Large Language Models on SuperNode Architectures
Feb 03, 2026The rapid evolution of Large Language Models (LLMs) towards long-context reasoning and sparse architectures has pushed memory requirements far beyond the capacity of individual device HBM. While emerging supernode architectures offer terabyte-scale shared memory pools via high-bandwidth interconnects, existing software stacks fail to exploit this hardware effectively. Current runtime-based offloading and swapping techniques operate with a local view, leading to reactive scheduling and exposed communication latency that stall the computation pipeline. In this paper, we propose the SuperNode Memory Management Framework (\textbf{HyperOffload}). It employs a compiler-assisted approach that leverages graph-driven memory management to treat remote memory access as explicit operations in the computation graph, specifically designed for hierarchical SuperNode architectures. Unlike reactive runtime systems, SuperNode represents data movement using cache operators within the compiler's Intermediate Representation (IR). This design enables a global, compile-time analysis of tensor lifetimes and execution dependencies. Leveraging this visibility, we develop a global execution-order refinement algorithm that statically schedules data transfers to hide remote memory latency behind compute-intensive regions. We implement SuperNode within the production deep learning framework MindSpore, adding a remote memory backend and specialized compiler passes. Evaluation on representative LLM workloads shows that SuperNode reduces peak device memory usage by up to 26\% for inference while maintaining end-to-end performance. Our work demonstrates that integrating memory-augmented hardware into the compiler's optimization framework is essential for scaling next-generation AI workloads.
LightCity: An Urban Dataset for Outdoor Inverse Rendering and Reconstruction under Multi-illumination Conditions
Feb 01, 2026Inverse rendering in urban scenes is pivotal for applications like autonomous driving and digital twins. Yet, it faces significant challenges due to complex illumination conditions, including multi-illumination and indirect light and shadow effects. However, the effects of these challenges on intrinsic decomposition and 3D reconstruction have not been explored due to the lack of appropriate datasets. In this paper, we present LightCity, a novel high-quality synthetic urban dataset featuring diverse illumination conditions with realistic indirect light and shadow effects. LightCity encompasses over 300 sky maps with highly controllable illumination, varying scales with street-level and aerial perspectives over 50K images, and rich properties such as depth, normal, material components, light and indirect light, etc. Besides, we leverage LightCity to benchmark three fundamental tasks in the urban environments and conduct a comprehensive analysis of these benchmarks, laying a robust foundation for advancing related research.
Free360: Layered Gaussian Splatting for Unbounded 360-Degree View Synthesis from Extremely Sparse and Unposed Views
Mar 31, 2025

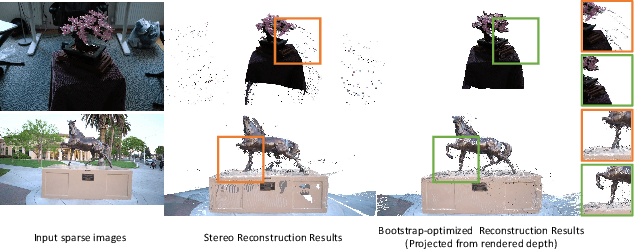

Neural rendering has demonstrated remarkable success in high-quality 3D neural reconstruction and novel view synthesis with dense input views and accurate poses. However, applying it to extremely sparse, unposed views in unbounded 360{\deg} scenes remains a challenging problem. In this paper, we propose a novel neural rendering framework to accomplish the unposed and extremely sparse-view 3D reconstruction in unbounded 360{\deg} scenes. To resolve the spatial ambiguity inherent in unbounded scenes with sparse input views, we propose a layered Gaussian-based representation to effectively model the scene with distinct spatial layers. By employing a dense stereo reconstruction model to recover coarse geometry, we introduce a layer-specific bootstrap optimization to refine the noise and fill occluded regions in the reconstruction. Furthermore, we propose an iterative fusion of reconstruction and generation alongside an uncertainty-aware training approach to facilitate mutual conditioning and enhancement between these two processes. Comprehensive experiments show that our approach outperforms existing state-of-the-art methods in terms of rendering quality and surface reconstruction accuracy. Project page: https://zju3dv.github.io/free360/
GeneAvatar: Generic Expression-Aware Volumetric Head Avatar Editing from a Single Image
Apr 02, 2024



