 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Sound of Bounding-Boxes
Mar 30, 2022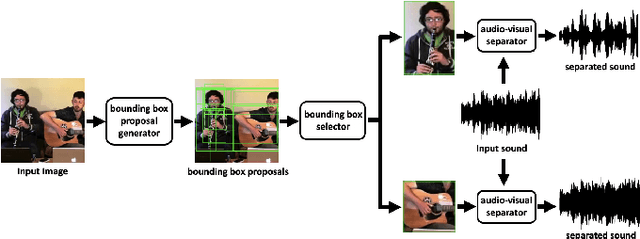
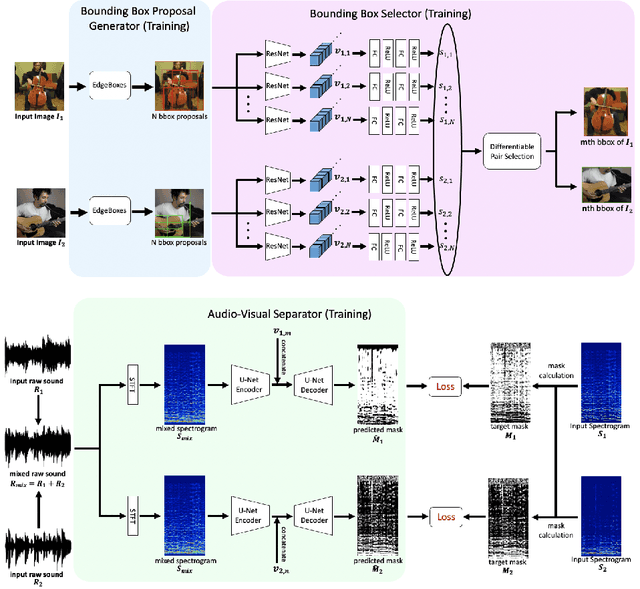
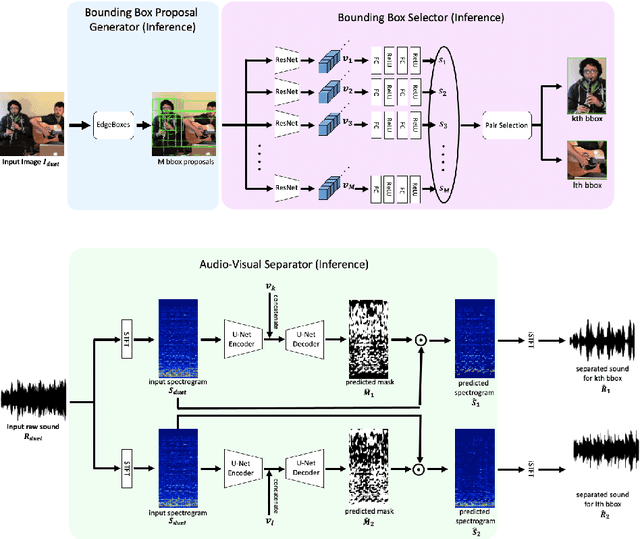

In the task of audio-visual sound source separation, which leverages visual information for sound source separation, identifying objects in an image is a crucial step prior to separating the sound source. However, existing methods that assign sound on detected bounding boxes suffer from a problem that their approach heavily relies on pre-trained object detectors. Specifically, when using these existing methods, it is required to predetermine all the possible categories of objects that can produce sound and use an object detector applicable to all such categories. To tackle this problem, we propose a fully unsupervised method that learns to detect objects in an image and separate sound source simultaneously. As our method does not rely on any pre-trained detector, our method is applicable to arbitrary categories without any additional annotation. Furthermore, although being fully unsupervised, we found that our method performs comparably in separation accuracy.
LSTM-SAKT: LSTM-Encoded SAKT-like Transformer for Knowledge Tracing
Feb 10, 2021
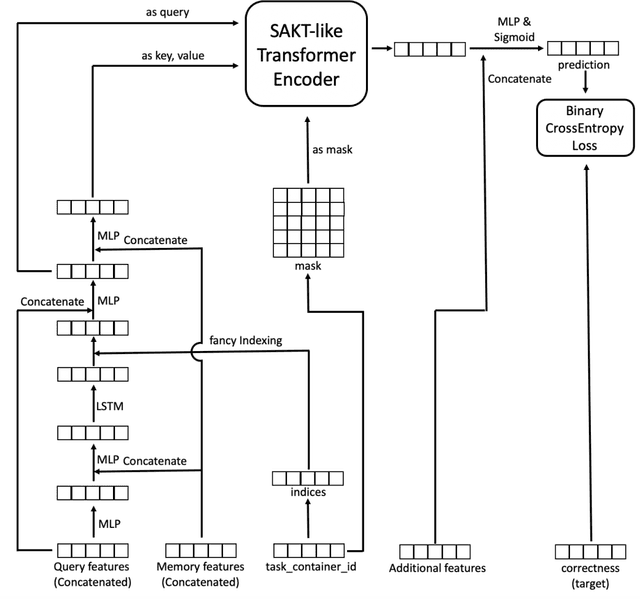

