 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection of Medial Epicondyle Avulsion in Elbow Ultrasound Images via Bone Structure Reconstruction
Jul 27, 2025This study proposes a reconstruction-based framework for detecting medial epicondyle avulsion in elbow ultrasound images, trained exclusively on normal cases. Medial epicondyle avulsion, commonly observed in baseball players, involves bone detachment and deformity, often appearing as discontinuities in bone contour. Therefore, learning the structure and continuity of normal bone is essential for detecting such abnormalities. To achieve this, we propose a masked autoencoder-based, structure-aware reconstruction framework that learns the continuity of normal bone structures. Even in the presence of avulsion, the model attempts to reconstruct the normal structure, resulting in large reconstruction errors at the avulsion site. For evaluation, we constructed a novel dataset comprising normal and avulsion ultrasound images from 16 baseball players, with pixel-level annotations under orthopedic supervision. Our method outperformed existing approaches, achieving a pixel-wise AUC of 0.965 and an image-wise AUC of 0.967. The dataset is publicly available at: https://github.com/Akahori000/Ultrasound-Medial-Epicondyle-Avulsion-Dataset.
Measurement of Medial Elbow Joint Space using Landmark Detection
Dec 17, 2024Ultrasound imaging of the medial elbow is crucial for the early identification of Ulnar Collateral Ligament (UCL) injuries. Specifically, measuring the elbow joint space in ultrasound images is used to assess the valgus instability of elbow. To automate this measurement, a precisely annotated dataset is necessary; however, no publicly available dataset has been proposed thus far. This study introduces a novel ultrasound medial elbow dataset for measuring joint space to diagnose Ulnar Collateral Ligament (UCL) injuries. The dataset comprises 4,201 medial elbow ultrasound images from 22 subjects, with landmark annotations on the humerus and ulna. The annotations are made precisely by the authors under the supervision of three orthopedic surgeons. We evaluated joint space measurement methods using our proposed dataset with several landmark detection approaches, including ViTPose, HRNet, PCT, YOLOv8, and U-Net. In addition, we propose using Shape Subspace (SS) for landmark refinement in heatmap-based landmark detection. The results show that the mean Euclidean distance error of joint space is 0.116 mm when using HRNet. Furthermore, the SS landmark refinement improves the mean absolute error of landmark positions by 0.010 mm with HRNet and by 0.103 mm with ViTPose on average. These highlight the potential for high-precision, real-time diagnosis of UCL injuries and associated risks, which could be leveraged in large-scale screening. Lastly, we demonstrate point-based segmentation of the humerus and ulna using the detected landmarks as input. The dataset will be made publicly available upon acceptance of this paper at: https://github.com/Akahori000/Ultrasound-Medial-Elbow-Dataset.
M3D: Dual-Stream Selective State Spaces and Depth-Driven Framework for High-Fidelity Single-View 3D Reconstruction
Nov 20, 2024The precise reconstruction of 3D objects from a single RGB image in complex scenes presents a critical challenge in virtual reality, autonomous driving, and robotics. Existing neural implicit 3D representation methods face significant difficulties in balancing the extraction of global and local features, particularly in diverse and complex environments, leading to insufficient reconstruction precision and quality. We propose M3D, a novel single-view 3D reconstruction framework, to tackle these challenges. This framework adopts a dual-stream feature extraction strategy based on Selective State Spaces to effectively balance the extraction of global and local features, thereby improving scene comprehension and representation precision. Additionally, a parallel branch extracts depth information, effectively integrating visual and geometric features to enhance reconstruction quality and preserve intricate details. Experimental results indicate that the fusion of multi-scale features with depth information via the dual-branch feature extraction significantly boosts geometric consistency and fidelity, achieving state-of-the-art reconstruction performance.
