 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning of Monocular Depth Estimation with Bundle Adjustment, Super-Resolution and Clip Loss
Dec 08, 2018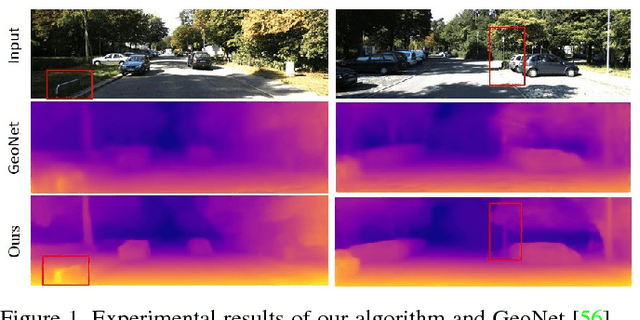
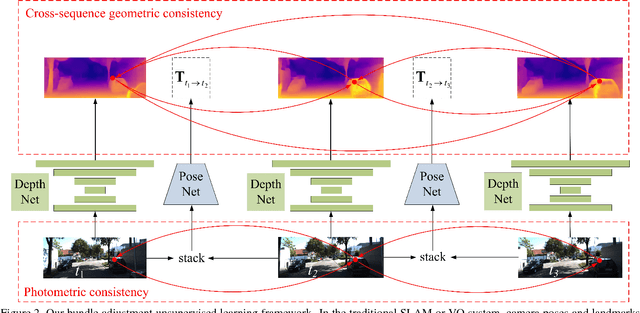
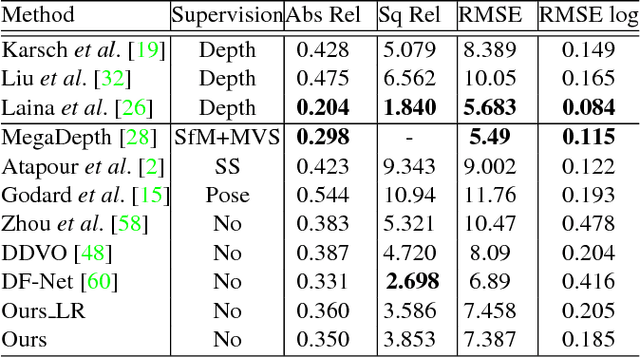
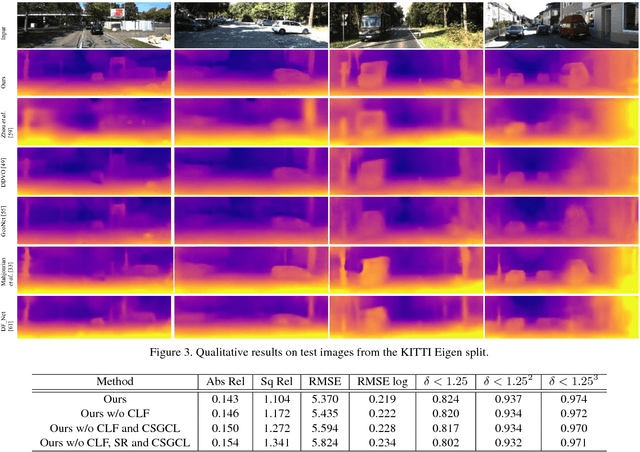
We present a novel unsupervised learning framework for single view depth estimation using monocular videos. It is well known in 3D vision that enlarging the baseline can increase the depth estimation accuracy, and jointly optimizing a set of camera poses and landmarks is essential. In previous monocular unsupervised learning frameworks, only part of the photometric and geometric constraints within a sequence are used as supervisory signals. This may result in a short baseline and overfitting. Besides, previous works generally estimate a low resolution depth from a low resolution impute image. The low resolution depth is then interpolated to recover the original resolution. This strategy may generate large errors on object boundaries, as the depth of background and foreground are mixed to yield the high resolution depth. In this paper, we introduce a bundle adjustment framework and a super-resolution network to solve the above two problems. In bundle adjustment, depths and poses of an image sequence are jointly optimized, which increases the baseline by establishing the relationship between farther frames. The super resolution network learns to estimate a high resolution depth from a low resolution image. Additionally, we introduce the clip loss to deal with moving objects and occlusion. Experimental results on the KITTI dataset show that the proposed algorithm outperforms the state-of-the-art unsupervised methods using monocular sequences, and achieves comparable or even better result compared to unsupervised methods using stereo sequences.
DeepGeo: Photo Localization with Deep Neural Network
Oct 07, 2018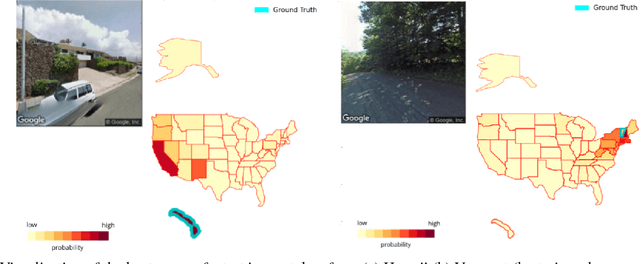
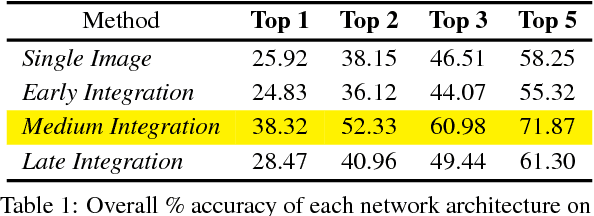

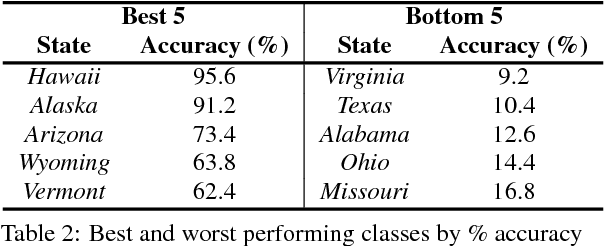
In this paper we address the task of determining the geographical location of an image, a pertinent problem in learning and computer vision. This research was inspired from playing GeoGuessr, a game that tests a humans' ability to localize themselves using just images of their surroundings. In particular, we wish to investigate how geographical, ecological and man-made features generalize for random location prediction. This is framed as a classification problem: given images sampled from the USA, the most-probable state among 50 is predicted. Previous work uses models extensively trained on large, unfiltered online datasets that are primed towards specific locations. To this end, we create (and open-source) the 50States10K dataset - with 0.5 million Google Street View images of the country. A deep neural network based on the ResNet architecture is trained, and four different strategies of incorporating low-level cardinality information are presented. This model achieves an accuracy 20 times better than chance on a test dataset, which rises to 71.87% when taking the best of top-5 guesses. The network also beats human subjects in 4 out of 5 rounds of GeoGuessr.