 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuralMeshing: Differentiable Meshing of Implicit Neural Representations
Oct 05, 2022The generation of triangle meshes from point clouds, i.e. meshing, is a core task in computer graphics and computer vision. Traditional techniques directly construct a surface mesh using local decision heuristics, while some recent methods based on neural implicit representations try to leverage data-driven approaches for this meshing process. However, it is challenging to define a learnable representation for triangle meshes of unknown topology and size and for this reason, neural implicit representations rely on non-differentiable post-processing in order to extract the final triangle mesh. In this work, we propose a novel differentiable meshing algorithm for extracting surface meshes from neural implicit representations. Our method produces the mesh in an iterative fashion, which makes it applicable to shapes of various scales and adaptive to the local curvature of the shape. Furthermore, our method produces meshes with regular tessellation patterns and fewer triangle faces compared to existing methods. Experiments demonstrate the comparable reconstruction performance and favorable mesh properties over baselines.
LatentHuman: Shape-and-Pose Disentangled Latent Representation for Human Bodies
Nov 30, 2021
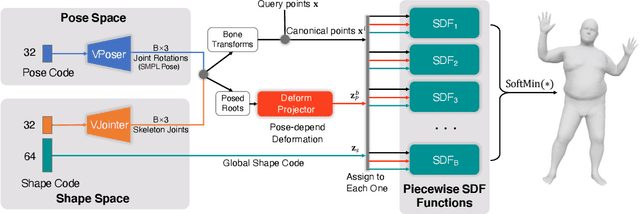
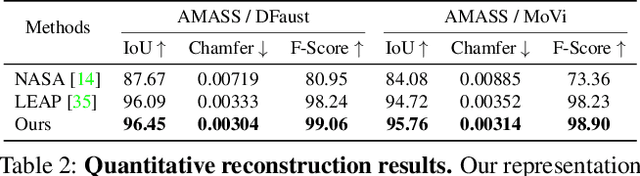

3D representation and reconstruction of human bodies have been studied for a long time in computer vision. Traditional methods rely mostly on parametric statistical linear models, limiting the space of possible bodies to linear combinations. It is only recently that some approaches try to leverage neural implicit representations for human body modeling, and while demonstrating impressive results, they are either limited by representation capability or not physically meaningful and controllable. In this work, we propose a novel neural implicit representation for the human body, which is fully differentiable and optimizable with disentangled shape and pose latent spaces. Contrary to prior work, our representation is designed based on the kinematic model, which makes the representation controllable for tasks like pose animation, while simultaneously allowing the optimization of shape and pose for tasks like 3D fitting and pose tracking. Our model can be trained and fine-tuned directly on non-watertight raw data with well-designed losses. Experiments demonstrate the improved 3D reconstruction performance over SoTA approaches and show the applicability of our method to shape interpolation, model fitting, pose tracking, and motion retargeting.
Self-Supervised Learning of Non-Rigid Residual Flow and Ego-Motion
Oct 19, 2020
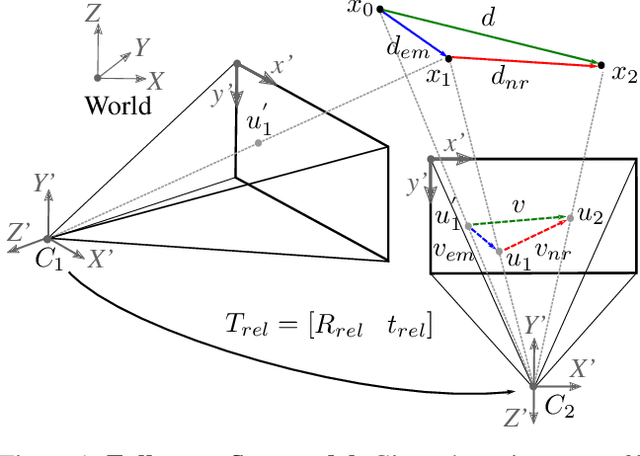
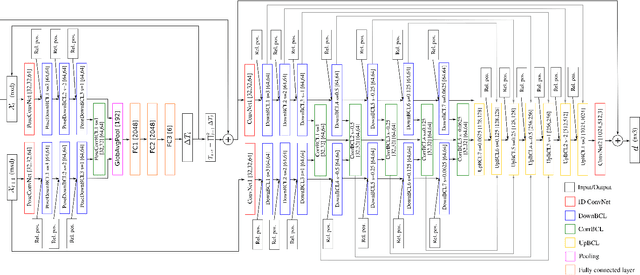
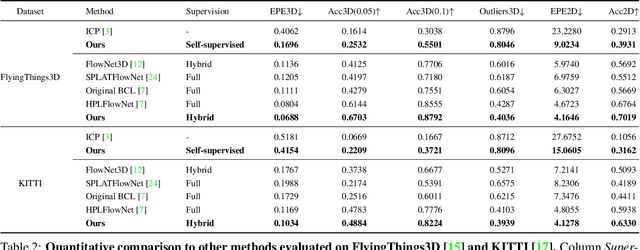
Most of the current scene flow methods choose to model scene flow as a per point translation vector without differentiating between static and dynamic components of 3D motion. In this work we present an alternative method for end-to-end scene flow learning by joint estimation of non-rigid residual flow and ego-motion flow for dynamic 3D scenes. We propose to learn the relative rigid transformation from a pair of point clouds followed by an iterative refinement. We then learn the non-rigid flow from transformed inputs with the deducted rigid part of the flow. Furthermore, we extend the supervised framework with self-supervisory signals based on the temporal consistency property of a point cloud sequence. Our solution allows both training in a supervised mode complemented by self-supervisory loss terms as well as training in a fully self-supervised mode. We demonstrate that decomposition of scene flow into non-rigid flow and ego-motion flow along with an introduction of the self-supervisory signals allowed us to outperform the current state-of-the-art supervised methods.