 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDominant Codewords Selection with Topic Model for Action Recognition
Paper and Code
May 01, 2016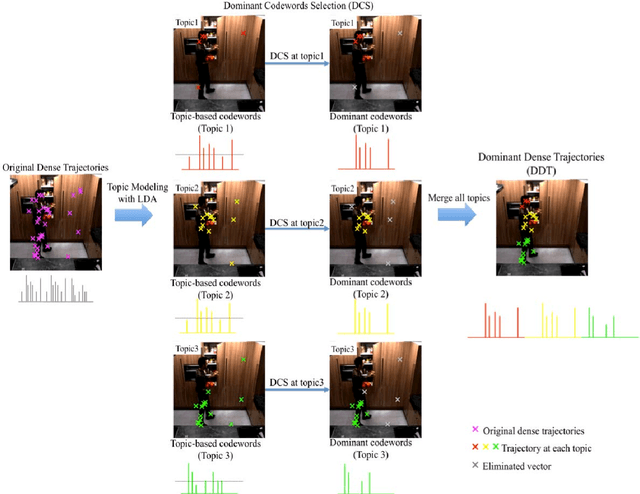
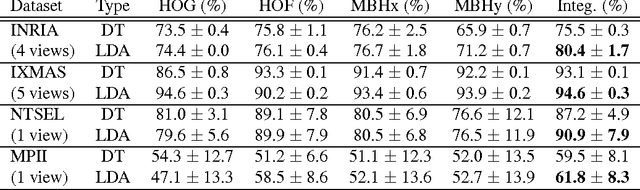

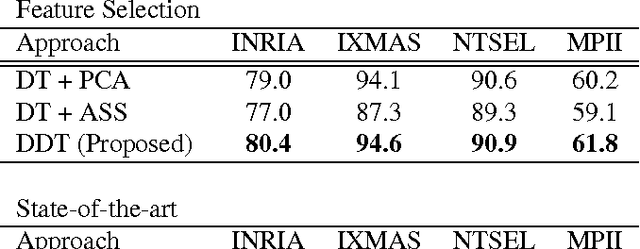
In this paper, we propose a framework for recognizing human activities that uses only in-topic dominant codewords and a mixture of intertopic vectors. Latent Dirichlet allocation (LDA) is used to develop approximations of human motion primitives; these are mid-level representations, and they adaptively integrate dominant vectors when classifying human activities. In LDA topic modeling, action videos (documents) are represented by a bag-of-words (input from a dictionary), and these are based on improved dense trajectories. The output topics correspond to human motion primitives, such as finger moving or subtle leg motion. We eliminate the impurities, such as missed tracking or changing light conditions, in each motion primitive. The assembled vector of motion primitives is an improved representation of the action. We demonstrate our method on four different datasets.