 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Map and Object Reconstruction
Jun 19, 2024
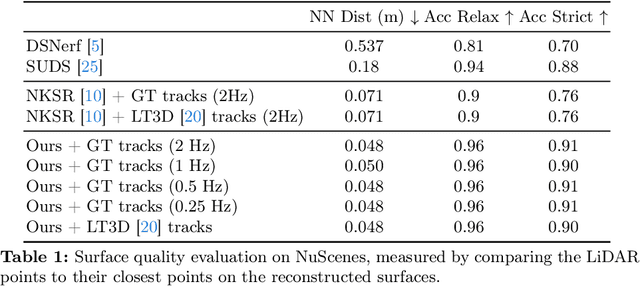

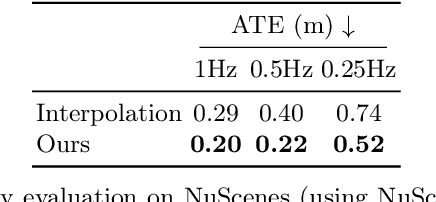
In this paper, we present a method for dynamic surface reconstruction of large-scale urban scenes from LiDAR. Depth-based reconstructions tend to focus on small-scale objects or large-scale SLAM reconstructions that treat moving objects as outliers. We take a holistic perspective and optimize a compositional model of a dynamic scene that decomposes the world into rigidly moving objects and the background. To achieve this, we take inspiration from recent novel view synthesis methods and pose the reconstruction problem as a global optimization, minimizing the distance between our predicted surface and the input LiDAR scans. We show how this global optimization can be decomposed into registration and surface reconstruction steps, which are handled well by off-the-shelf methods without any re-training. By careful modeling of continuous-time motion, our reconstructions can compensate for the rolling shutter effects of rotating LiDAR sensors. This allows for the first system (to our knowledge) that properly motion compensates LiDAR scans for rigidly-moving objects, complementing widely-used techniques for motion compensation of static scenes. Beyond pursuing dynamic reconstruction as a goal in and of itself, we also show that such a system can be used to auto-label partially annotated sequences and produce ground truth annotation for hard-to-label problems such as depth completion and scene flow.
ZeroFlow: Fast Zero Label Scene Flow via Distillation
May 23, 2023



Scene flow estimation is the task of describing the 3D motion field between temporally successive point clouds. State-of-the-art methods use strong priors and test-time optimization techniques, but require on the order of tens of seconds for large-scale point clouds, making them unusable as computer vision primitives for real-time applications such as open world object detection. Feed forward methods are considerably faster, running on the order of tens to hundreds of milliseconds for large-scale point clouds, but require expensive human supervision. To address both limitations, we propose Scene Flow via Distillation, a simple distillation framework that uses a label-free optimization method to produce pseudo-labels to supervise a feed forward model. Our instantiation of this framework, ZeroFlow, produces scene flow estimates in real-time on large-scale point clouds at quality competitive with state-of-the-art methods while using zero human labels. Notably, at test-time ZeroFlow is over 1000$\times$ faster than label-free state-of-the-art optimization-based methods on large-scale point clouds and over 1000$\times$ cheaper to train on unlabeled data compared to the cost of human annotation of that data. To facilitate research reuse, we release our code, trained model weights, and high quality pseudo-labels for the Argoverse 2 and Waymo Open datasets.
Re-Evaluating LiDAR Scene Flow for Autonomous Driving
Apr 04, 2023Current methods for self-supervised LiDAR scene flow estimation work poorly on real data. A variety of flaws in common evaluation protocols have caused leading approaches to focus on problems that do not exist in real data. We analyze a suite of recent works and find that despite their focus on deep learning, the main challenges of the LiDAR scene flow problem -- removing the dominant rigid motion and robustly estimating the simple motions that remain -- can be more effectively solved with classical techniques such as ICP motion compensation and enforcing piecewise rigid assumptions. We combine these steps with a test-time optimization method to form a state-of-the-art system that does not require any training data. Because our final approach is dataless, it can be applied on different datasets with diverse LiDAR rigs without retraining. Our proposed approach outperforms all existing methods on Argoverse 2.0, halves the error rate on NuScenes, and even rivals the performance of supervised networks on Waymo and lidarKITTI.
