 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonte Carlo Path Tracing and Statistical Event Detection for Event Camera Simulation
Aug 15, 2024

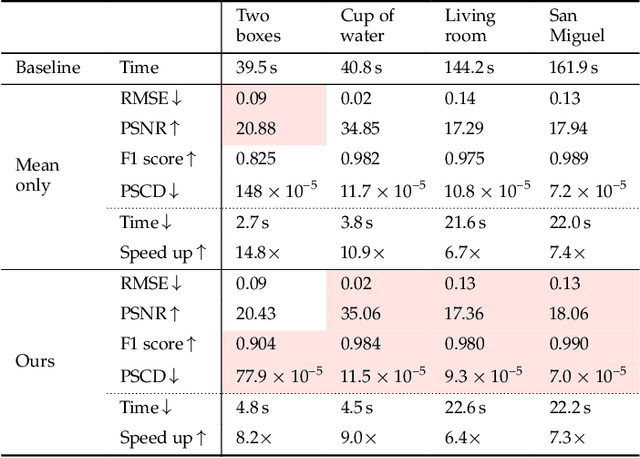
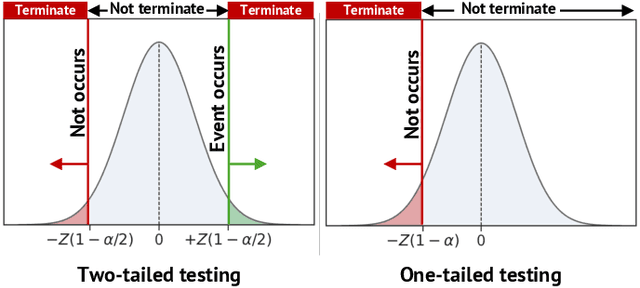
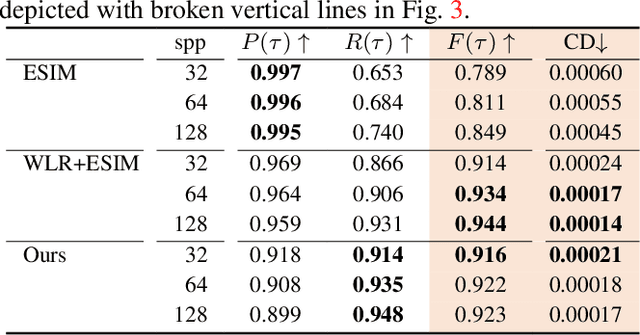
This paper presents a novel event camera simulation system fully based on physically based Monte Carlo path tracing with adaptive path sampling. The adaptive sampling performed in the proposed method is based on a statistical technique, hypothesis testing for the hypothesis whether the difference of logarithmic luminances at two distant periods is significantly larger than a predefined event threshold. To this end, our rendering system collects logarithmic luminances rather than raw luminance in contrast to the conventional rendering system imitating conventional RGB cameras. Then, based on the central limit theorem, we reasonably assume that the distribution of the population mean of logarithmic luminance can be modeled as a normal distribution, allowing us to model the distribution of the difference of logarithmic luminance as a normal distribution. Then, using Student's t-test, we can test the hypothesis and determine whether to discard the null hypothesis for event non-occurrence. When we sample a sufficiently large number of path samples to satisfy the central limit theorem and obtain a clean set of events, our method achieves significant speed up compared to a simple approach of sampling paths uniformly at every pixel. To our knowledge, we are the first to simulate the behavior of event cameras in a physically accurate manner using an adaptive sampling technique in Monte Carlo path tracing, and we believe this study will contribute to the development of computer vision applications using event cameras.