This paper introduces the 2nd place solution for the Riiid! Answer Correctness Prediction in Kaggle, the world's largest data science competition website. This competition was held from October 16, 2020, to January 7, 2021, with 3395 teams and 4387 competitors. The main insights and contributions of this paper are as follows. (i) We pointed out existing Transformer-based models are suffering from a problem that the information which their query/key/value can contain is limited. To solve this problem, we proposed a method that uses LSTM to obtain query/key/value and verified its effectiveness. (ii) We pointed out 'inter-container' leakage problem, which happens in datasets where questions are sometimes served together. To solve this problem, we showed special indexing/masking techniques that are useful when using RNN-variants and Transformer. (iii) We found additional hand-crafted features are effective to overcome the limits of Transformer, which can never consider the samples older than the sequence length.
Do We Need Sound for Sound Source Localization?
Jul 11, 2020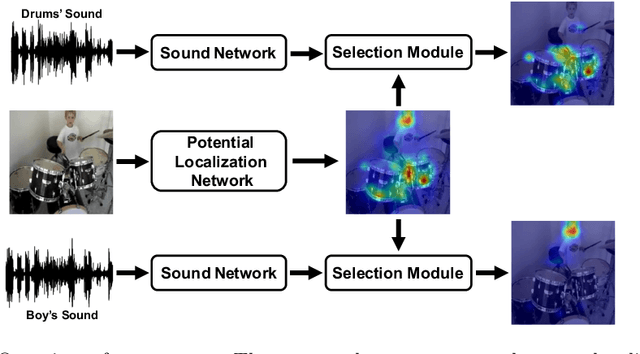
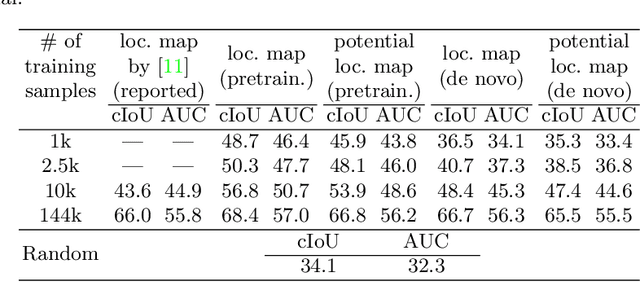


During the performance of sound source localization which uses both visual and aural information, it presently remains unclear how much either image or sound modalities contribute to the result, i.e. do we need both image and sound for sound source localization? To address this question, we develop an unsupervised learning system that solves sound source localization by decomposing this task into two steps: (i) "potential sound source localization", a step that localizes possible sound sources using only visual information (ii) "object selection", a step that identifies which objects are actually sounding using aural information. Our overall system achieves state-of-the-art performance in sound source localization, and more importantly, we find that despite the constraint on available information, the results of (i) achieve similar performance. From this observation and further experiments, we show that visual information is dominant in "sound" source localization when evaluated with the currently adopted benchmark dataset. Moreover, we show that the majority of sound-producing objects within the samples in this dataset can be inherently identified using only visual information, and thus that the dataset is inadequate to evaluate a system's capability to leverage aural information. As an alternative, we present an evaluation protocol that enforces both visual and aural information to be leveraged, and verify this property through several experiments.