When to Use Convolutional Neural Networks for Inverse Problems
Mar 30, 2020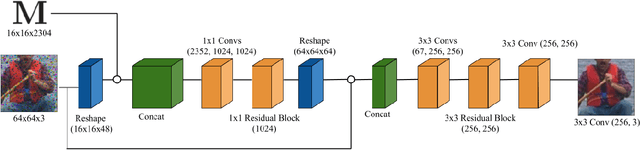

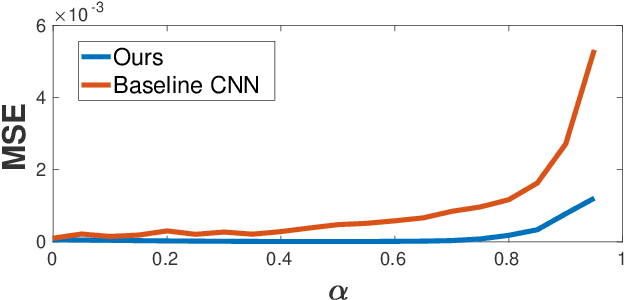
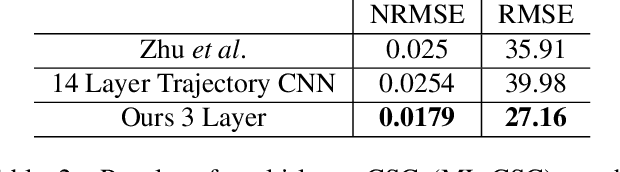
Reconstruction tasks in computer vision aim fundamentally to recover an undetermined signal from a set of noisy measurements. Examples include super-resolution, image denoising, and non-rigid structure from motion, all of which have seen recent advancements through deep learning. However, earlier work made extensive use of sparse signal reconstruction frameworks (e.g convolutional sparse coding). While this work was ultimately surpassed by deep learning, it rested on a much more developed theoretical framework. Recent work by Papyan et. al provides a bridge between the two approaches by showing how a convolutional neural network (CNN) can be viewed as an approximate solution to a convolutional sparse coding (CSC) problem. In this work we argue that for some types of inverse problems the CNN approximation breaks down leading to poor performance. We argue that for these types of problems the CSC approach should be used instead and validate this argument with empirical evidence. Specifically we identify JPEG artifact reduction and non-rigid trajectory reconstruction as challenging inverse problems for CNNs and demonstrate state of the art performance on them using a CSC method. Furthermore, we offer some practical improvements to this model and its application, and also show how insights from the CSC model can be used to make CNNs effective in tasks where their naive application fails.
DeepGeo: Photo Localization with Deep Neural Network
Oct 07, 2018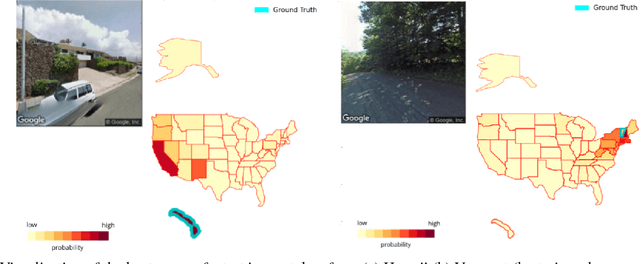
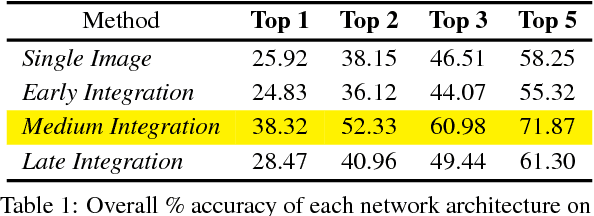

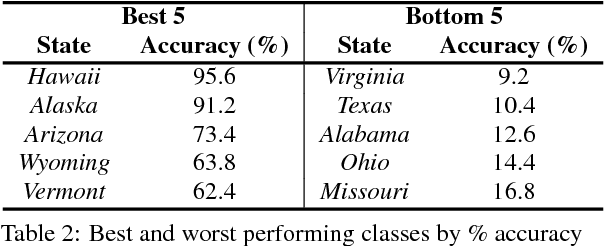
In this paper we address the task of determining the geographical location of an image, a pertinent problem in learning and computer vision. This research was inspired from playing GeoGuessr, a game that tests a humans' ability to localize themselves using just images of their surroundings. In particular, we wish to investigate how geographical, ecological and man-made features generalize for random location prediction. This is framed as a classification problem: given images sampled from the USA, the most-probable state among 50 is predicted. Previous work uses models extensively trained on large, unfiltered online datasets that are primed towards specific locations. To this end, we create (and open-source) the 50States10K dataset - with 0.5 million Google Street View images of the country. A deep neural network based on the ResNet architecture is trained, and four different strategies of incorporating low-level cardinality information are presented. This model achieves an accuracy 20 times better than chance on a test dataset, which rises to 71.87% when taking the best of top-5 guesses. The network also beats human subjects in 4 out of 5 rounds of GeoGuessr.