Learning Self-Prior for Mesh Inpainting Using Self-Supervised Graph Convolutional Networks
May 01, 2023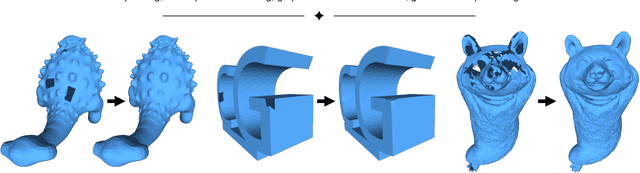
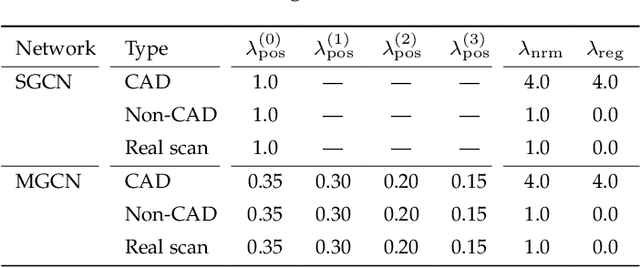
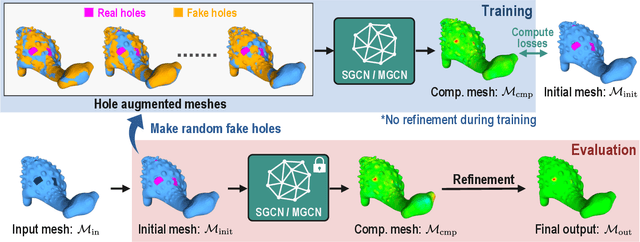
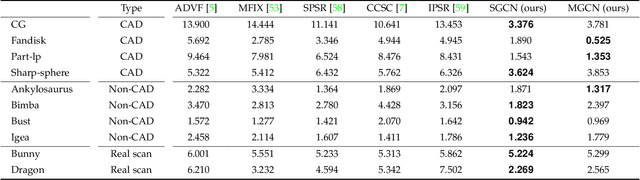
This study presents a self-prior-based mesh inpainting framework that requires only an incomplete mesh as input, without the need for any training datasets. Additionally, our method maintains the polygonal mesh format throughout the inpainting process without converting the shape format to an intermediate, such as a voxel grid, a point cloud, or an implicit function, which are typically considered easier for deep neural networks to process. To achieve this goal, we introduce two graph convolutional networks (GCNs): single-resolution GCN (SGCN) and multi-resolution GCN (MGCN), both trained in a self-supervised manner. Our approach refines a watertight mesh obtained from the initial hole filling to generate a completed output mesh. Specifically, we train the GCNs to deform an oversmoothed version of the input mesh into the expected completed shape. To supervise the GCNs for accurate vertex displacements, despite the unknown correct displacements at real holes, we utilize multiple sets of meshes with several connected regions marked as fake holes. The correct displacements are known for vertices in these fake holes, enabling network training with loss functions that assess the accuracy of displacement vectors estimated by the GCNs. We demonstrate that our method outperforms traditional dataset-independent approaches and exhibits greater robustness compared to other deep-learning-based methods for shapes that less frequently appear in shape datasets.
Event-based Camera Simulation using Monte Carlo Path Tracing with Adaptive Denoising
Mar 05, 2023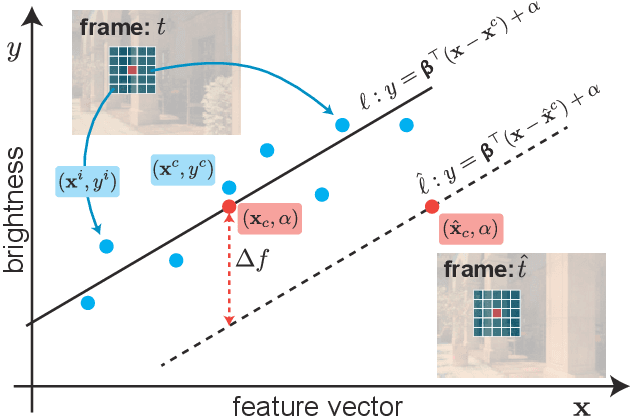


This paper proposes an algorithm for obtaining an event-based video from a noisy input video given by physics-based Monte Carlo path tracing of synthetic 3D scenes. Since the dynamic vision sensor (DVS) detects temporal brightness changes as events, the problem of efficiently rendering event-based video boils down to detecting the changes from noisy brightness values. To this end, we extend a denoising method based on a weighted local regression (WLR) to detect the brightness changes rather than applying denoising to each video frame. Specifically, we regress a WLR model only on frames where an event is detected, which significantly reduces the computational cost of the regression. We show that our efficient method is robust to noisy video frames obtained from a few path-traced samples and performs comparably to or even better than an approach that denoises every frame.
