 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTANGO: Co-Speech Gesture Video Reenactment with Hierarchical Audio Motion Embedding and Diffusion Interpolation
Oct 05, 2024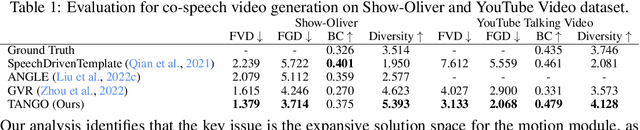


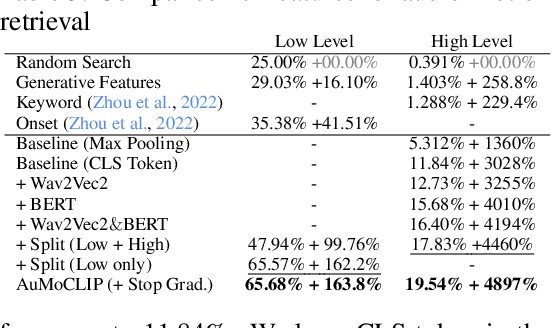
We present TANGO, a framework for generating co-speech body-gesture videos. Given a few-minute, single-speaker reference video and target speech audio, TANGO produces high-fidelity videos with synchronized body gestures. TANGO builds on Gesture Video Reenactment (GVR), which splits and retrieves video clips using a directed graph structure - representing video frames as nodes and valid transitions as edges. We address two key limitations of GVR: audio-motion misalignment and visual artifacts in GAN-generated transition frames. In particular, (i) we propose retrieving gestures using latent feature distance to improve cross-modal alignment. To ensure the latent features could effectively model the relationship between speech audio and gesture motion, we implement a hierarchical joint embedding space (AuMoCLIP); (ii) we introduce the diffusion-based model to generate high-quality transition frames. Our diffusion model, Appearance Consistent Interpolation (ACInterp), is built upon AnimateAnyone and includes a reference motion module and homography background flow to preserve appearance consistency between generated and reference videos. By integrating these components into the graph-based retrieval framework, TANGO reliably produces realistic, audio-synchronized videos and outperforms all existing generative and retrieval methods. Our codes and pretrained models are available: \url{https://pantomatrix.github.io/TANGO/}
OmniVoxel: A Fast and Precise Reconstruction Method of Omnidirectional Neural Radiance Field
Aug 12, 2022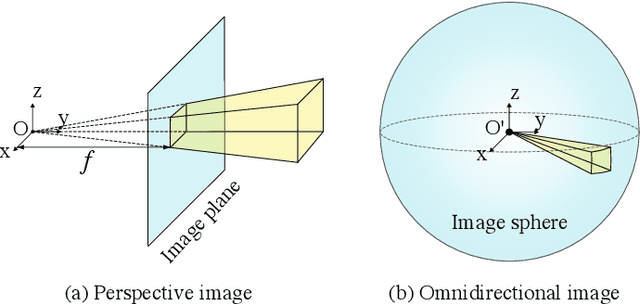
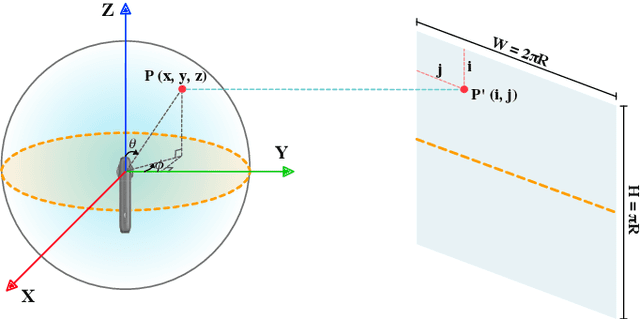

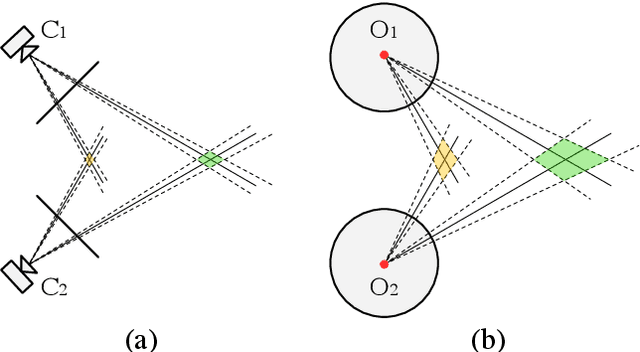
This paper proposes a method to reconstruct the neural radiance field with equirectangular omnidirectional images. Implicit neural scene representation with a radiance field can reconstruct the 3D shape of a scene continuously within a limited spatial area. However, training a fully implicit representation on commercial PC hardware requires a lot of time and computing resources (15 $\sim$ 20 hours per scene). Therefore, we propose a method to accelerate this process significantly (20 $\sim$ 40 minutes per scene). Instead of using a fully implicit representation of rays for radiance field reconstruction, we adopt feature voxels that contain density and color features in tensors. Considering omnidirectional equirectangular input and the camera layout, we use spherical voxelization for representation instead of cubic representation. Our voxelization method could balance the reconstruction quality of the inner scene and outer scene. In addition, we adopt the axis-aligned positional encoding method on the color features to increase the total image quality. Our method achieves satisfying empirical performance on synthetic datasets with random camera poses. Moreover, we test our method with real scenes which contain complex geometries and also achieve state-of-the-art performance. Our code and complete dataset will be released at the same time as the paper publication.