 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetropolis-Hastings Captioning Game: Knowledge Fusion of Vision Language Models via Decentralized Bayesian Inference
Apr 13, 2025We propose the Metropolis-Hastings Captioning Game (MHCG), a method to fuse knowledge of multiple vision-language models (VLMs) by learning from each other. Although existing methods that combine multiple models suffer from inference costs and architectural constraints, MHCG avoids these problems by performing decentralized Bayesian inference through a process resembling a language game. The knowledge fusion process establishes communication between two VLM agents alternately captioning images and learning from each other. We conduct two image-captioning experiments with two VLMs, each pre-trained on a different dataset. The first experiment demonstrates that MHCG achieves consistent improvement in reference-free evaluation metrics. The second experiment investigates how MHCG contributes to sharing VLMs' category-level vocabulary by observing the occurrence of the vocabulary in the generated captions.
Pointing out Human Answer Mistakes in a Goal-Oriented Visual Dialogue
Sep 19, 2023



Effective communication between humans and intelligent agents has promising applications for solving complex problems. One such approach is visual dialogue, which leverages multimodal context to assist humans. However, real-world scenarios occasionally involve human mistakes, which can cause intelligent agents to fail. While most prior research assumes perfect answers from human interlocutors, we focus on a setting where the agent points out unintentional mistakes for the interlocutor to review, better reflecting real-world situations. In this paper, we show that human answer mistakes depend on question type and QA turn in the visual dialogue by analyzing a previously unused data collection of human mistakes. We demonstrate the effectiveness of those factors for the model's accuracy in a pointing-human-mistake task through experiments using a simple MLP model and a Visual Language Model.
Modeling Multiple User Interests using Hierarchical Knowledge for Conversational Recommender System
Mar 01, 2023



A conversational recommender system (CRS) is a practical application for item recommendation through natural language conversation. Such a system estimates user interests for appropriate personalized recommendations. Users sometimes have various interests in different categories or genres, but existing studies assume a unique user interest that can be covered by closely related items. In this work, we propose to model such multiple user interests in CRS. We investigated its effects in experiments using the ReDial dataset and found that the proposed method can recommend a wider variety of items than that of the baseline CR-Walker.
Community-Driven Comprehensive Scientific Paper Summarization: Insight from cvpaper.challenge
Mar 17, 2022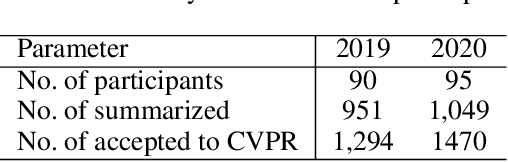


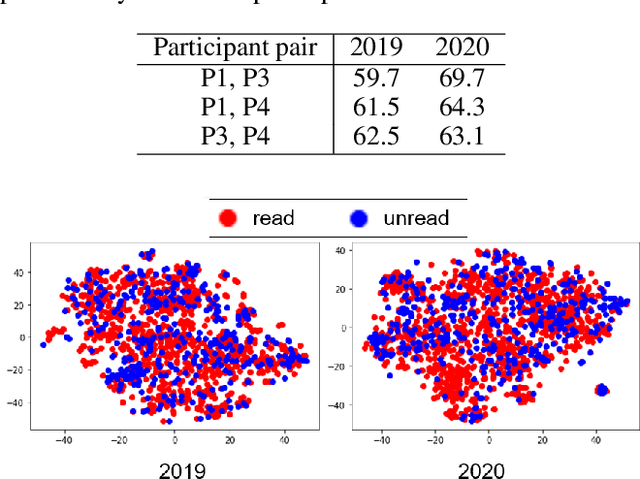
The present paper introduces a group activity involving writing summaries of conference proceedings by volunteer participants. The rapid increase in scientific papers is a heavy burden for researchers, especially non-native speakers, who need to survey scientific literature. To alleviate this problem, we organized a group of non-native English speakers to write summaries of papers presented at a computer vision conference to share the knowledge of the papers read by the group. We summarized a total of 2,000 papers presented at the Conference on Computer Vision and Pattern Recognition, a top-tier conference on computer vision, in 2019 and 2020. We quantitatively analyzed participants' selection regarding which papers they read among the many available papers. The experimental results suggest that we can summarize a wide range of papers without asking participants to read papers unrelated to their interests.
Interactive Image Manipulation with Natural Language Instruction Commands
Feb 23, 2018


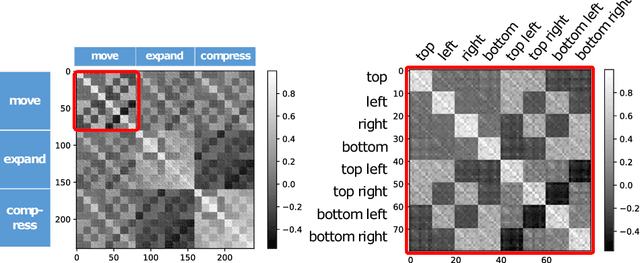
We propose an interactive image-manipulation system with natural language instruction, which can generate a target image from a source image and an instruction that describes the difference between the source and the target image. The system makes it possible to modify a generated image interactively and make natural language conditioned image generation more controllable. We construct a neural network that handles image vectors in latent space to transform the source vector to the target vector by using the vector of instruction. The experimental results indicate that the proposed framework successfully generates the target image by using a source image and an instruction on manipulation in our dataset.