Deep Convolutional Compressed Sensing for LiDAR Depth Completion
Mar 23, 2018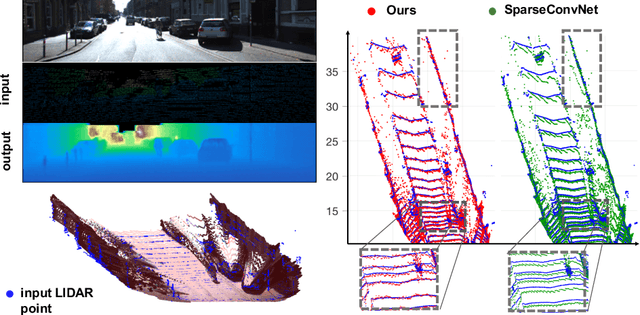
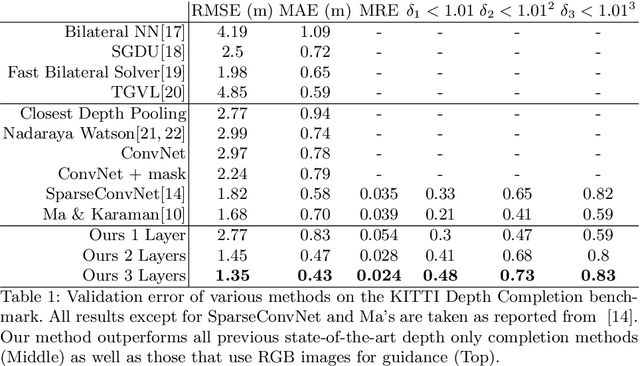
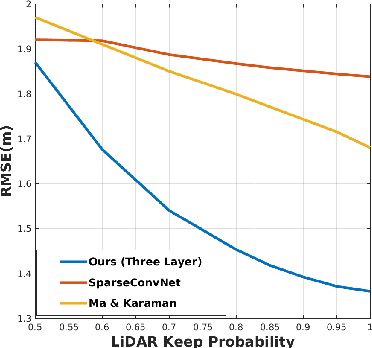
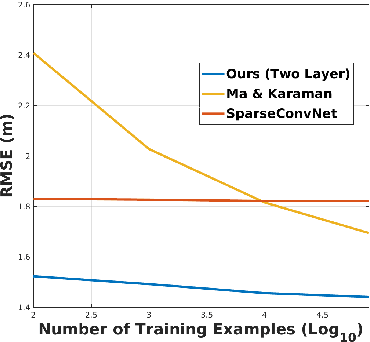
In this paper we consider the problem of estimating a dense depth map from a set of sparse LiDAR points. We use techniques from compressed sensing and the recently developed Alternating Direction Neural Networks (ADNNs) to create a deep recurrent auto-encoder for this task. Our architecture internally performs an algorithm for extracting multi-level convolutional sparse codes from the input which are then used to make a prediction. Our results demonstrate that with only two layers and 1800 parameters we are able to out perform all previously published results, including deep networks with orders of magnitude more parameters.