RayEmb: Arbitrary Landmark Detection in X-Ray Images Using Ray Embedding Subspace
Oct 10, 2024Intra-operative 2D-3D registration of X-ray images with pre-operatively acquired CT scans is a crucial procedure in orthopedic surgeries. Anatomical landmarks pre-annotated in the CT volume can be detected in X-ray images to establish 2D-3D correspondences, which are then utilized for registration. However, registration often fails in certain view angles due to poor landmark visibility. We propose a novel method to address this issue by detecting arbitrary landmark points in X-ray images. Our approach represents 3D points as distinct subspaces, formed by feature vectors (referred to as ray embeddings) corresponding to intersecting rays. Establishing 2D-3D correspondences then becomes a task of finding ray embeddings that are close to a given subspace, essentially performing an intersection test. Unlike conventional methods for landmark estimation, our approach eliminates the need for manually annotating fixed landmarks. We trained our model using the synthetic images generated from CTPelvic1K CLINIC dataset, which contains 103 CT volumes, and evaluated it on the DeepFluoro dataset, comprising real X-ray images. Experimental results demonstrate the superiority of our method over conventional methods. The code is available at https://github.com/Pragyanstha/rayemb.
OmniVoxel: A Fast and Precise Reconstruction Method of Omnidirectional Neural Radiance Field
Aug 12, 2022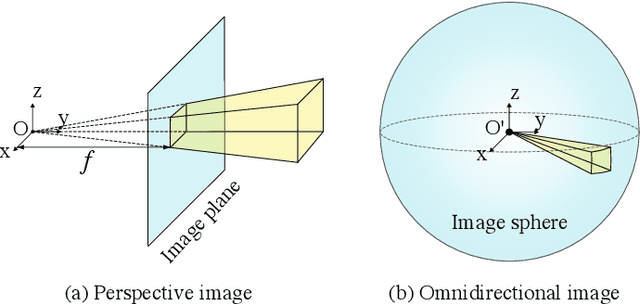
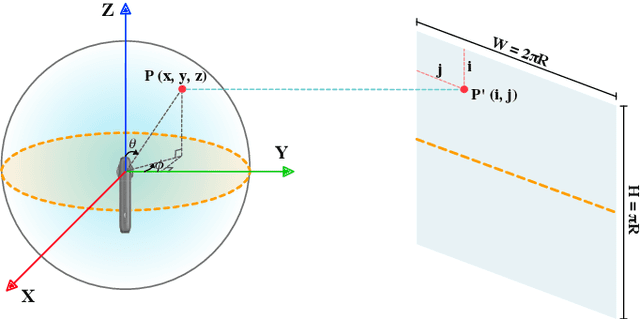

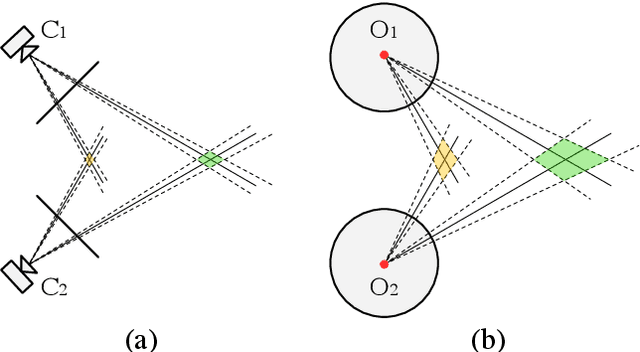
This paper proposes a method to reconstruct the neural radiance field with equirectangular omnidirectional images. Implicit neural scene representation with a radiance field can reconstruct the 3D shape of a scene continuously within a limited spatial area. However, training a fully implicit representation on commercial PC hardware requires a lot of time and computing resources (15 $\sim$ 20 hours per scene). Therefore, we propose a method to accelerate this process significantly (20 $\sim$ 40 minutes per scene). Instead of using a fully implicit representation of rays for radiance field reconstruction, we adopt feature voxels that contain density and color features in tensors. Considering omnidirectional equirectangular input and the camera layout, we use spherical voxelization for representation instead of cubic representation. Our voxelization method could balance the reconstruction quality of the inner scene and outer scene. In addition, we adopt the axis-aligned positional encoding method on the color features to increase the total image quality. Our method achieves satisfying empirical performance on synthetic datasets with random camera poses. Moreover, we test our method with real scenes which contain complex geometries and also achieve state-of-the-art performance. Our code and complete dataset will be released at the same time as the paper publication.
