 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRényi Attention Entropy for Patch Pruning
Apr 04, 2026Transformers are strong baselines in both vision and language because self-attention captures long-range dependencies across tokens. However, the cost of self-attention grows quadratically with the number of tokens. Patch pruning mitigates this cost by estimating per-patch importance and removing redundant patches. To identify informative patches for pruning, we introduce a criterion based on the Shannon entropy of the attention distribution. Low-entropy patches, which receive selective and concentrated attention, are kept as important, while high-entropy patches with attention spread across many locations are treated as redundant. We also extend the criterion from Shannon to Rényi entropy, which emphasizes sharp attention peaks and supports pruning strategies that adapt to task needs and computational limits. In experiments on fine-grained image recognition, where patch selection is critical, our method reduced computation while preserving accuracy. Moreover, adjusting the pruning policy through the Rényi entropy measure yields further gains and improves the trade-off between accuracy and computation.
Flatness-aware Curriculum Learning via Adversarial Difficulty
Aug 26, 2025Neural networks trained by empirical risk minimization often suffer from overfitting, especially to specific samples or domains, which leads to poor generalization. Curriculum Learning (CL) addresses this issue by selecting training samples based on the difficulty. From the optimization perspective, methods such as Sharpness-Aware Minimization (SAM) improve robustness and generalization by seeking flat minima. However, combining CL with SAM is not straightforward. In flat regions, both the loss values and the gradient norms tend to become uniformly small, which makes it difficult to evaluate sample difficulty and design an effective curriculum. To overcome this problem, we propose the Adversarial Difficulty Measure (ADM), which quantifies adversarial vulnerability by leveraging the robustness properties of models trained toward flat minima. Unlike loss- or gradient-based measures, which become ineffective as training progresses into flatter regions, ADM remains informative by measuring the normalized loss gap between original and adversarial examples. We incorporate ADM into CL-based training with SAM to dynamically assess sample difficulty. We evaluated our approach on image classification tasks, fine-grained recognition, and domain generalization. The results demonstrate that our method preserves the strengths of both CL and SAM while outperforming existing curriculum-based and flatness-aware training strategies.
Class-wise Flooding Regularization for Imbalanced Image Classification
Aug 26, 2025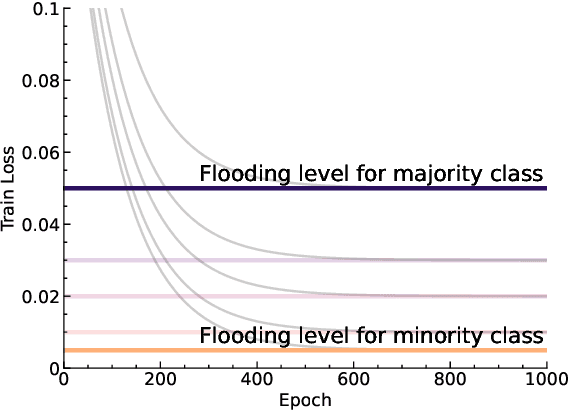

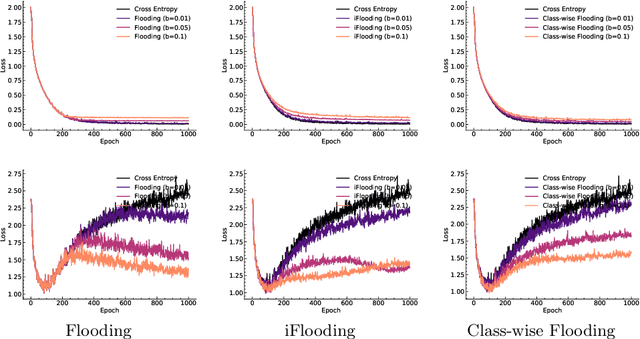

The purpose of training neural networks is to achieve high generalization performance on unseen inputs. However, when trained on imbalanced datasets, a model's prediction tends to favor majority classes over minority classes, leading to significant degradation in the recognition performance of minority classes. To address this issue, we propose class-wise flooding regularization, an extension of flooding regularization applied at the class level. Flooding is a regularization technique that mitigates overfitting by preventing the training loss from falling below a predefined threshold, known as the flooding level, thereby discouraging memorization. Our proposed method assigns a class-specific flooding level based on class frequencies. By doing so, it suppresses overfitting in majority classes while allowing sufficient learning for minority classes. We validate our approach on imbalanced image classification. Compared to conventional flooding regularizations, our method improves the classification performance of minority classes and achieves better overall generalization.
