 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo We Need Sound for Sound Source Localization?
Paper and Code
Jul 11, 2020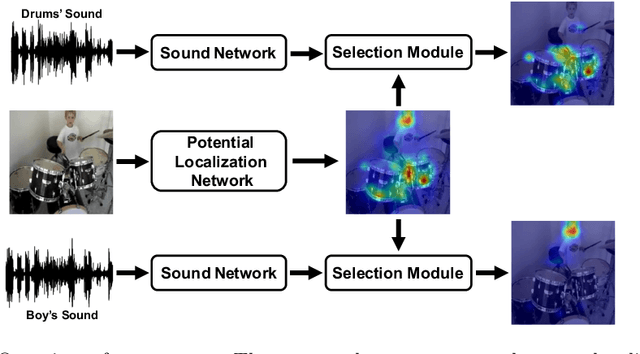
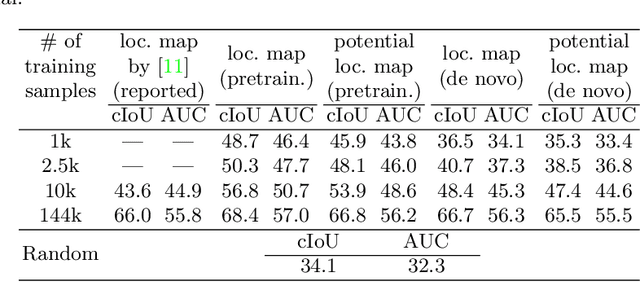


During the performance of sound source localization which uses both visual and aural information, it presently remains unclear how much either image or sound modalities contribute to the result, i.e. do we need both image and sound for sound source localization? To address this question, we develop an unsupervised learning system that solves sound source localization by decomposing this task into two steps: (i) "potential sound source localization", a step that localizes possible sound sources using only visual information (ii) "object selection", a step that identifies which objects are actually sounding using aural information. Our overall system achieves state-of-the-art performance in sound source localization, and more importantly, we find that despite the constraint on available information, the results of (i) achieve similar performance. From this observation and further experiments, we show that visual information is dominant in "sound" source localization when evaluated with the currently adopted benchmark dataset. Moreover, we show that the majority of sound-producing objects within the samples in this dataset can be inherently identified using only visual information, and thus that the dataset is inadequate to evaluate a system's capability to leverage aural information. As an alternative, we present an evaluation protocol that enforces both visual and aural information to be leveraged, and verify this property through several experiments.