Deep Point-to-Plane Registration by Efficient Backpropagation for Error Minimizing Function
Jul 14, 2022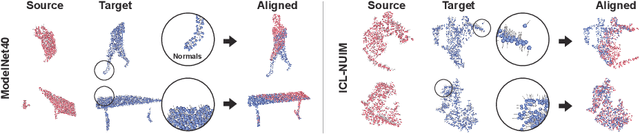
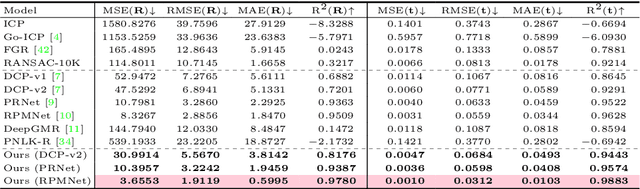

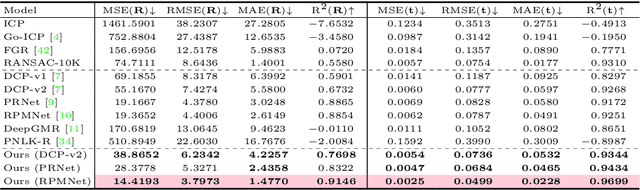
Traditional algorithms of point set registration minimizing point-to-plane distances often achieve a better estimation of rigid transformation than those minimizing point-to-point distances. Nevertheless, recent deep-learning-based methods minimize the point-to-point distances. In contrast to these methods, this paper proposes the first deep-learning-based approach to point-to-plane registration. A challenging part of this problem is that a typical solution for point-to-plane registration requires an iterative process of accumulating small transformations obtained by minimizing a linearized energy function. The iteration significantly increases the size of the computation graph needed for backpropagation and can slow down both forward and backward network evaluations. To solve this problem, we consider the estimated rigid transformation as a function of input point clouds and derive its analytic gradients using the implicit function theorem. The analytic gradient that we introduce is independent of how the error minimizing function (i.e., the rigid transformation) is obtained, thus allowing us to calculate both the rigid transformation and its gradient efficiently. We implement the proposed point-to-plane registration module over several previous methods that minimize point-to-point distances and demonstrate that the extensions outperform the base methods even with point clouds with noise and low-quality point normals estimated with local point distributions.
Deep Mesh Prior: Unsupervised Mesh Restoration using Graph Convolutional Networks
Jul 02, 2021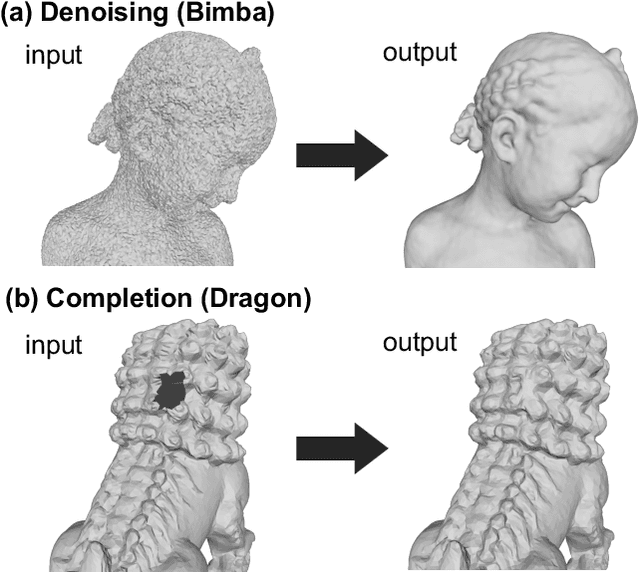
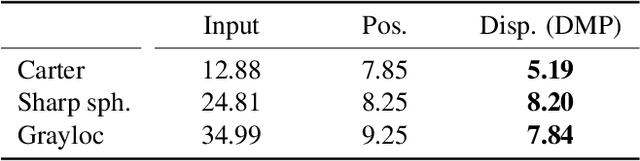
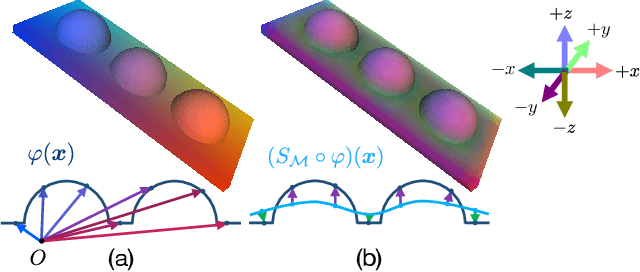

This paper addresses mesh restoration problems, i.e., denoising and completion, by learning self-similarity in an unsupervised manner. For this purpose, the proposed method, which we refer to as Deep Mesh Prior, uses a graph convolutional network on meshes to learn the self-similarity. The network takes a single incomplete mesh as input data and directly outputs the reconstructed mesh without being trained using large-scale datasets. Our method does not use any intermediate representations such as an implicit field because the whole process works on a mesh. We demonstrate that our unsupervised method performs equally well or even better than the state-of-the-art methods using large-scale datasets.
