 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEM: Multi-Scale Embodied Memory for Vision Language Action Models
Mar 04, 2026Conventionally, memory in end-to-end robotic learning involves inputting a sequence of past observations into the learned policy. However, in complex multi-stage real-world tasks, the robot's memory must represent past events at multiple levels of granularity: from long-term memory that captures abstracted semantic concepts (e.g., a robot cooking dinner should remember which stages of the recipe are already done) to short-term memory that captures recent events and compensates for occlusions (e.g., a robot remembering the object it wants to pick up once its arm occludes it). In this work, our main insight is that an effective memory architecture for long-horizon robotic control should combine multiple modalities to capture these different levels of abstraction. We introduce Multi-Scale Embodied Memory (MEM), an approach for mixed-modal long-horizon memory in robot policies. MEM combines video-based short-horizon memory, compressed via a video encoder, with text-based long-horizon memory. Together, they enable robot policies to perform tasks that span up to fifteen minutes, like cleaning up a kitchen, or preparing a grilled cheese sandwich. Additionally, we find that memory enables MEM policies to intelligently adapt manipulation strategies in-context.
Toward Scalable, Flexible Scene Flow for Point Clouds
Mar 19, 2025Scene flow estimation is the task of describing 3D motion between temporally successive observations. This thesis aims to build the foundation for building scene flow estimators with two important properties: they are scalable, i.e. they improve with access to more data and computation, and they are flexible, i.e. they work out-of-the-box in a variety of domains and on a variety of motion patterns without requiring significant hyperparameter tuning. In this dissertation we present several concrete contributions towards this. In Chapter 1 we contextualize scene flow and its prior methods. In Chapter 2 we present a blueprint to build and scale feedforward scene flow estimators without requiring expensive human annotations via large scale distillation from pseudolabels provided by strong unsupervised test-time optimization methods. In Chapter 3 we introduce a benchmark to better measure estimate quality across diverse object types, better bringing into focus what we care about and expect from scene flow estimators, and use this benchmark to host a public challenge that produced significant progress. In Chapter 4 we present a state-of-the-art unsupervised scene flow estimator that introduces a new, full sequence problem formulation and exhibits great promise in adjacent domains like 3D point tracking. Finally, in Chapter 5 I philosophize about what's next for scene flow and its potential future broader impacts.
Scene Flow as a Partial Differential Equation
Oct 02, 2024



We reframe scene flow as the problem of estimating a continuous space and time PDE that describes motion for an entire observation sequence, represented with a neural prior. Our resulting unsupervised method, EulerFlow, produces high quality scene flow on real-world data across multiple domains, including large-scale autonomous driving scenes and dynamic tabletop settings. Notably, EulerFlow produces high quality flow on small, fast moving objects like birds and tennis balls, and exhibits emergent 3D point tracking behavior by solving its estimated PDE over long time horizons. On the Argoverse 2 2024 Scene Flow Challenge, EulerFlow outperforms all prior art, beating the next best unsupervised method by over 2.5x and the next best supervised method by over 10%.
I Can't Believe It's Not Scene Flow!
Mar 07, 2024



Current scene flow methods broadly fail to describe motion on small objects, and current scene flow evaluation protocols hide this failure by averaging over many points, with most drawn larger objects. To fix this evaluation failure, we propose a new evaluation protocol, Bucket Normalized EPE, which is class-aware and speed-normalized, enabling contextualized error comparisons between object types that move at vastly different speeds. To highlight current method failures, we propose a frustratingly simple supervised scene flow baseline, TrackFlow, built by bolting a high-quality pretrained detector (trained using many class rebalancing techniques) onto a simple tracker, that produces state-of-the-art performance on current standard evaluations and large improvements over prior art on our new evaluation. Our results make it clear that all scene flow evaluations must be class and speed aware, and supervised scene flow methods must address point class imbalances. We release the evaluation code publicly at https://github.com/kylevedder/BucketedSceneFlowEval.
ZeroFlow: Fast Zero Label Scene Flow via Distillation
May 23, 2023



