 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRITS: A Spillage-Aware Guided Diffusion Policy for Robot Food Scooping Tasks
Oct 01, 2025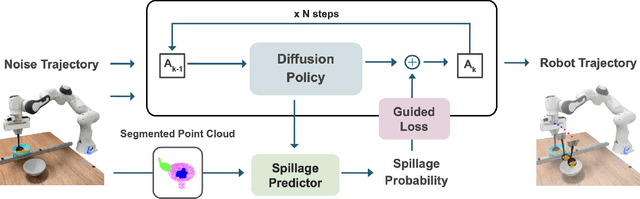
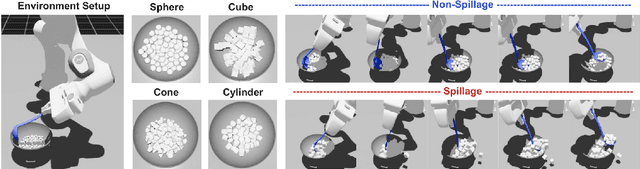


Robotic food scooping is a critical manipulation skill for food preparation and service robots. However, existing robot learning algorithms, especially learn-from-demonstration methods, still struggle to handle diverse and dynamic food states, which often results in spillage and reduced reliability. In this work, we introduce GRITS: A Spillage-Aware Guided Diffusion Policy for Robot Food Scooping Tasks. This framework leverages guided diffusion policy to minimize food spillage during scooping and to ensure reliable transfer of food items from the initial to the target location. Specifically, we design a spillage predictor that estimates the probability of spillage given current observation and action rollout. The predictor is trained on a simulated dataset with food spillage scenarios, constructed from four primitive shapes (spheres, cubes, cones, and cylinders) with varied physical properties such as mass, friction, and particle size. At inference time, the predictor serves as a differentiable guidance signal, steering the diffusion sampling process toward safer trajectories while preserving task success. We validate GRITS on a real-world robotic food scooping platform. GRITS is trained on six food categories and evaluated on ten unseen categories with different shapes and quantities. GRITS achieves an 82% task success rate and a 4% spillage rate, reducing spillage by over 40% compared to baselines without guidance, thereby demonstrating its effectiveness.
MatchU: Matching Unseen Objects for 6D Pose Estimation from RGB-D Images
Mar 03, 2024



Recent learning methods for object pose estimation require resource-intensive training for each individual object instance or category, hampering their scalability in real applications when confronted with previously unseen objects. In this paper, we propose MatchU, a Fuse-Describe-Match strategy for 6D pose estimation from RGB-D images. MatchU is a generic approach that fuses 2D texture and 3D geometric cues for 6D pose prediction of unseen objects. We rely on learning geometric 3D descriptors that are rotation-invariant by design. By encoding pose-agnostic geometry, the learned descriptors naturally generalize to unseen objects and capture symmetries. To tackle ambiguous associations using 3D geometry only, we fuse additional RGB information into our descriptor. This is achieved through a novel attention-based mechanism that fuses cross-modal information, together with a matching loss that leverages the latent space learned from RGB data to guide the descriptor learning process. Extensive experiments reveal the generalizability of both the RGB-D fusion strategy as well as the descriptor efficacy. Benefiting from the novel designs, MatchU surpasses all existing methods by a significant margin in terms of both accuracy and speed, even without the requirement of expensive re-training or rendering.
Tactile SLAM: Real-time inference of shape and pose from planar pushing
Nov 13, 2020

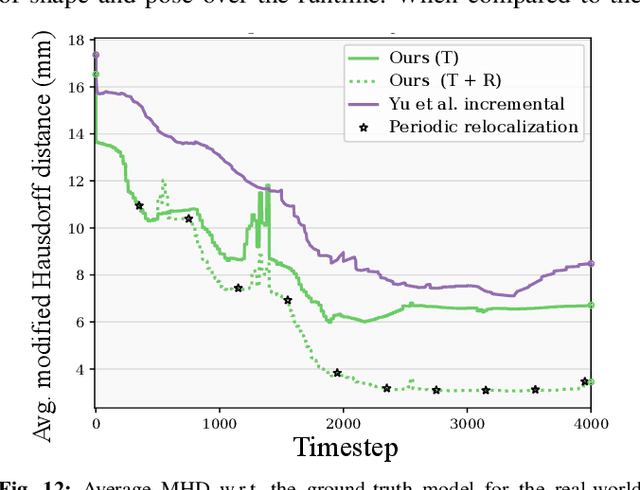
Tactile perception is central to robot manipulation in unstructured environments. However, it requires contact, and a mature implementation must infer object models while also accounting for the motion induced by the interaction. In this work, we present a method to estimate both object shape and pose in real-time from a stream of tactile measurements. This is applied towards tactile exploration of an unknown object by planar pushing. We consider this as an online SLAM problem with a nonparametric shape representation. Our formulation of tactile inference alternates between Gaussian process implicit surface regression and pose estimation on a factor graph. Through a combination of local Gaussian processes and fixed-lag smoothing, we infer object shape and pose in real-time. We evaluate our system across different objects in both simulated and real-world planar pushing tasks.