Vision-Language In-Context Learning Driven Few-Shot Visual Inspection Model
Feb 13, 2025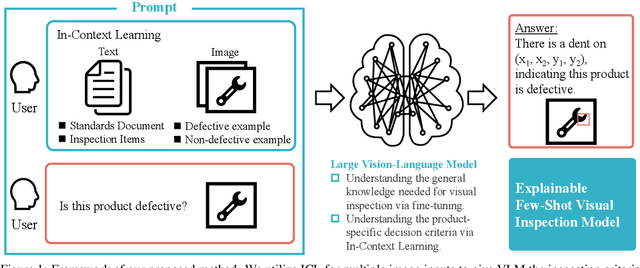
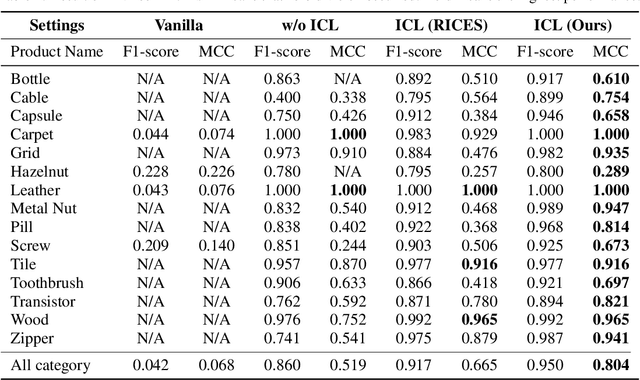
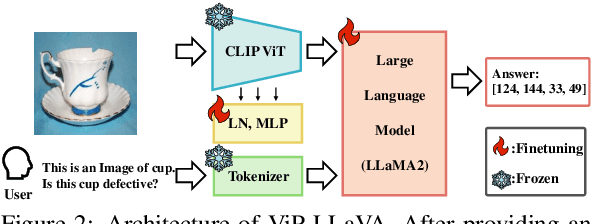
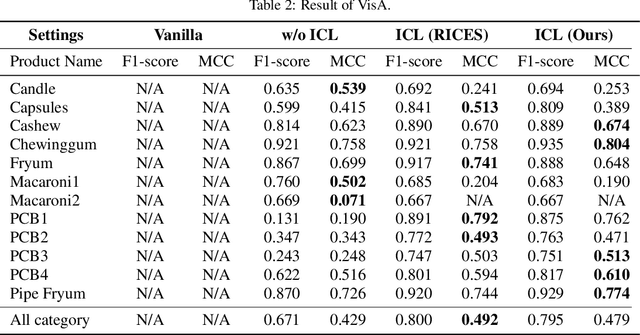
We propose general visual inspection model using Vision-Language Model~(VLM) with few-shot images of non-defective or defective products, along with explanatory texts that serve as inspection criteria. Although existing VLM exhibit high performance across various tasks, they are not trained on specific tasks such as visual inspection. Thus, we construct a dataset consisting of diverse images of non-defective and defective products collected from the web, along with unified formatted output text, and fine-tune VLM. For new products, our method employs In-Context Learning, which allows the model to perform inspections with an example of non-defective or defective image and the corresponding explanatory texts with visual prompts. This approach eliminates the need to collect a large number of training samples and re-train the model for each product. The experimental results show that our method achieves high performance, with MCC of 0.804 and F1-score of 0.950 on MVTec AD in a one-shot manner. Our code is available at~https://github.com/ia-gu/Vision-Language-In-Context-Learning-Driven-Few-Shot-Visual-Inspection-Model.
Taylor Outlier Exposure
Dec 10, 2024



Out-of-distribution (OOD) detection is the task of identifying data sampled from distributions that were not used during training. This task is essential for reliable machine learning and a better understanding of their generalization capabilities. Among OOD detection methods, Outlier Exposure (OE) significantly enhances OOD detection performance and generalization ability by exposing auxiliary OOD data to the model. However, constructing clean auxiliary OOD datasets, uncontaminated by in-distribution (ID) samples, is essential for OE; generally, a noisy OOD dataset contaminated with ID samples negatively impacts OE training dynamics and final detection performance. Furthermore, as dataset scale increases, constructing clean OOD data becomes increasingly challenging and costly. To address these challenges, we propose Taylor Outlier Exposure (TaylorOE), an OE-based approach with regularization that allows training on noisy OOD datasets contaminated with ID samples. Specifically, we represent the OE regularization term as a polynomial function via a Taylor expansion, allowing us to control the regularization strength for ID data in the auxiliary OOD dataset by adjusting the order of Taylor expansion. In our experiments on the OOD detection task with clean and noisy OOD datasets, we demonstrate that the proposed method consistently outperforms conventional methods and analyze our regularization term to show its effectiveness. Our implementation code of TaylorOE is available at \url{https://github.com/fukuchan41/TaylorOE}.