Recently, we have witnessed the explosive growth of various volumetric representations in modeling animatable head avatars. However, due to the diversity of frameworks, there is no practical method to support high-level applications like 3D head avatar editing across different representations. In this paper, we propose a generic avatar editing approach that can be universally applied to various 3DMM driving volumetric head avatars. To achieve this goal, we design a novel expression-aware modification generative model, which enables lift 2D editing from a single image to a consistent 3D modification field. To ensure the effectiveness of the generative modification process, we develop several techniques, including an expression-dependent modification distillation scheme to draw knowledge from the large-scale head avatar model and 2D facial texture editing tools, implicit latent space guidance to enhance model convergence, and a segmentation-based loss reweight strategy for fine-grained texture inversion. Extensive experiments demonstrate that our method delivers high-quality and consistent results across multiple expression and viewpoints. Project page: https://zju3dv.github.io/geneavatar/
Mirror-NeRF: Learning Neural Radiance Fields for Mirrors with Whitted-Style Ray Tracing
Aug 07, 2023Recently, Neural Radiance Fields (NeRF) has exhibited significant success in novel view synthesis, surface reconstruction, etc. However, since no physical reflection is considered in its rendering pipeline, NeRF mistakes the reflection in the mirror as a separate virtual scene, leading to the inaccurate reconstruction of the mirror and multi-view inconsistent reflections in the mirror. In this paper, we present a novel neural rendering framework, named Mirror-NeRF, which is able to learn accurate geometry and reflection of the mirror and support various scene manipulation applications with mirrors, such as adding new objects or mirrors into the scene and synthesizing the reflections of these new objects in mirrors, controlling mirror roughness, etc. To achieve this goal, we propose a unified radiance field by introducing the reflection probability and tracing rays following the light transport model of Whitted Ray Tracing, and also develop several techniques to facilitate the learning process. Experiments and comparisons on both synthetic and real datasets demonstrate the superiority of our method. The code and supplementary material are available on the project webpage: https://zju3dv.github.io/Mirror-NeRF/.
SINE: Semantic-driven Image-based NeRF Editing with Prior-guided Editing Field
Mar 25, 2023



Despite the great success in 2D editing using user-friendly tools, such as Photoshop, semantic strokes, or even text prompts, similar capabilities in 3D areas are still limited, either relying on 3D modeling skills or allowing editing within only a few categories. In this paper, we present a novel semantic-driven NeRF editing approach, which enables users to edit a neural radiance field with a single image, and faithfully delivers edited novel views with high fidelity and multi-view consistency. To achieve this goal, we propose a prior-guided editing field to encode fine-grained geometric and texture editing in 3D space, and develop a series of techniques to aid the editing process, including cyclic constraints with a proxy mesh to facilitate geometric supervision, a color compositing mechanism to stabilize semantic-driven texture editing, and a feature-cluster-based regularization to preserve the irrelevant content unchanged. Extensive experiments and editing examples on both real-world and synthetic data demonstrate that our method achieves photo-realistic 3D editing using only a single edited image, pushing the bound of semantic-driven editing in 3D real-world scenes. Our project webpage: https://zju3dv.github.io/sine/.
EC-SfM: Efficient Covisibility-based Structure-from-Motion for Both Sequential and Unordered Images
Feb 21, 2023
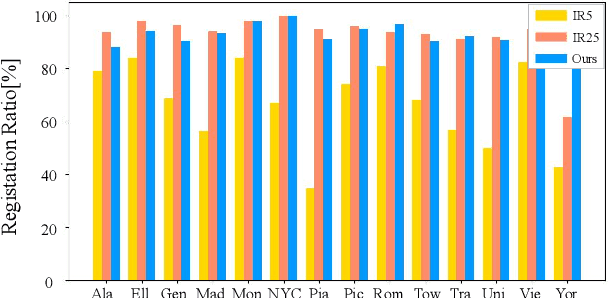
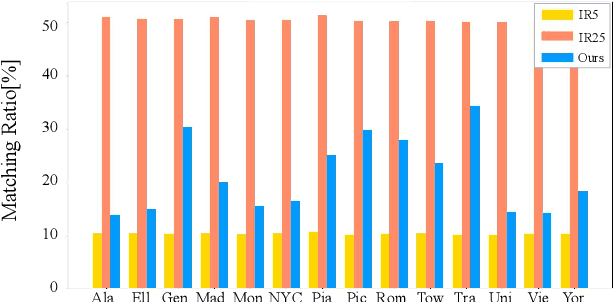

