 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4DContrast: Contrastive Learning with Dynamic Correspondences for 3D Scene Understanding
Paper and Code
Dec 06, 2021


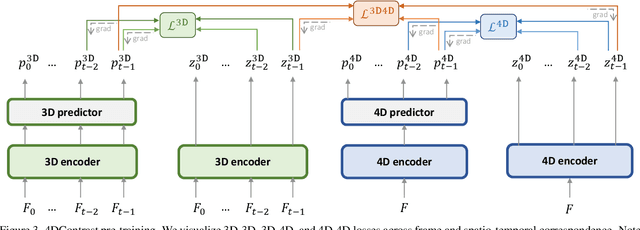
We present a new approach to instill 4D dynamic object priors into learned 3D representations by unsupervised pre-training. We observe that dynamic movement of an object through an environment provides important cues about its objectness, and thus propose to imbue learned 3D representations with such dynamic understanding, that can then be effectively transferred to improved performance in downstream 3D semantic scene understanding tasks. We propose a new data augmentation scheme leveraging synthetic 3D shapes moving in static 3D environments, and employ contrastive learning under 3D-4D constraints that encode 4D invariances into the learned 3D representations. Experiments demonstrate that our unsupervised representation learning results in improvement in downstream 3D semantic segmentation, object detection, and instance segmentation tasks, and moreover, notably improves performance in data-scarce scenarios.