 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo We Need Sound for Sound Source Localization?
Jul 11, 2020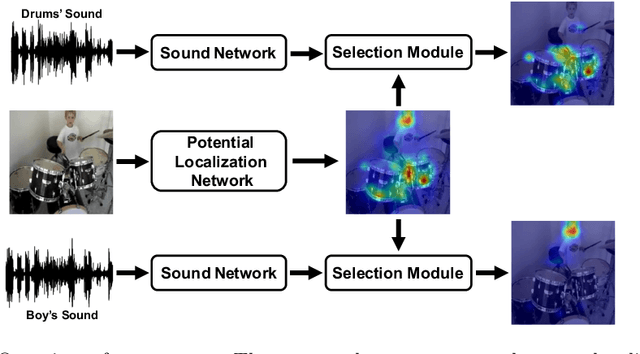
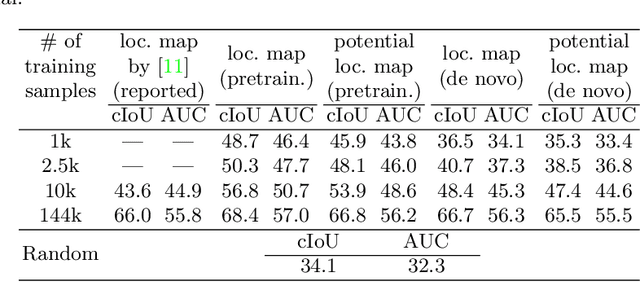


During the performance of sound source localization which uses both visual and aural information, it presently remains unclear how much either image or sound modalities contribute to the result, i.e. do we need both image and sound for sound source localization? To address this question, we develop an unsupervised learning system that solves sound source localization by decomposing this task into two steps: (i) "potential sound source localization", a step that localizes possible sound sources using only visual information (ii) "object selection", a step that identifies which objects are actually sounding using aural information. Our overall system achieves state-of-the-art performance in sound source localization, and more importantly, we find that despite the constraint on available information, the results of (i) achieve similar performance. From this observation and further experiments, we show that visual information is dominant in "sound" source localization when evaluated with the currently adopted benchmark dataset. Moreover, we show that the majority of sound-producing objects within the samples in this dataset can be inherently identified using only visual information, and thus that the dataset is inadequate to evaluate a system's capability to leverage aural information. As an alternative, we present an evaluation protocol that enforces both visual and aural information to be leveraged, and verify this property through several experiments.
PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization
May 15, 2019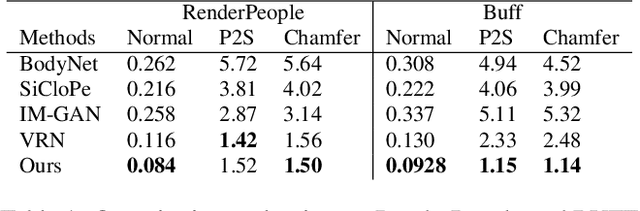
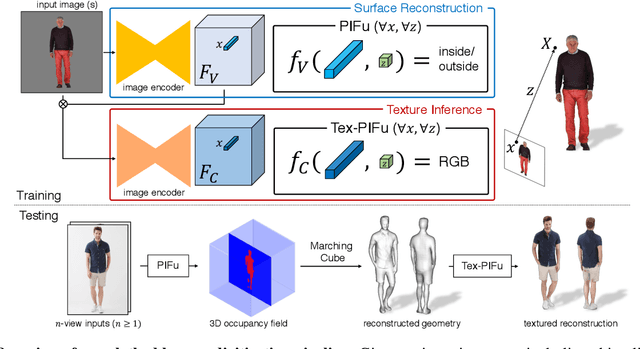


We introduce Pixel-aligned Implicit Function (PIFu), a highly effective implicit representation that locally aligns pixels of 2D images with the global context of their corresponding 3D object. Using PIFu, we propose an end-to-end deep learning method for digitizing highly detailed clothed humans that can infer both 3D surface and texture from a single image, and optionally, multiple input images. Highly intricate shapes, such as hairstyles, clothing, as well as their variations and deformations can be digitized in a unified way. Compared to existing representations used for 3D deep learning, PIFu can produce high-resolution surfaces including largely unseen regions such as the back of a person. In particular, it is memory efficient unlike the voxel representation, can handle arbitrary topology, and the resulting surface is spatially aligned with the input image. Furthermore, while previous techniques are designed to process either a single image or multiple views, PIFu extends naturally to arbitrary number of views. We demonstrate high-resolution and robust reconstructions on real world images from the DeepFashion dataset, which contains a variety of challenging clothing types. Our method achieves state-of-the-art performance on a public benchmark and outperforms the prior work for clothed human digitization from a single image.
SiCloPe: Silhouette-Based Clothed People
Dec 31, 2018