Realtime State Estimation with Tactile and Visual sensing. Application to Planar Manipulation
May 15, 2018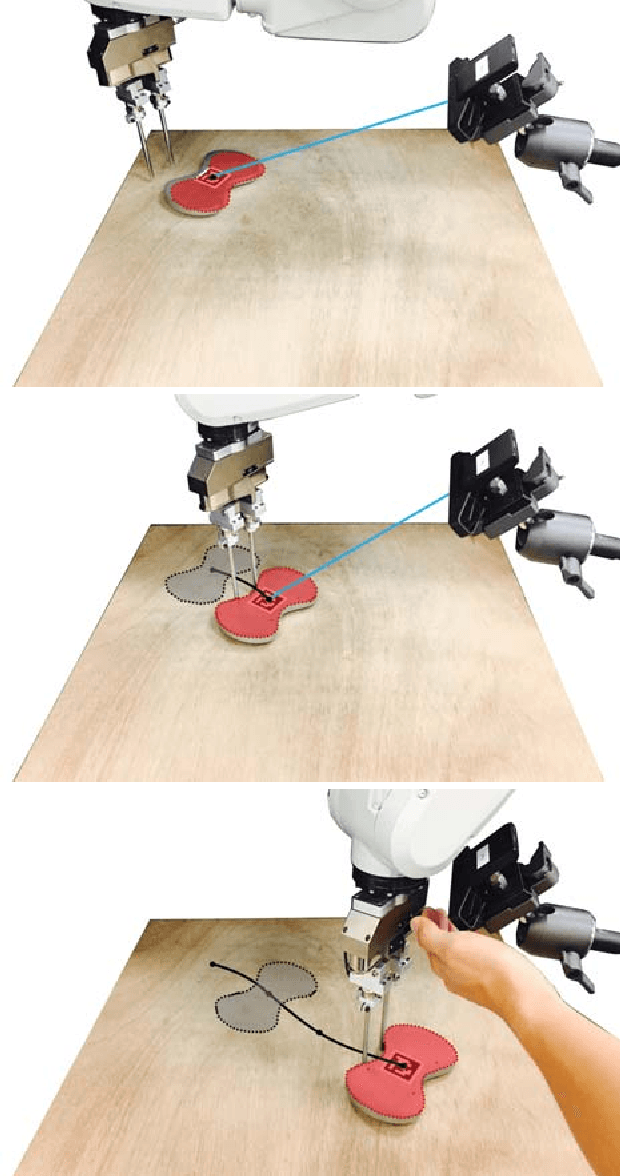
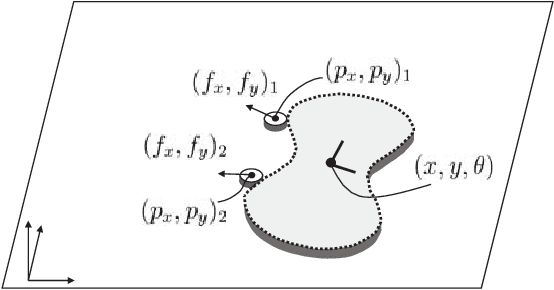
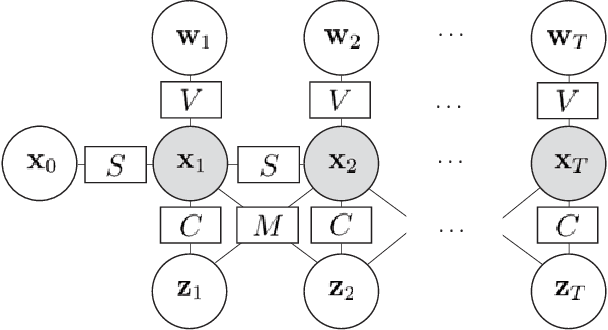
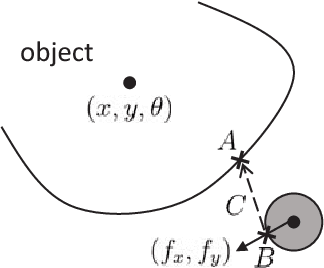
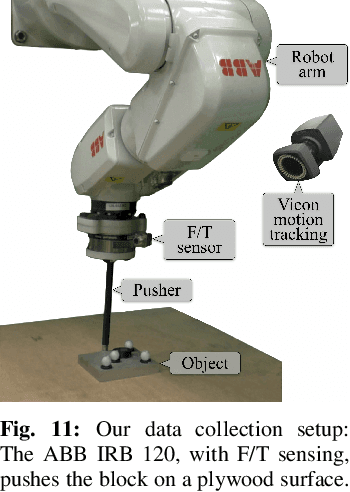
Accurate and robust object state estimation enables successful object manipulation. Visual sensing is widely used to estimate object poses. However, in a cluttered scene or in a tight workspace, the robot's end-effector often occludes the object from the visual sensor. The robot then loses visual feedback and must fall back on open-loop execution. In this paper, we integrate both tactile and visual input using a framework for solving the SLAM problem, incremental smoothing and mapping (iSAM), to provide a fast and flexible solution. Visual sensing provides global pose information but is noisy in general, whereas contact sensing is local, but its measurements are more accurate relative to the end-effector. By combining them, we aim to exploit their advantages and overcome their limitations. We explore the technique in the context of a pusher-slider system. We adapt iSAM's measurement cost and motion cost to the pushing scenario, and use an instrumented setup to evaluate the estimation quality with different object shapes, on different surface materials, and under different contact modes.
