 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning of Non-Rigid Residual Flow and Ego-Motion
Oct 19, 2020
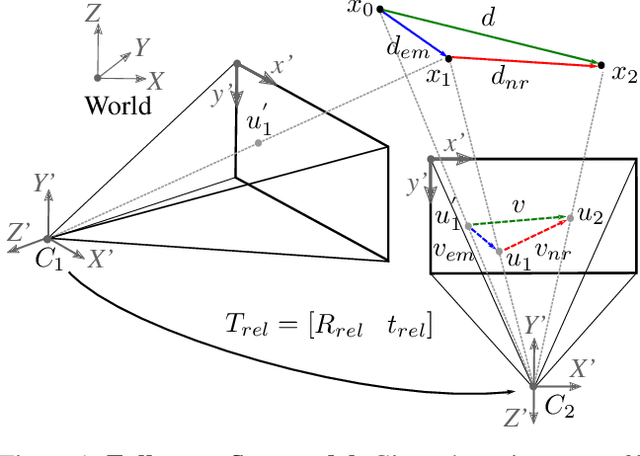
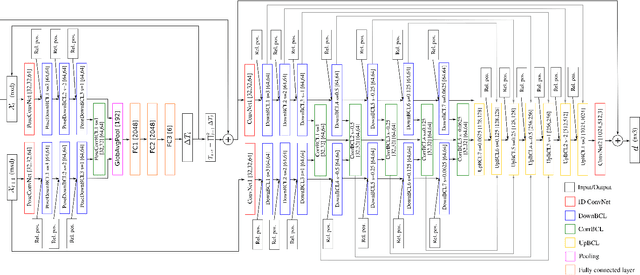
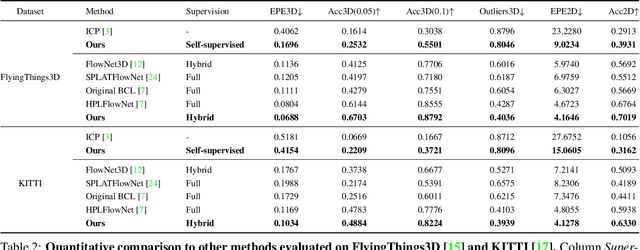
Most of the current scene flow methods choose to model scene flow as a per point translation vector without differentiating between static and dynamic components of 3D motion. In this work we present an alternative method for end-to-end scene flow learning by joint estimation of non-rigid residual flow and ego-motion flow for dynamic 3D scenes. We propose to learn the relative rigid transformation from a pair of point clouds followed by an iterative refinement. We then learn the non-rigid flow from transformed inputs with the deducted rigid part of the flow. Furthermore, we extend the supervised framework with self-supervisory signals based on the temporal consistency property of a point cloud sequence. Our solution allows both training in a supervised mode complemented by self-supervisory loss terms as well as training in a fully self-supervised mode. We demonstrate that decomposition of scene flow into non-rigid flow and ego-motion flow along with an introduction of the self-supervisory signals allowed us to outperform the current state-of-the-art supervised methods.