 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural feels with neural fields: Visuo-tactile perception for in-hand manipulation
Dec 20, 2023To achieve human-level dexterity, robots must infer spatial awareness from multimodal sensing to reason over contact interactions. During in-hand manipulation of novel objects, such spatial awareness involves estimating the object's pose and shape. The status quo for in-hand perception primarily employs vision, and restricts to tracking a priori known objects. Moreover, visual occlusion of objects in-hand is imminent during manipulation, preventing current systems to push beyond tasks without occlusion. We combine vision and touch sensing on a multi-fingered hand to estimate an object's pose and shape during in-hand manipulation. Our method, NeuralFeels, encodes object geometry by learning a neural field online and jointly tracks it by optimizing a pose graph problem. We study multimodal in-hand perception in simulation and the real-world, interacting with different objects via a proprioception-driven policy. Our experiments show final reconstruction F-scores of $81$% and average pose drifts of $4.7\,\text{mm}$, further reduced to $2.3\,\text{mm}$ with known CAD models. Additionally, we observe that under heavy visual occlusion we can achieve up to $94$% improvements in tracking compared to vision-only methods. Our results demonstrate that touch, at the very least, refines and, at the very best, disambiguates visual estimates during in-hand manipulation. We release our evaluation dataset of 70 experiments, FeelSight, as a step towards benchmarking in this domain. Our neural representation driven by multimodal sensing can serve as a perception backbone towards advancing robot dexterity. Videos can be found on our project website https://suddhu.github.io/neural-feels/
General In-Hand Object Rotation with Vision and Touch
Sep 28, 2023We introduce RotateIt, a system that enables fingertip-based object rotation along multiple axes by leveraging multimodal sensory inputs. Our system is trained in simulation, where it has access to ground-truth object shapes and physical properties. Then we distill it to operate on realistic yet noisy simulated visuotactile and proprioceptive sensory inputs. These multimodal inputs are fused via a visuotactile transformer, enabling online inference of object shapes and physical properties during deployment. We show significant performance improvements over prior methods and the importance of visual and tactile sensing.
MidasTouch: Monte-Carlo inference over distributions across sliding touch
Oct 25, 2022