Robotic Pick-and-Place of Novel Objects in Clutter with Multi-Affordance Grasping and Cross-Domain Image Matching
Apr 01, 2018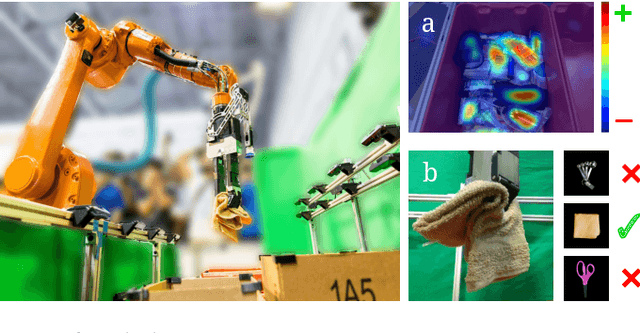


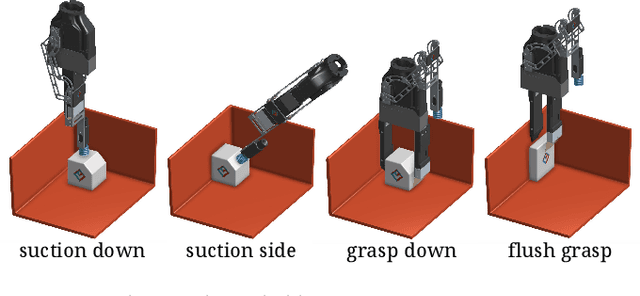
This paper presents a robotic pick-and-place system that is capable of grasping and recognizing both known and novel objects in cluttered environments. The key new feature of the system is that it handles a wide range of object categories without needing any task-specific training data for novel objects. To achieve this, it first uses a category-agnostic affordance prediction algorithm to select and execute among four different grasping primitive behaviors. It then recognizes picked objects with a cross-domain image classification framework that matches observed images to product images. Since product images are readily available for a wide range of objects (e.g., from the web), the system works out-of-the-box for novel objects without requiring any additional training data. Exhaustive experimental results demonstrate that our multi-affordance grasping achieves high success rates for a wide variety of objects in clutter, and our recognition algorithm achieves high accuracy for both known and novel grasped objects. The approach was part of the MIT-Princeton Team system that took 1st place in the stowing task at the 2017 Amazon Robotics Challenge. All code, datasets, and pre-trained models are available online at http://arc.cs.princeton.edu
