 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTANGO: Co-Speech Gesture Video Reenactment with Hierarchical Audio Motion Embedding and Diffusion Interpolation
Oct 05, 2024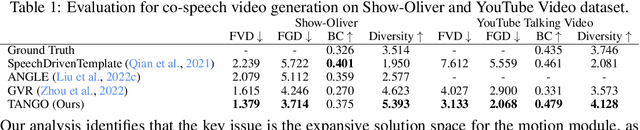


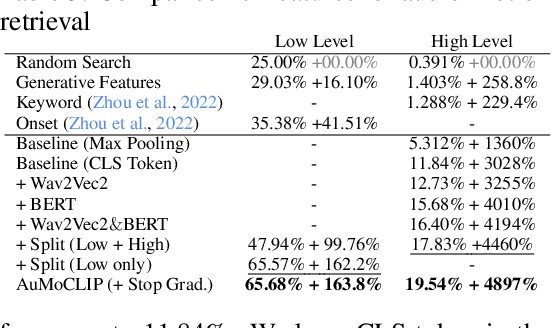
We present TANGO, a framework for generating co-speech body-gesture videos. Given a few-minute, single-speaker reference video and target speech audio, TANGO produces high-fidelity videos with synchronized body gestures. TANGO builds on Gesture Video Reenactment (GVR), which splits and retrieves video clips using a directed graph structure - representing video frames as nodes and valid transitions as edges. We address two key limitations of GVR: audio-motion misalignment and visual artifacts in GAN-generated transition frames. In particular, (i) we propose retrieving gestures using latent feature distance to improve cross-modal alignment. To ensure the latent features could effectively model the relationship between speech audio and gesture motion, we implement a hierarchical joint embedding space (AuMoCLIP); (ii) we introduce the diffusion-based model to generate high-quality transition frames. Our diffusion model, Appearance Consistent Interpolation (ACInterp), is built upon AnimateAnyone and includes a reference motion module and homography background flow to preserve appearance consistency between generated and reference videos. By integrating these components into the graph-based retrieval framework, TANGO reliably produces realistic, audio-synchronized videos and outperforms all existing generative and retrieval methods. Our codes and pretrained models are available: \url{https://pantomatrix.github.io/TANGO/}
Diverse Code Query Learning for Speech-Driven Facial Animation
Sep 27, 2024