Structure-from-Motion is a technology used to obtain scene structure through image collection, which is a fundamental problem in computer vision. For unordered Internet images, SfM is very slow due to the lack of prior knowledge about image overlap. For sequential images, knowing the large overlap between adjacent frames, SfM can adopt a variety of acceleration strategies, which are only applicable to sequential data. To further improve the reconstruction efficiency and break the gap of strategies between these two kinds of data, this paper presents an efficient covisibility-based incremental SfM. Different from previous methods, we exploit covisibility and registration dependency to describe the image connection which is suitable to any kind of data. Based on this general image connection, we propose a unified framework to efficiently reconstruct sequential images, unordered images, and the mixture of these two. Experiments on the unordered images and mixed data verify the effectiveness of the proposed method, which is three times faster than the state of the art on feature matching, and an order of magnitude faster on reconstruction without sacrificing the accuracy. The source code is publicly available at https://github.com/openxrlab/xrsfm
IntrinsicNeRF: Learning Intrinsic Neural Radiance Fields for Editable Novel View Synthesis
Oct 02, 2022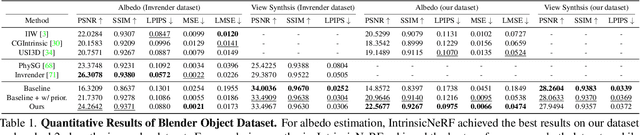
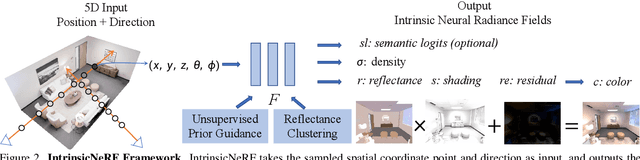
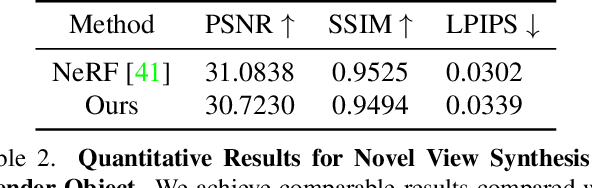
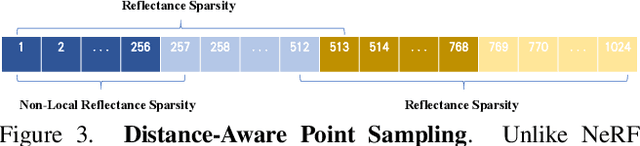
We present intrinsic neural radiance fields, dubbed IntrinsicNeRF, that introduce intrinsic decomposition into the NeRF-based~\cite{mildenhall2020nerf} neural rendering method and can perform editable novel view synthesis in room-scale scenes while existing inverse rendering combined with neural rendering methods~\cite{zhang2021physg, zhang2022modeling} can only work on object-specific scenes. Given that intrinsic decomposition is a fundamentally ambiguous and under-constrained inverse problem, we propose a novel distance-aware point sampling and adaptive reflectance iterative clustering optimization method that enables IntrinsicNeRF with traditional intrinsic decomposition constraints to be trained in an unsupervised manner, resulting in temporally consistent intrinsic decomposition results. To cope with the problem of different adjacent instances of similar reflectance in a scene being incorrectly clustered together, we further propose a hierarchical clustering method with coarse-to-fine optimization to obtain a fast hierarchical indexing representation. It enables compelling real-time augmented reality applications such as scene recoloring, material editing, and illumination variation. Extensive experiments on Blender Object and Replica Scene demonstrate that we can obtain high-quality, consistent intrinsic decomposition results and high-fidelity novel view synthesis even for challenging sequences. Code and data are available on the project webpage: https://zju3dv.github.io/intrinsic_nerf/.
NeuMesh: Learning Disentangled Neural Mesh-based Implicit Field for Geometry and Texture Editing
Jul 25, 2022
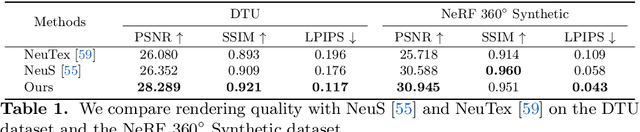
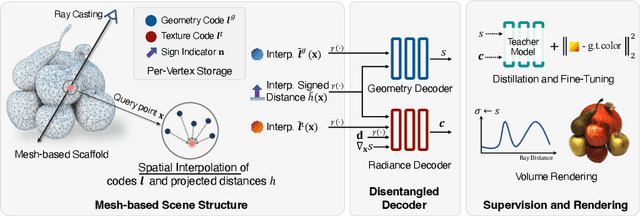
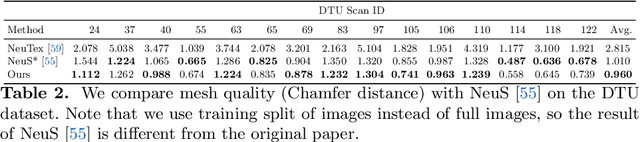
Very recently neural implicit rendering techniques have been rapidly evolved and shown great advantages in novel view synthesis and 3D scene reconstruction. However, existing neural rendering methods for editing purposes offer limited functionality, e.g., rigid transformation, or not applicable for fine-grained editing for general objects from daily lives. In this paper, we present a novel mesh-based representation by encoding the neural implicit field with disentangled geometry and texture codes on mesh vertices, which facilitates a set of editing functionalities, including mesh-guided geometry editing, designated texture editing with texture swapping, filling and painting operations. To this end, we develop several techniques including learnable sign indicators to magnify spatial distinguishability of mesh-based representation, distillation and fine-tuning mechanism to make a steady convergence, and the spatial-aware optimization strategy to realize precise texture editing. Extensive experiments and editing examples on both real and synthetic data demonstrate the superiority of our method on representation quality and editing ability. Code is available on the project webpage: https://zju3dv.github.io/neumesh/.