Classification of Carotid Plaque with Jellyfish Sign Through Convolutional and Recurrent Neural Networks Utilizing Plaque Surface Edges
Jun 27, 2024
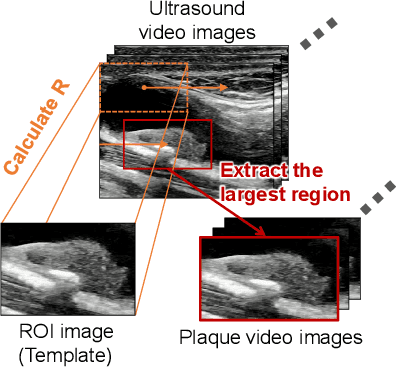


In carotid arteries, plaque can develop as localized elevated lesions. The Jellyfish sign, marked by fluctuating plaque surfaces with blood flow pulsation, is a dynamic characteristic of these plaques that has recently attracted attention. Detecting this sign is vital, as it is often associated with cerebral infarction. This paper proposes an ultrasound video-based classification method for the Jellyfish sign, using deep neural networks. The proposed method first preprocesses carotid ultrasound videos to separate the movement of the vascular wall from plaque movements. These preprocessed videos are then combined with plaque surface information and fed into a deep learning model comprising convolutional and recurrent neural networks, enabling the efficient classification of the Jellyfish sign. The proposed method was verified using ultrasound video images from 200 patients. Ablation studies demonstrated the effectiveness of each component of the proposed method.
Neural Density-Distance Fields
Jul 29, 2022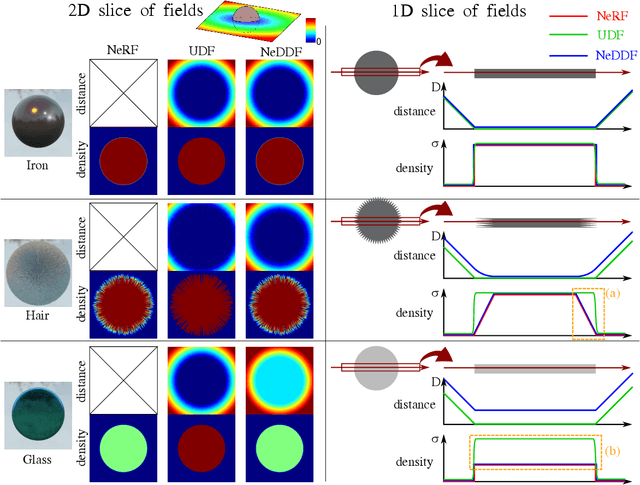

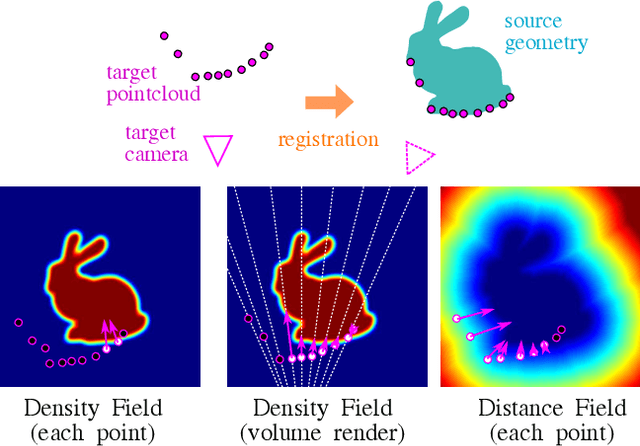
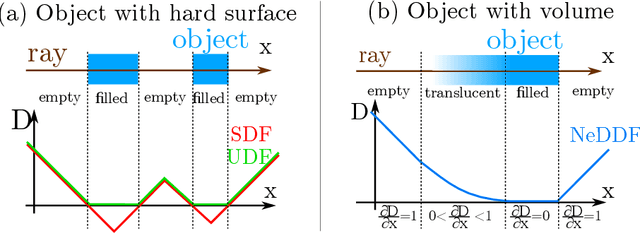
The success of neural fields for 3D vision tasks is now indisputable. Following this trend, several methods aiming for visual localization (e.g., SLAM) have been proposed to estimate distance or density fields using neural fields. However, it is difficult to achieve high localization performance by only density fields-based methods such as Neural Radiance Field (NeRF) since they do not provide density gradient in most empty regions. On the other hand, distance field-based methods such as Neural Implicit Surface (NeuS) have limitations in objects' surface shapes. This paper proposes Neural Density-Distance Field (NeDDF), a novel 3D representation that reciprocally constrains the distance and density fields. We extend distance field formulation to shapes with no explicit boundary surface, such as fur or smoke, which enable explicit conversion from distance field to density field. Consistent distance and density fields realized by explicit conversion enable both robustness to initial values and high-quality registration. Furthermore, the consistency between fields allows fast convergence from sparse point clouds. Experiments show that NeDDF can achieve high localization performance while providing comparable results to NeRF on novel view synthesis. The code is available at https://github.com/ueda0319/neddf.