FSNet: An Identity-Aware Generative Model for Image-based Face Swapping
Nov 30, 2018
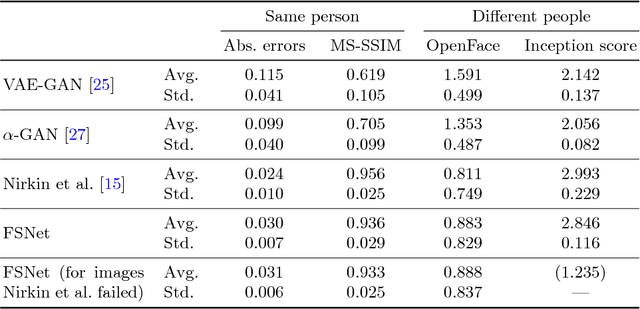
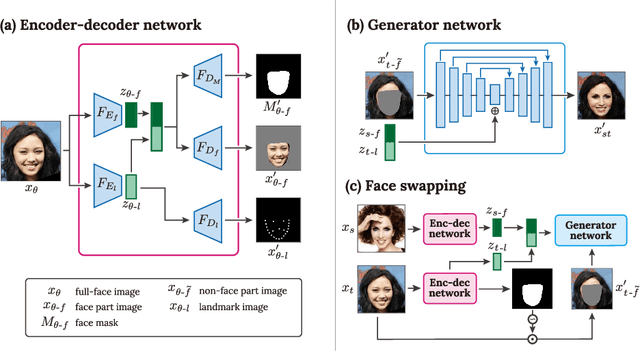

This paper presents FSNet, a deep generative model for image-based face swapping. Traditionally, face-swapping methods are based on three-dimensional morphable models (3DMMs), and facial textures are replaced between the estimated three-dimensional (3D) geometries in two images of different individuals. However, the estimation of 3D geometries along with different lighting conditions using 3DMMs is still a difficult task. We herein represent the face region with a latent variable that is assigned with the proposed deep neural network (DNN) instead of facial textures. The proposed DNN synthesizes a face-swapped image using the latent variable of the face region and another image of the non-face region. The proposed method is not required to fit to the 3DMM; additionally, it performs face swapping only by feeding two face images to the proposed network. Consequently, our DNN-based face swapping performs better than previous approaches for challenging inputs with different face orientations and lighting conditions. Through several experiments, we demonstrated that the proposed method performs face swapping in a more stable manner than the state-of-the-art method, and that its results are compatible with the method thereof.
RSGAN: Face Swapping and Editing using Face and Hair Representation in Latent Spaces
Apr 18, 2018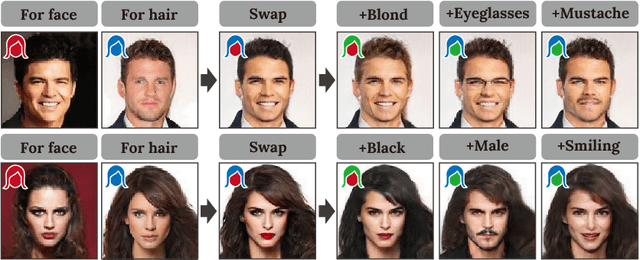


In this paper, we present an integrated system for automatically generating and editing face images through face swapping, attribute-based editing, and random face parts synthesis. The proposed system is based on a deep neural network that variationally learns the face and hair regions with large-scale face image datasets. Different from conventional variational methods, the proposed network represents the latent spaces individually for faces and hairs. We refer to the proposed network as region-separative generative adversarial network (RSGAN). The proposed network independently handles face and hair appearances in the latent spaces, and then, face swapping is achieved by replacing the latent-space representations of the faces, and reconstruct the entire face image with them. This approach in the latent space robustly performs face swapping even for images which the previous methods result in failure due to inappropriate fitting or the 3D morphable models. In addition, the proposed system can further edit face-swapped images with the same network by manipulating visual attributes or by composing them with randomly generated face or hair parts.