We introduce a new silhouette-based representation for modeling clothed human bodies using deep generative models. Our method can reconstruct a complete and textured 3D model of a person wearing clothes from a single input picture. Inspired by the visual hull algorithm, our implicit representation uses 2D silhouettes and 3D joints of a body pose to describe the immense shape complexity and variations of clothed people. Given a segmented 2D silhouette of a person and its inferred 3D joints from the input picture, we first synthesize consistent silhouettes from novel view points around the subject. The synthesized silhouettes, which are the most consistent with the input segmentation are fed into a deep visual hull algorithm for robust 3D shape prediction. We then infer the texture of the subject's back view using the frontal image and segmentation mask as input to a conditional generative adversarial network. Our experiments demonstrate that our silhouette-based model is an effective representation and the appearance of the back view can be predicted reliably using an image-to-image translation network. While classic methods based on parametric models often fail for single-view images of subjects with challenging clothing, our approach can still produce successful results, which are comparable to those obtained from multi-view input.
FSNet: An Identity-Aware Generative Model for Image-based Face Swapping
Nov 30, 2018
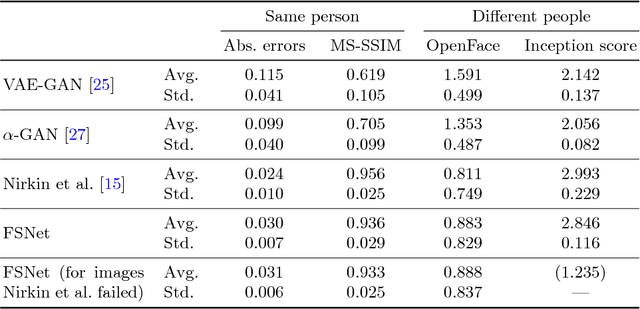
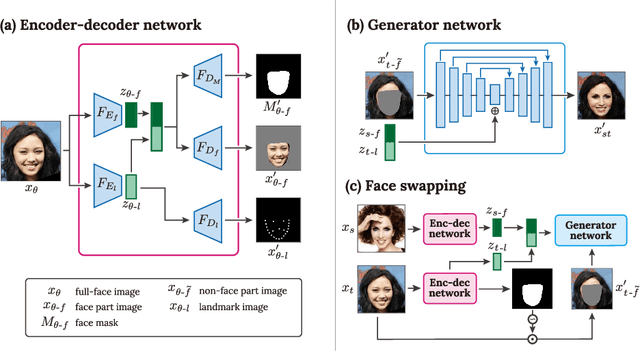

This paper presents FSNet, a deep generative model for image-based face swapping. Traditionally, face-swapping methods are based on three-dimensional morphable models (3DMMs), and facial textures are replaced between the estimated three-dimensional (3D) geometries in two images of different individuals. However, the estimation of 3D geometries along with different lighting conditions using 3DMMs is still a difficult task. We herein represent the face region with a latent variable that is assigned with the proposed deep neural network (DNN) instead of facial textures. The proposed DNN synthesizes a face-swapped image using the latent variable of the face region and another image of the non-face region. The proposed method is not required to fit to the 3DMM; additionally, it performs face swapping only by feeding two face images to the proposed network. Consequently, our DNN-based face swapping performs better than previous approaches for challenging inputs with different face orientations and lighting conditions. Through several experiments, we demonstrated that the proposed method performs face swapping in a more stable manner than the state-of-the-art method, and that its results are compatible with the method thereof.
Understanding Fake Faces
Sep 22, 2018


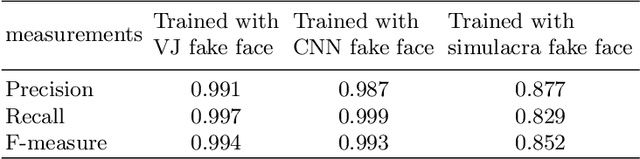
Face recognition research is one of the most active topics in computer vision (CV), and deep neural networks (DNN) are now filling the gap between human-level and computer-driven performance levels in face verification algorithms. However, although the performance gap appears to be narrowing in terms of accuracy-based expectations, a curious question has arisen; specifically, "Face understanding of AI is really close to that of human?" In the present study, in an effort to confirm the brain-driven concept, we conduct image-based detection, classification, and generation using an in-house created fake face database. This database has two configurations: (i) false positive face detections produced using both the Viola Jones (VJ) method and convolutional neural networks (CNN), and (ii) simulacra that have fundamental characteristics that resemble faces but are completely artificial. The results show a level of suggestive knowledge that indicates the continuing existence of a gap between the capabilities of recent vision-based face recognition algorithms and human-level performance. On a positive note, however, we have obtained knowledge that will advance the progress of face-understanding models.
RSGAN: Face Swapping and Editing using Face and Hair Representation in Latent Spaces
Apr 18, 2018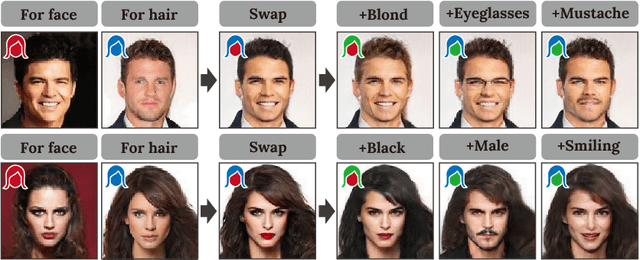


In this paper, we present an integrated system for automatically generating and editing face images through face swapping, attribute-based editing, and random face parts synthesis. The proposed system is based on a deep neural network that variationally learns the face and hair regions with large-scale face image datasets. Different from conventional variational methods, the proposed network represents the latent spaces individually for faces and hairs. We refer to the proposed network as region-separative generative adversarial network (RSGAN). The proposed network independently handles face and hair appearances in the latent spaces, and then, face swapping is achieved by replacing the latent-space representations of the faces, and reconstruct the entire face image with them. This approach in the latent space robustly performs face swapping even for images which the previous methods result in failure due to inappropriate fitting or the 3D morphable models. In addition, the proposed system can further edit face-swapped images with the same network by manipulating visual attributes or by composing them with randomly generated face or hair parts.