We present MidasTouch, a tactile perception system for online global localization of a vision-based touch sensor sliding on an object surface. This framework takes in posed tactile images over time, and outputs an evolving distribution of sensor pose on the object's surface, without the need for visual priors. Our key insight is to estimate local surface geometry with tactile sensing, learn a compact representation for it, and disambiguate these signals over a long time horizon. The backbone of MidasTouch is a Monte-Carlo particle filter, with a measurement model based on a tactile code network learned from tactile simulation. This network, inspired by LIDAR place recognition, compactly summarizes local surface geometries. These generated codes are efficiently compared against a precomputed tactile codebook per-object, to update the pose distribution. We further release the YCB-Slide dataset of real-world and simulated forceful sliding interactions between a vision-based tactile sensor and standard YCB objects. While single-touch localization can be inherently ambiguous, we can quickly localize our sensor by traversing salient surface geometries. Project page: https://suddhu.github.io/midastouch-tactile/
Efficient shape mapping through dense touch and vision
Sep 20, 2021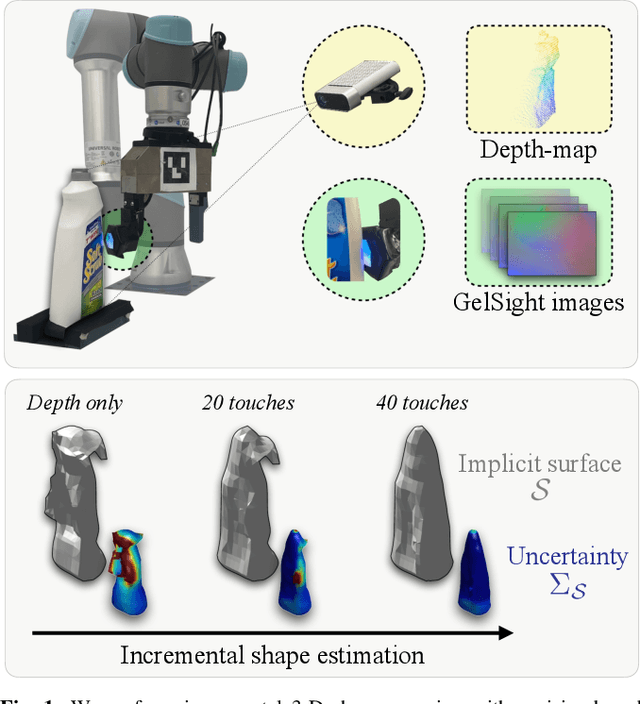
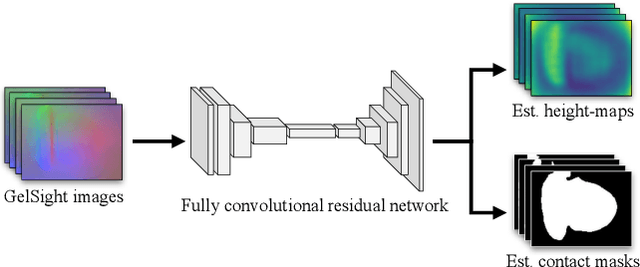

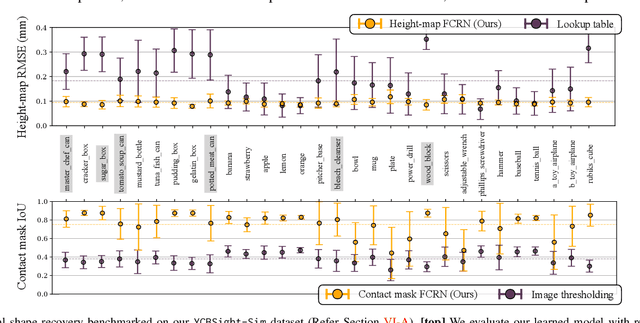
Knowledge of 3-D object shape is of great importance to robot manipulation tasks, but may not be readily available in unstructured environments. While vision is often occluded during robot-object interaction, high-resolution tactile sensors can give a dense local perspective of the object. However, tactile sensors have limited sensing area and the shape representation must faithfully approximate non-contact areas. In addition, a key challenge is efficiently incorporating these dense tactile measurements into a 3-D mapping framework. In this work, we propose an incremental shape mapping method using a GelSight tactile sensor and a depth camera. Local shape is recovered from tactile images via a learned model trained in simulation. Through efficient inference on a spatial factor graph informed by a Gaussian process, we build an implicit surface representation of the object. We demonstrate visuo-tactile mapping in both simulated and real-world experiments, to incrementally build 3-D reconstructions of household objects.
Tactile SLAM: Real-time inference of shape and pose from planar pushing
Nov 13, 2020

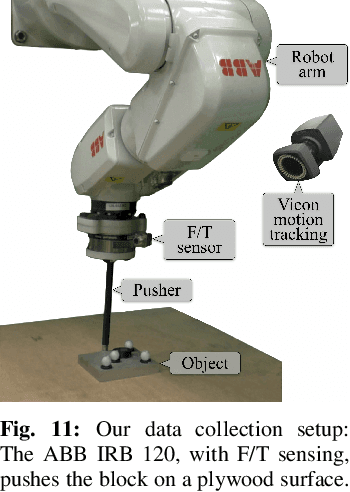
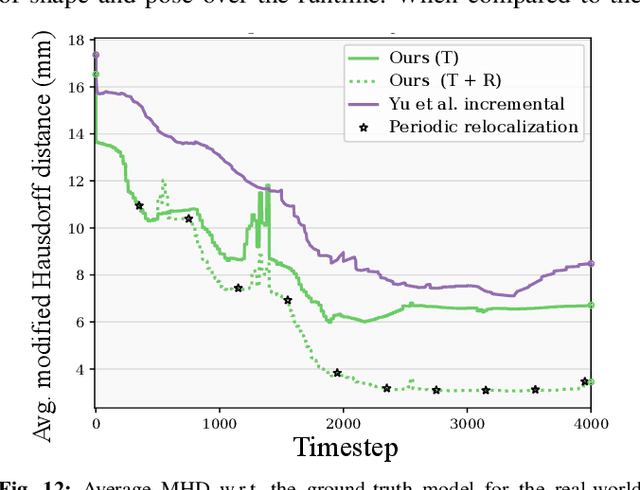
Tactile perception is central to robot manipulation in unstructured environments. However, it requires contact, and a mature implementation must infer object models while also accounting for the motion induced by the interaction. In this work, we present a method to estimate both object shape and pose in real-time from a stream of tactile measurements. This is applied towards tactile exploration of an unknown object by planar pushing. We consider this as an online SLAM problem with a nonparametric shape representation. Our formulation of tactile inference alternates between Gaussian process implicit surface regression and pose estimation on a factor graph. Through a combination of local Gaussian processes and fixed-lag smoothing, we infer object shape and pose in real-time. We evaluate our system across different objects in both simulated and real-world planar pushing tasks.