Realtime State Estimation with Tactile and Visual Sensing for Inserting a Suction-held Object
Mar 21, 2018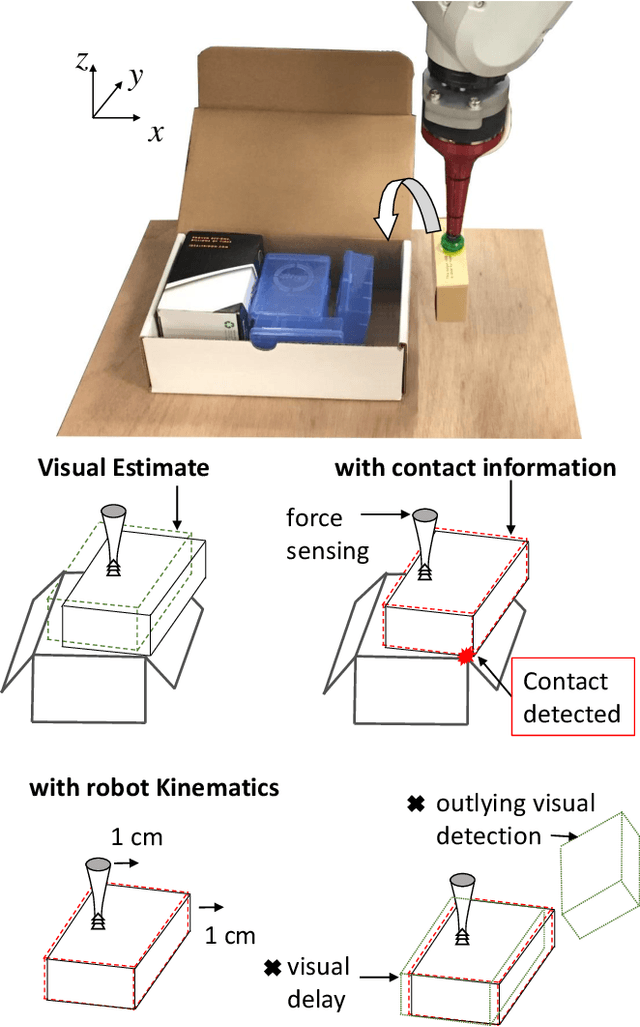
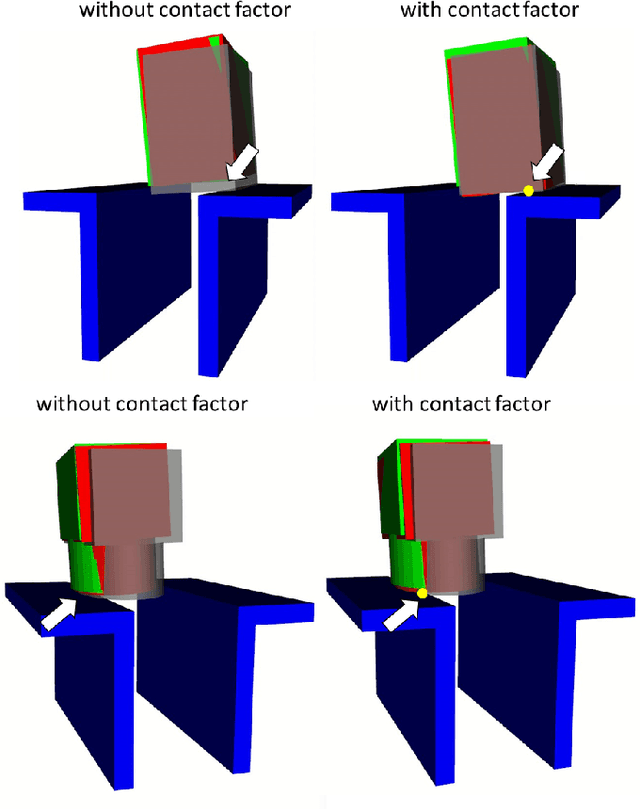
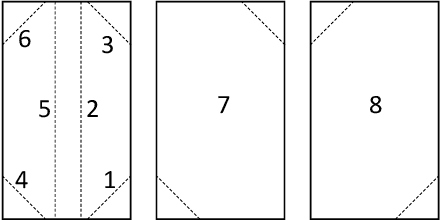
We develop a real-time state estimation system to recover the pose and contact formation of an object relative to its environment. In this paper, we focus on the application of inserting an object picked by a suction cup into a tight space, an enabling technology for robotic packaging. We propose a framework that fuses force and visual sensing for improved accuracy and robustness. Visual sensing is versatile and non-intrusive, but suffers from occlusions and limited accuracy, especially for tasks involving contact. Tactile sensing is local, but provides accuracy and robustness to occlusions. The proposed algorithm to fuse them is based on iSAM, an on-line optimization technique, which we use to incorporate kinematic measurements from the robot, contact geometry of the object and the container, and visual tracking. In this paper, we generalize previous results in planar settings to a 3D task with more complex contact interactions. A key challenge in using force sensing is that we do not observe contact point locations directly. We propose a data-driven method to infer the contact formation, which is then used in real-time by the state estimator. We demonstrate and evaluate the algorithm in a setup instrumented to provide groundtruth.