Speech-driven facial animation aims to synthesize lip-synchronized 3D talking faces following the given speech signal. Prior methods to this task mostly focus on pursuing realism with deterministic systems, yet characterizing the potentially stochastic nature of facial motions has been to date rarely studied. While generative modeling approaches can easily handle the one-to-many mapping by repeatedly drawing samples, ensuring a diverse mode coverage of plausible facial motions on small-scale datasets remains challenging and less explored. In this paper, we propose predicting multiple samples conditioned on the same audio signal and then explicitly encouraging sample diversity to address diverse facial animation synthesis. Our core insight is to guide our model to explore the expressive facial latent space with a diversity-promoting loss such that the desired latent codes for diversification can be ideally identified. To this end, building upon the rich facial prior learned with vector-quantized variational auto-encoding mechanism, our model temporally queries multiple stochastic codes which can be flexibly decoded into a diverse yet plausible set of speech-faithful facial motions. To further allow for control over different facial parts during generation, the proposed model is designed to predict different facial portions of interest in a sequential manner, and compose them to eventually form full-face motions. Our paradigm realizes both diverse and controllable facial animation synthesis in a unified formulation. We experimentally demonstrate that our method yields state-of-the-art performance both quantitatively and qualitatively, especially regarding sample diversity.
Orientation-Aware Leg Movement Learning for Action-Driven Human Motion Prediction
Oct 23, 2023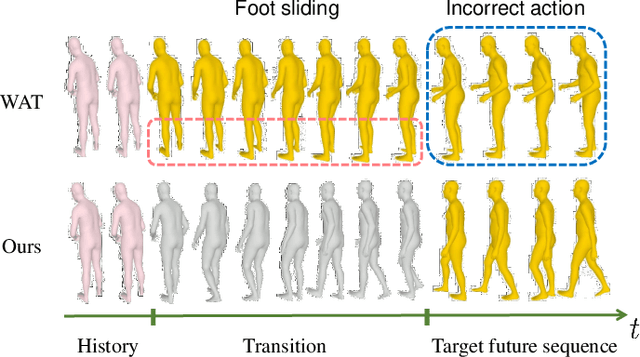
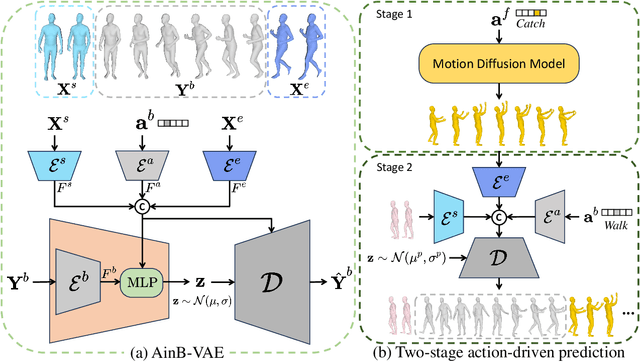
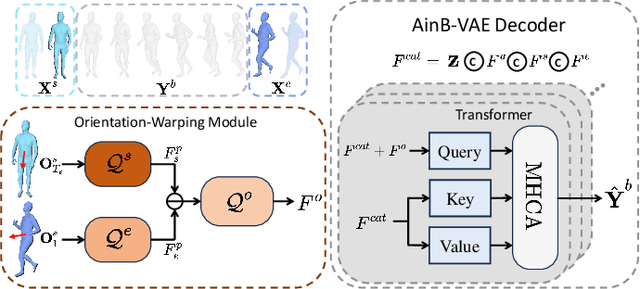
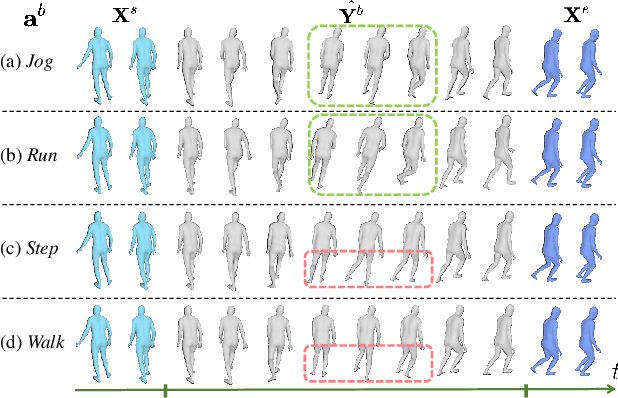
The task of action-driven human motion prediction aims to forecast future human motion from the observed sequence while respecting the given action label. It requires modeling not only the stochasticity within human motion but the smooth yet realistic transition between multiple action labels. However, the fact that most of the datasets do not contain such transition data complicates this task. Existing work tackles this issue by learning a smoothness prior to simply promote smooth transitions, yet doing so can result in unnatural transitions especially when the history and predicted motions differ significantly in orientations. In this paper, we argue that valid human motion transitions should incorporate realistic leg movements to handle orientation changes, and cast it as an action-conditioned in-betweening (ACB) learning task to encourage transition naturalness. Because modeling all possible transitions is virtually unreasonable, our ACB is only performed on very few selected action classes with active gait motions, such as Walk or Run. Specifically, we follow a two-stage forecasting strategy by first employing the motion diffusion model to generate the target motion with a specified future action, and then producing the in-betweening to smoothly connect the observation and prediction to eventually address motion prediction. Our method is completely free from the labeled motion transition data during training. To show the robustness of our approach, we generalize our trained in-betweening learning model on one dataset to two unseen large-scale motion datasets to produce natural transitions. Extensive methods on three benchmark datasets demonstrate that our method yields the state-of-the-art performance in terms of visual quality, prediction accuracy, and action faithfulness.
Animating Landscape: Self-Supervised Learning of Decoupled Motion and Appearance for Single-Image Video Synthesis
Oct 16, 2019

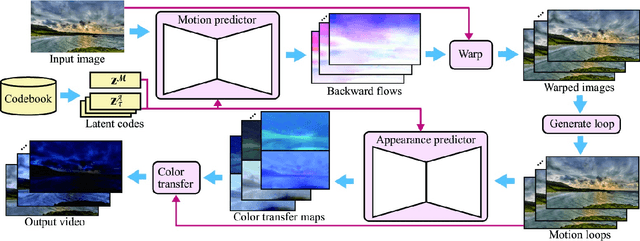

Automatic generation of a high-quality video from a single image remains a challenging task despite the recent advances in deep generative models. This paper proposes a method that can create a high-resolution, long-term animation using convolutional neural networks (CNNs) from a single landscape image where we mainly focus on skies and waters. Our key observation is that the motion (e.g., moving clouds) and appearance (e.g., time-varying colors in the sky) in natural scenes have different time scales. We thus learn them separately and predict them with decoupled control while handling future uncertainty in both predictions by introducing latent codes. Unlike previous methods that infer output frames directly, our CNNs predict spatially-smooth intermediate data, i.e., for motion, flow fields for warping, and for appearance, color transfer maps, via self-supervised learning, i.e., without explicitly-provided ground truth. These intermediate data are applied not to each previous output frame, but to the input image only once for each output frame. This design is crucial to alleviate error accumulation in long-term predictions, which is the essential problem in previous recurrent approaches. The output frames can be looped like cinemagraph, and also be controlled directly by specifying latent codes or indirectly via visual annotations. We demonstrate the effectiveness of our method through comparisons with the state-of-the-arts on video prediction as well as appearance manipulation.