Scene flow estimation is the task of describing the 3D motion field between temporally successive point clouds. State-of-the-art methods use strong priors and test-time optimization techniques, but require on the order of tens of seconds for large-scale point clouds, making them unusable as computer vision primitives for real-time applications such as open world object detection. Feed forward methods are considerably faster, running on the order of tens to hundreds of milliseconds for large-scale point clouds, but require expensive human supervision. To address both limitations, we propose Scene Flow via Distillation, a simple distillation framework that uses a label-free optimization method to produce pseudo-labels to supervise a feed forward model. Our instantiation of this framework, ZeroFlow, produces scene flow estimates in real-time on large-scale point clouds at quality competitive with state-of-the-art methods while using zero human labels. Notably, at test-time ZeroFlow is over 1000$\times$ faster than label-free state-of-the-art optimization-based methods on large-scale point clouds and over 1000$\times$ cheaper to train on unlabeled data compared to the cost of human annotation of that data. To facilitate research reuse, we release our code, trained model weights, and high quality pseudo-labels for the Argoverse 2 and Waymo Open datasets.
A Domain-Agnostic Approach for Characterization of Lifelong Learning Systems
Jan 18, 2023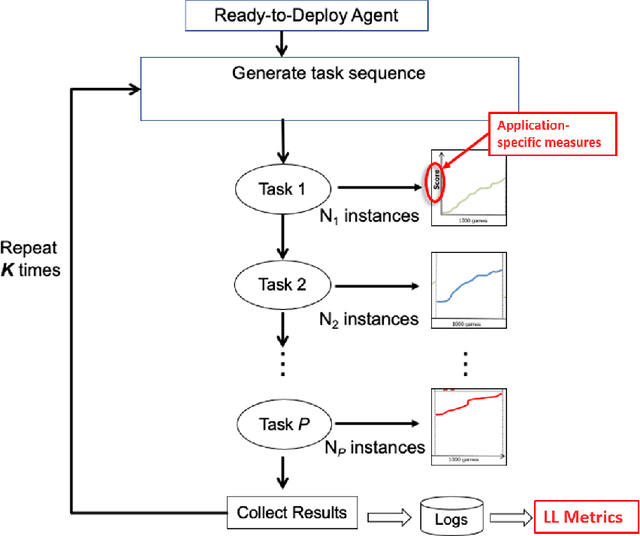


Despite the advancement of machine learning techniques in recent years, state-of-the-art systems lack robustness to "real world" events, where the input distributions and tasks encountered by the deployed systems will not be limited to the original training context, and systems will instead need to adapt to novel distributions and tasks while deployed. This critical gap may be addressed through the development of "Lifelong Learning" systems that are capable of 1) Continuous Learning, 2) Transfer and Adaptation, and 3) Scalability. Unfortunately, efforts to improve these capabilities are typically treated as distinct areas of research that are assessed independently, without regard to the impact of each separate capability on other aspects of the system. We instead propose a holistic approach, using a suite of metrics and an evaluation framework to assess Lifelong Learning in a principled way that is agnostic to specific domains or system techniques. Through five case studies, we show that this suite of metrics can inform the development of varied and complex Lifelong Learning systems. We highlight how the proposed suite of metrics quantifies performance trade-offs present during Lifelong Learning system development - both the widely discussed Stability-Plasticity dilemma and the newly proposed relationship between Sample Efficient and Robust Learning. Further, we make recommendations for the formulation and use of metrics to guide the continuing development of Lifelong Learning systems and assess their progress in the future.
Sparse PointPillars: Exploiting Sparsity in Birds-Eye-View Object Detection
Jun 12, 2021



Bird's Eye View (BEV) is a popular representation for processing 3D point clouds, and by its nature is fundamentally sparse. Motivated by the computational limitations of mobile robot platforms, we take a fast high-performance BEV 3D object detector - PointPillars - and modify its backbone to exploit this sparsity, leading to decreased runtimes. We present preliminary results demonstrating decreased runtimes with either the same performance or a modest decrease in performance, which we anticipate will be remedied by model specific hyperparameter tuning. Our work is a first step towards a new class of 3D object detectors that exploit sparsity throughout their entire pipeline in order to reduce runtime and resource usage while maintaining good detection performance.