Multi-view Self-supervised Deep Learning for 6D Pose Estimation in the Amazon Picking Challenge
May 07, 2017

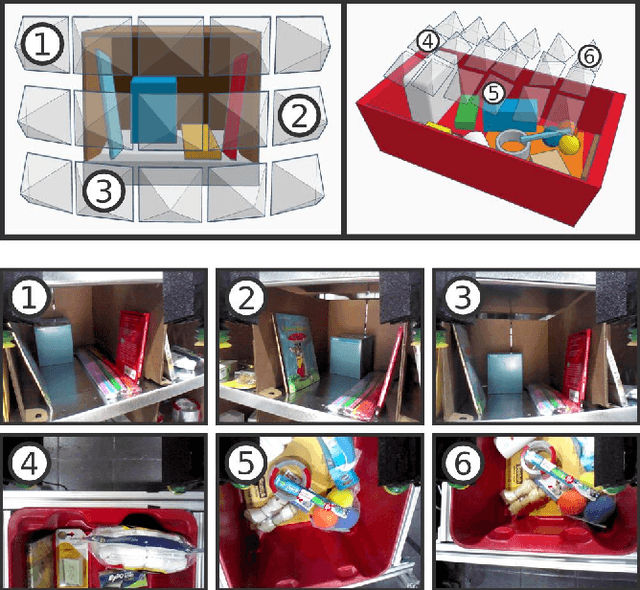
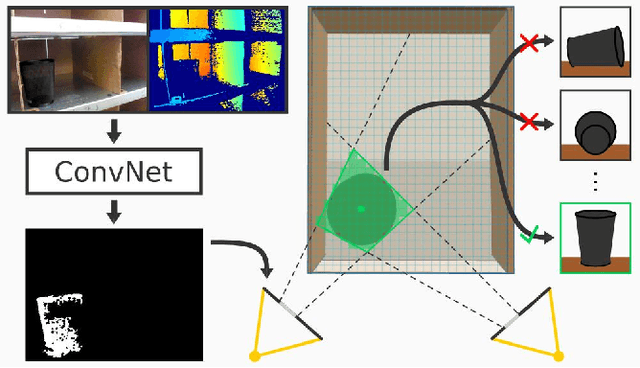
Robot warehouse automation has attracted significant interest in recent years, perhaps most visibly in the Amazon Picking Challenge (APC). A fully autonomous warehouse pick-and-place system requires robust vision that reliably recognizes and locates objects amid cluttered environments, self-occlusions, sensor noise, and a large variety of objects. In this paper we present an approach that leverages multi-view RGB-D data and self-supervised, data-driven learning to overcome those difficulties. The approach was part of the MIT-Princeton Team system that took 3rd- and 4th- place in the stowing and picking tasks, respectively at APC 2016. In the proposed approach, we segment and label multiple views of a scene with a fully convolutional neural network, and then fit pre-scanned 3D object models to the resulting segmentation to get the 6D object pose. Training a deep neural network for segmentation typically requires a large amount of training data. We propose a self-supervised method to generate a large labeled dataset without tedious manual segmentation. We demonstrate that our system can reliably estimate the 6D pose of objects under a variety of scenarios. All code, data, and benchmarks are available at http://apc.cs.princeton.edu/
More than a Million Ways to Be Pushed: A High-Fidelity Experimental Dataset of Planar Pushing
Aug 04, 2016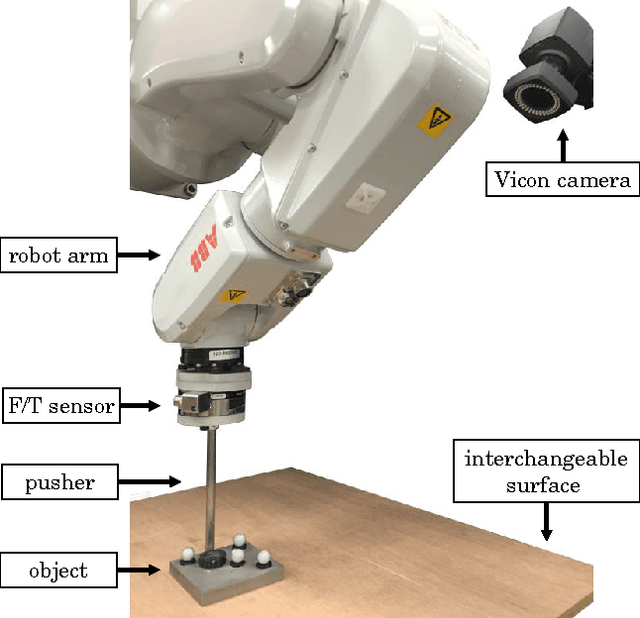
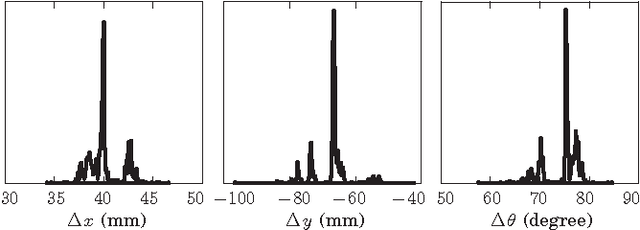

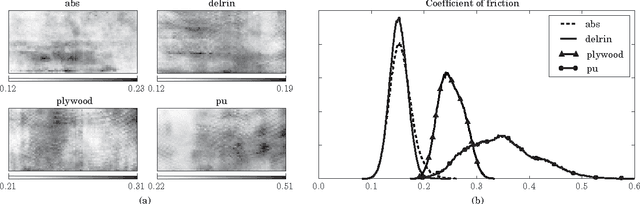
Pushing is a motion primitive useful to handle objects that are too large, too heavy, or too cluttered to be grasped. It is at the core of much of robotic manipulation, in particular when physical interaction is involved. It seems reasonable then to wish for robots to understand how pushed objects move. In