 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Vision Transformers Learn without Natural Images?
Mar 24, 2021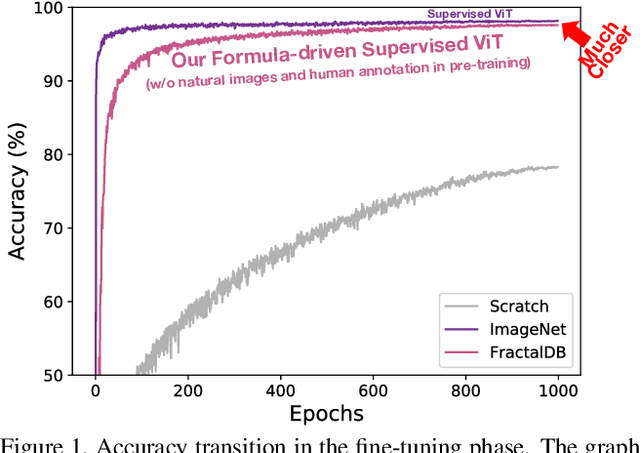
Can we complete pre-training of Vision Transformers (ViT) without natural images and human-annotated labels? Although a pre-trained ViT seems to heavily rely on a large-scale dataset and human-annotated labels, recent large-scale datasets contain several problems in terms of privacy violations, inadequate fairness protection, and labor-intensive annotation. In the present paper, we pre-train ViT without any image collections and annotation labor. We experimentally verify that our proposed framework partially outperforms sophisticated Self-Supervised Learning (SSL) methods like SimCLRv2 and MoCov2 without using any natural images in the pre-training phase. Moreover, although the ViT pre-trained without natural images produces some different visualizations from ImageNet pre-trained ViT, it can interpret natural image datasets to a large extent. For example, the performance rates on the CIFAR-10 dataset are as follows: our proposal 97.6 vs. SimCLRv2 97.4 vs. ImageNet 98.0.
Pre-training without Natural Images
Jan 21, 2021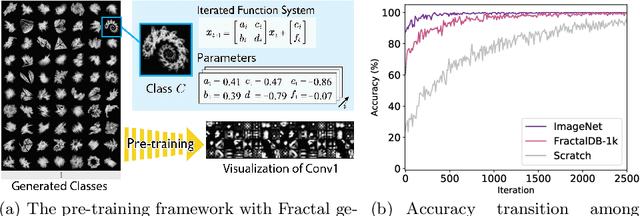
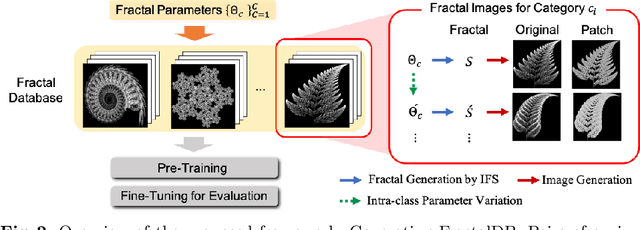

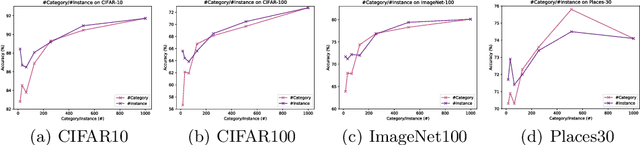
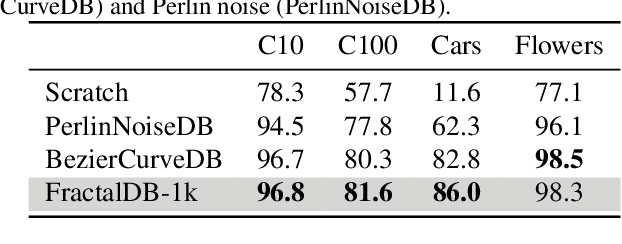
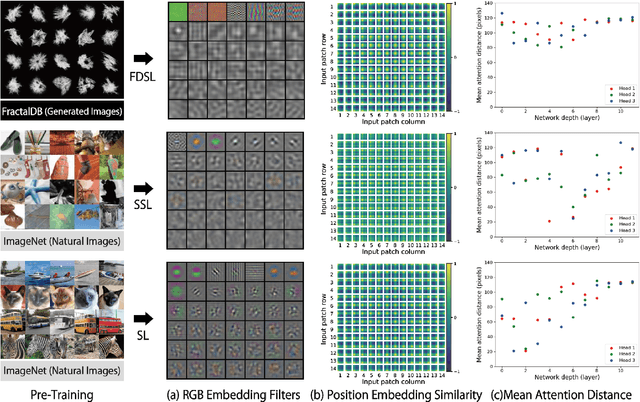
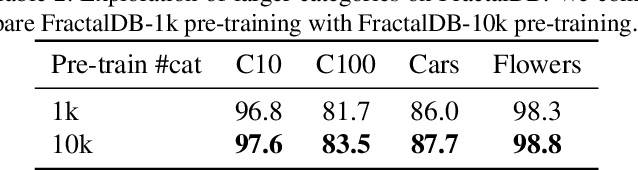
Is it possible to use convolutional neural networks pre-trained without any natural images to assist natural image understanding? The paper proposes a novel concept, Formula-driven Supervised Learning. We automatically generate image patterns and their category labels by assigning fractals, which are based on a natural law existing in the background knowledge of the real world. Theoretically, the use of automatically generated images instead of natural images in the pre-training phase allows us to generate an infinite scale dataset of labeled images. Although the models pre-trained with the proposed Fractal DataBase (FractalDB), a database without natural images, does not necessarily outperform models pre-trained with human annotated datasets at all settings, we are able to partially surpass the accuracy of ImageNet/Places pre-trained models. The image representation with the proposed FractalDB captures a unique feature in the visualization of convolutional layers and attentions.