Neural Density-Distance Fields
Jul 29, 2022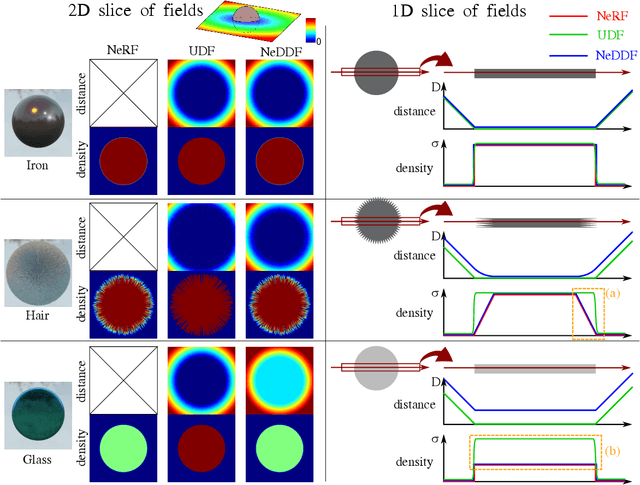

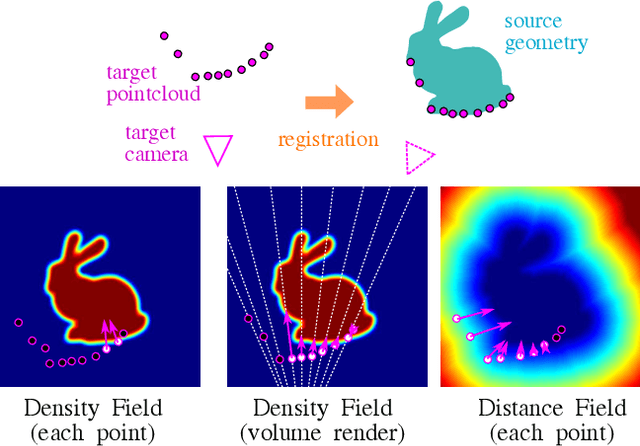
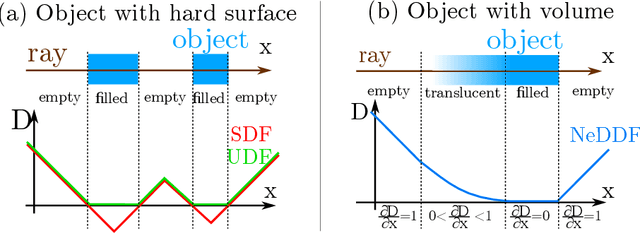
The success of neural fields for 3D vision tasks is now indisputable. Following this trend, several methods aiming for visual localization (e.g., SLAM) have been proposed to estimate distance or density fields using neural fields. However, it is difficult to achieve high localization performance by only density fields-based methods such as Neural Radiance Field (NeRF) since they do not provide density gradient in most empty regions. On the other hand, distance field-based methods such as Neural Implicit Surface (NeuS) have limitations in objects' surface shapes. This paper proposes Neural Density-Distance Field (NeDDF), a novel 3D representation that reciprocally constrains the distance and density fields. We extend distance field formulation to shapes with no explicit boundary surface, such as fur or smoke, which enable explicit conversion from distance field to density field. Consistent distance and density fields realized by explicit conversion enable both robustness to initial values and high-quality registration. Furthermore, the consistency between fields allows fast convergence from sparse point clouds. Experiments show that NeDDF can achieve high localization performance while providing comparable results to NeRF on novel view synthesis. The code is available at https://github.com/ueda0319/neddf.