DeepGeo: Photo Localization with Deep Neural Network
Oct 07, 2018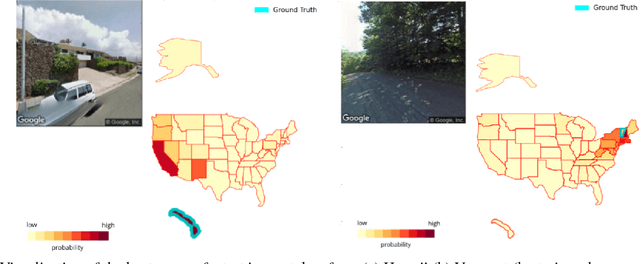
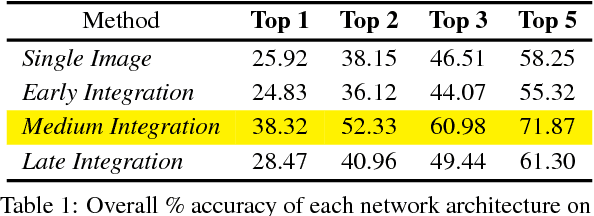

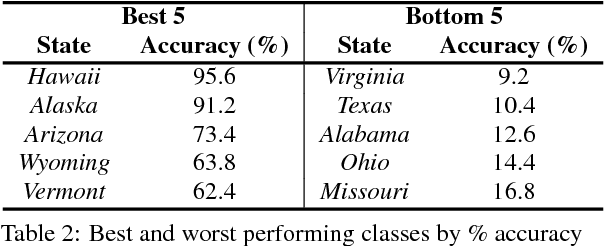
In this paper we address the task of determining the geographical location of an image, a pertinent problem in learning and computer vision. This research was inspired from playing GeoGuessr, a game that tests a humans' ability to localize themselves using just images of their surroundings. In particular, we wish to investigate how geographical, ecological and man-made features generalize for random location prediction. This is framed as a classification problem: given images sampled from the USA, the most-probable state among 50 is predicted. Previous work uses models extensively trained on large, unfiltered online datasets that are primed towards specific locations. To this end, we create (and open-source) the 50States10K dataset - with 0.5 million Google Street View images of the country. A deep neural network based on the ResNet architecture is trained, and four different strategies of incorporating low-level cardinality information are presented. This model achieves an accuracy 20 times better than chance on a test dataset, which rises to 71.87% when taking the best of top-5 guesses. The network also beats human subjects in 4 out of 5 rounds of GeoGuessr.
Object category understanding via eye fixations on freehand sketches
Mar 20, 2017
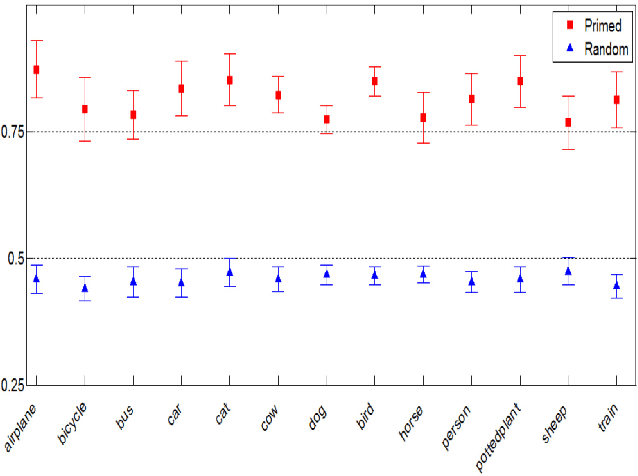
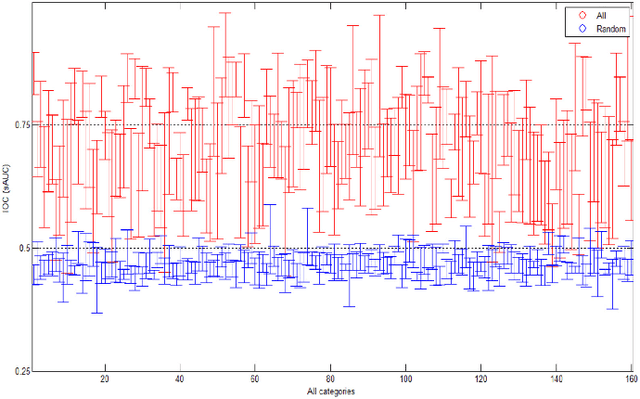
The study of eye gaze fixations on photographic images is an active research area. In contrast, the image subcategory of freehand sketches has not received as much attention for such studies. In this paper, we analyze the results of a free-viewing gaze fixation study conducted on 3904 freehand sketches distributed across 160 object categories. Our analysis shows that fixation sequences exhibit marked consistency within a sketch, across sketches of a category and even across suitably grouped sets of categories. This multi-level consistency is remarkable given the variability in depiction and extreme image content sparsity that characterizes hand-drawn object sketches. In our paper, we show that the multi-level consistency in the fixation data can be exploited to (a) predict a test sketch's category given only its fixation sequence and (b) build a computational model which predicts part-labels underlying fixations on objects. We hope that our findings motivate the community to deem sketch-like representations worthy of gaze-based studies vis-a-vis photographic images.