Hierarchical Pyramid Representations for Semantic Segmentation
Apr 05, 2021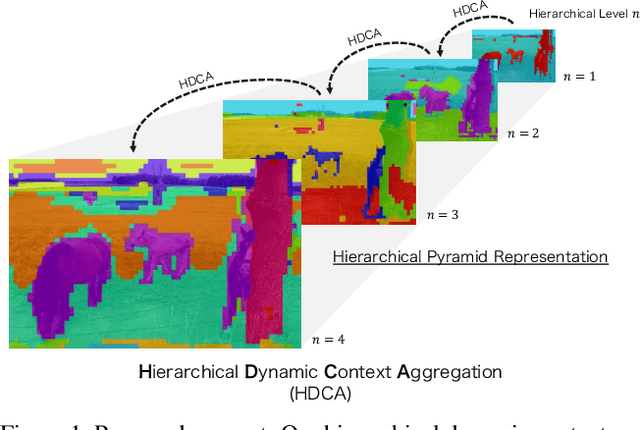
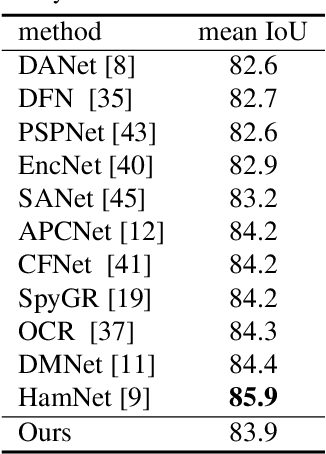
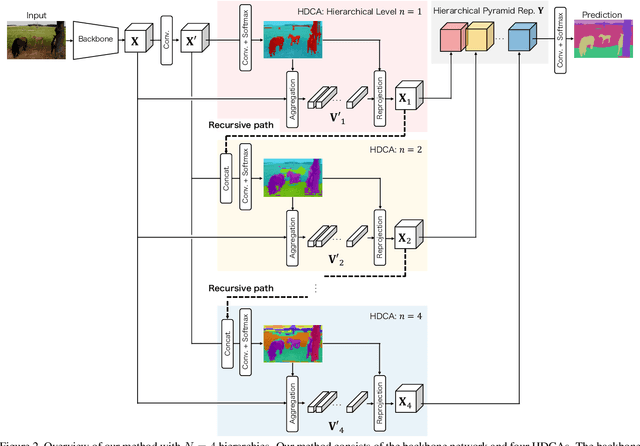
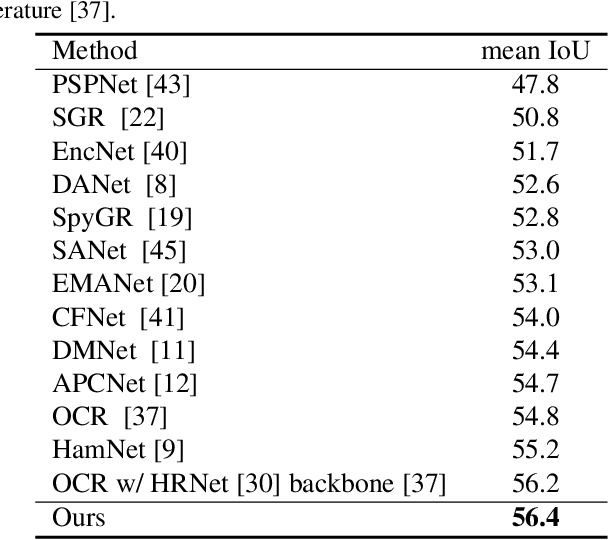
Understanding the context of complex and cluttered scenes is a challenging problem for semantic segmentation. However, it is difficult to model the context without prior and additional supervision because the scene's factors, such as the scale, shape, and appearance of objects, vary considerably in these scenes. To solve this, we propose to learn the structures of objects and the hierarchy among objects because context is based on these intrinsic properties. In this study, we design novel hierarchical, contextual, and multiscale pyramidal representations to capture the properties from an input image. Our key idea is the recursive segmentation in different hierarchical regions based on a predefined number of regions and the aggregation of the context in these regions. The aggregated contexts are used to predict the contextual relationship between the regions and partition the regions in the following hierarchical level. Finally, by constructing the pyramid representations from the recursively aggregated context, multiscale and hierarchical properties are attained. In the experiments, we confirmed that our proposed method achieves state-of-the-art performance in PASCAL Context.