reality, however, robots often rely on approximations which yield models that are computable, but also restricted and inaccurate. Just how close are those models? How reasonable are the assumptions they are based on? To help answer these questions, and to get a better experimental understanding of pushing, we present a comprehensive and high-fidelity dataset of planar pushing experiments. The dataset contains timestamped poses of a circular pusher and a pushed object, as well as forces at the interaction.We vary the push interaction in 6 dimensions: surface material, shape of the pushed object, contact position, pushing direction, pushing speed, and pushing acceleration. An industrial robot automates the data capturing along precisely controlled position-velocity-acceleration trajectories of the pusher, which give dense samples of positions and forces of uniform quality. We finish the paper by characterizing the variability of friction, and evaluating the most common assumptions and simplifications made by models of frictional pushing in robotics.
* 8 pages, 10 figures
A Summary of Team MIT's Approach to the Amazon Picking Challenge 2015
Apr 13, 2016

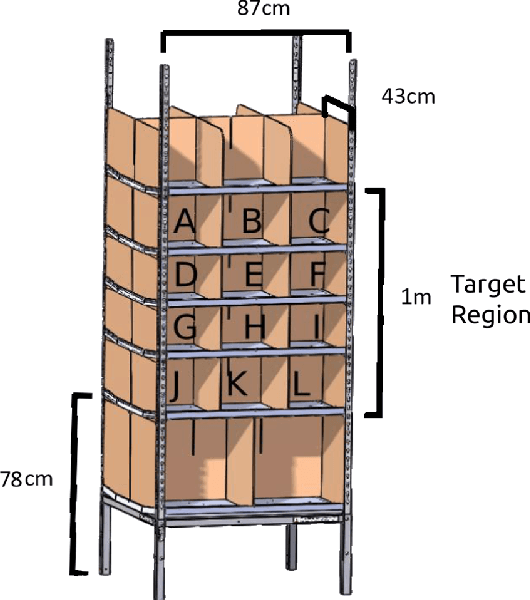

The Amazon Picking Challenge (APC), held alongside the International Conference on Robotics and Automation in May 2015 in Seattle, challenged roboticists from academia and industry to demonstrate fully automated solutions to the problem of picking objects from shelves in a warehouse fulfillment scenario. Packing density, object variability, speed, and reliability are the main complexities of the task. The picking challenge serves both as a motivation and an instrument to focus research efforts on a specific manipulation problem. In this document, we describe Team MIT's approach to the competition, including design considerations, contributions, and performance, and we compile the lessons learned. We also describe what we think are the main remaining challenges.