 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo not Omit Local Minimizer: a Complete Solution for Pose Estimation from 3D Correspondences
Apr 04, 2019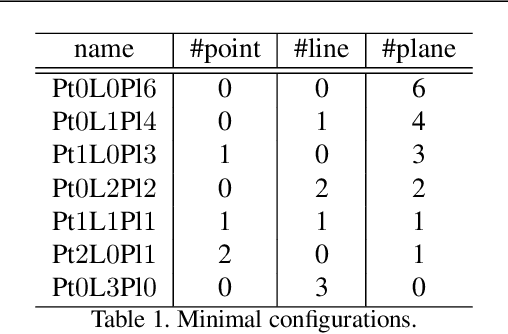
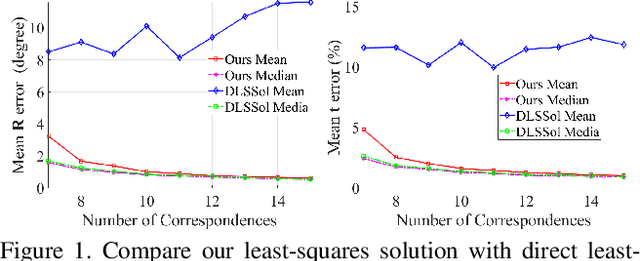

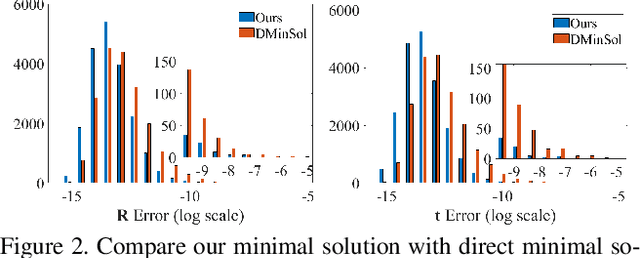
Estimating pose from given 3D correspondences, including point-to-point, point-to-line and point-to-plane correspondences, is a fundamental task in computer vision with many applications. We present a complete solution for this task, including a solution for the minimal problem and the least-squares problem of this task. Previous works mainly focused on finding the global minimizer to address the least-squares problem. However, existing works that show the ability to achieve global minimizer are still unsuitable for real-time applications. Furthermore, as one of contributions of this paper, we prove that there exist ambiguous configurations for any number of lines and planes. These configurations have several solutions in theory, which makes the correct solution may come from a local minimizer. Our algorithm is efficient and able to reveal local minimizers. We employ the Cayley-Gibbs-Rodriguez (CGR) parameterization of the rotation to derive a general rational cost for the three cases of 3D correspondences. The main contribution of this paper is to solve the resulting equation system of the minimal problem and the first-order optimality conditions of the least-squares problem, both of which are of complicated rational forms. The central idea of our algorithm is to introduce intermediate unknowns to simplify the problem. Extensive experimental results show that our algorithm significantly outperforms previous algorithms when the number of correspondences is small. Besides, when the global minimizer is the solution, our algorithm achieves the same accuracy as previous algorithms that have guaranteed global optimality, but our algorithm is applicable to real-time applications.
Unsupervised Learning of Monocular Depth Estimation with Bundle Adjustment, Super-Resolution and Clip Loss
Dec 08, 2018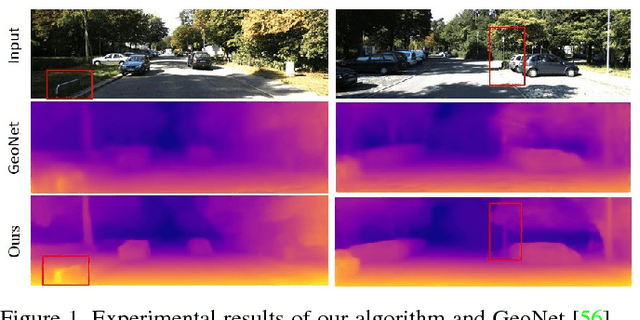
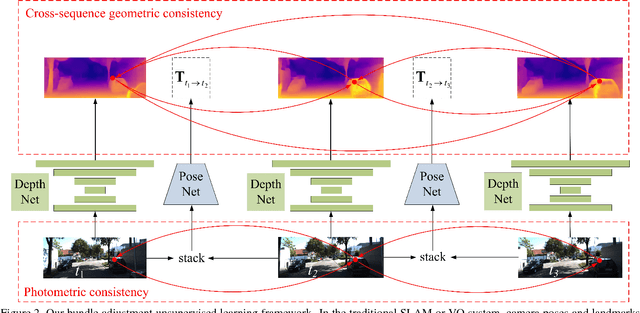
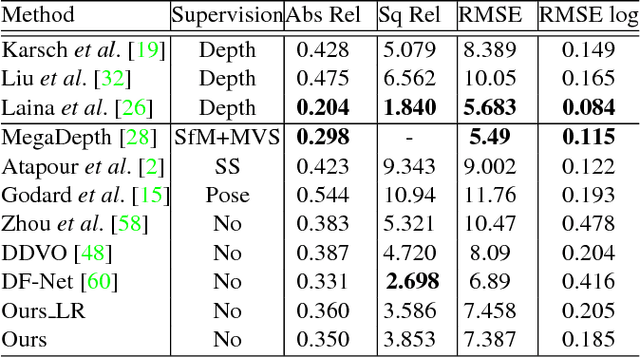
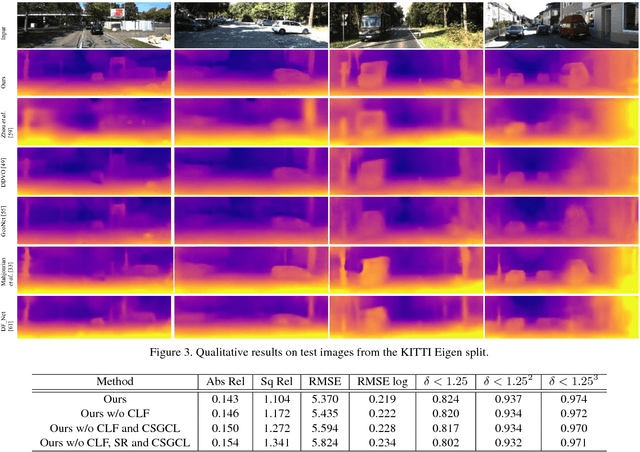
We present a novel unsupervised learning framework for single view depth estimation using monocular videos. It is well known in 3D vision that enlarging the baseline can increase the depth estimation accuracy, and jointly optimizing a set of camera poses and landmarks is essential. In previous monocular unsupervised learning frameworks, only part of the photometric and geometric constraints within a sequence are used as supervisory signals. This may result in a short baseline and overfitting. Besides, previous works generally estimate a low resolution depth from a low resolution impute image. The low resolution depth is then interpolated to recover the original resolution. This strategy may generate large errors on object boundaries, as the depth of background and foreground are mixed to yield the high resolution depth. In this paper, we introduce a bundle adjustment framework and a super-resolution network to solve the above two problems. In bundle adjustment, depths and poses of an image sequence are jointly optimized, which increases the baseline by establishing the relationship between farther frames. The super resolution network learns to estimate a high resolution depth from a low resolution image. Additionally, we introduce the clip loss to deal with moving objects and occlusion. Experimental results on the KITTI dataset show that the proposed algorithm outperforms the state-of-the-art unsupervised methods using monocular sequences, and achieves comparable or even better result compared to unsupervised methods using stereo sequences.