 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDMP-3DAD: Cross-Category 3D Anomaly Detection via Realistic Depth Map Projection with Few Normal Samples
Feb 11, 2026Cross-category anomaly detection for 3D point clouds aims to determine whether an unseen object belongs to a target category using only a few normal examples. Most existing methods rely on category-specific training, which limits their flexibility in few-shot scenarios. In this paper, we propose DMP-3DAD, a training-free framework for cross-category 3D anomaly detection based on multi-view realistic depth map projection. Specifically, by converting point clouds into a fixed set of realistic depth images, our method leverages a frozen CLIP visual encoder to extract multi-view representations and performs anomaly detection via weighted feature similarity, which does not require any fine-tuning or category-dependent adaptation. Extensive experiments on the ShapeNetPart dataset demonstrate that DMP-3DAD achieves state-of-the-art performance under few-shot setting. The results show that the proposed approach provides a simple yet effective solution for practical cross-category 3D anomaly detection.
3D Human-Human Interaction Anomaly Detection
Dec 15, 2025Human-centric anomaly detection (AD) has been primarily studied to specify anomalous behaviors in a single person. However, as humans by nature tend to act in a collaborative manner, behavioral anomalies can also arise from human-human interactions. Detecting such anomalies using existing single-person AD models is prone to low accuracy, as these approaches are typically not designed to capture the complex and asymmetric dynamics of interactions. In this paper, we introduce a novel task, Human-Human Interaction Anomaly Detection (H2IAD), which aims to identify anomalous interactive behaviors within collaborative 3D human actions. To address H2IAD, we then propose Interaction Anomaly Detection Network (IADNet), which is formalized with a Temporal Attention Sharing Module (TASM). Specifically, in designing TASM, we share the encoded motion embeddings across both people such that collaborative motion correlations can be effectively synchronized. Moreover, we notice that in addition to temporal dynamics, human interactions are also characterized by spatial configurations between two people. We thus introduce a Distance-Based Relational Encoding Module (DREM) to better reflect social cues in H2IAD. The normalizing flow is eventually employed for anomaly scoring. Extensive experiments on human-human motion benchmarks demonstrate that IADNet outperforms existing Human-centric AD baselines in H2IAD.
3DKeyAD: High-Resolution 3D Point Cloud Anomaly Detection via Keypoint-Guided Point Clustering
Jul 17, 2025
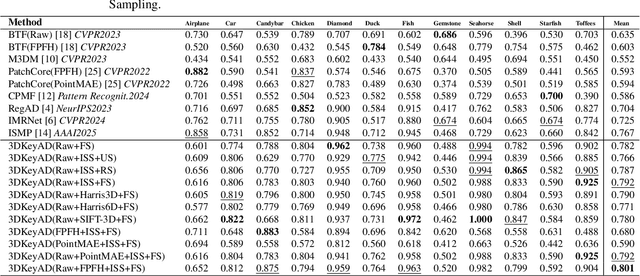

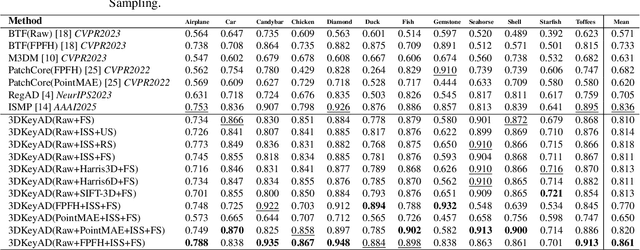
High-resolution 3D point clouds are highly effective for detecting subtle structural anomalies in industrial inspection. However, their dense and irregular nature imposes significant challenges, including high computational cost, sensitivity to spatial misalignment, and difficulty in capturing localized structural differences. This paper introduces a registration-based anomaly detection framework that combines multi-prototype alignment with cluster-wise discrepancy analysis to enable precise 3D anomaly localization. Specifically, each test sample is first registered to multiple normal prototypes to enable direct structural comparison. To evaluate anomalies at a local level, clustering is performed over the point cloud, and similarity is computed between features from the test sample and the prototypes within each cluster. Rather than selecting cluster centroids randomly, a keypoint-guided strategy is employed, where geometrically informative points are chosen as centroids. This ensures that clusters are centered on feature-rich regions, enabling more meaningful and stable distance-based comparisons. Extensive experiments on the Real3D-AD benchmark demonstrate that the proposed method achieves state-of-the-art performance in both object-level and point-level anomaly detection, even using only raw features.
Diverse Code Query Learning for Speech-Driven Facial Animation
Sep 27, 2024



Speech-driven facial animation aims to synthesize lip-synchronized 3D talking faces following the given speech signal. Prior methods to this task mostly focus on pursuing realism with deterministic systems, yet characterizing the potentially stochastic nature of facial motions has been to date rarely studied. While generative modeling approaches can easily handle the one-to-many mapping by repeatedly drawing samples, ensuring a diverse mode coverage of plausible facial motions on small-scale datasets remains challenging and less explored. In this paper, we propose predicting multiple samples conditioned on the same audio signal and then explicitly encouraging sample diversity to address diverse facial animation synthesis. Our core insight is to guide our model to explore the expressive facial latent space with a diversity-promoting loss such that the desired latent codes for diversification can be ideally identified. To this end, building upon the rich facial prior learned with vector-quantized variational auto-encoding mechanism, our model temporally queries multiple stochastic codes which can be flexibly decoded into a diverse yet plausible set of speech-faithful facial motions. To further allow for control over different facial parts during generation, the proposed model is designed to predict different facial portions of interest in a sequential manner, and compose them to eventually form full-face motions. Our paradigm realizes both diverse and controllable facial animation synthesis in a unified formulation. We experimentally demonstrate that our method yields state-of-the-art performance both quantitatively and qualitatively, especially regarding sample diversity.
Subspace-Aware Feature Reconstruction for Unsupervised Anomaly Localization
Sep 25, 2023Unsupervised anomaly localization, which plays a critical role in industrial manufacturing, is to identify anomalous regions that deviate from patterns established exclusively from nominal samples. Recent mainstream methods focus on approximating the target feature distribution by leveraging embeddings from ImageNet models. However, a common issue in many anomaly localization methods is the lack of adaptability of the feature approximations to specific targets. Consequently, their ability to effectively identify anomalous regions relies significantly on the data coverage provided by the finite resources in a memory bank. In this paper, we propose a novel subspace-aware feature reconstruction framework for anomaly localization. To achieve adaptive feature approximation, our proposed method involves the reconstruction of the feature representation through the self-expressive model designed to learn low-dimensional subspaces. Importantly, the sparsity of the subspace representation contributes to covering feature patterns from the same subspace with fewer resources, leading to a reduction in the memory bank. Extensive experiments across three industrial benchmark datasets demonstrate that our approach achieves competitive anomaly localization performance compared to state-of-the-art methods by adaptively reconstructing target features with a small number of samples.
PMSSC: Parallelizable Multi-Subset based Self-Expressive Model for Subspace Clustering
Nov 24, 2021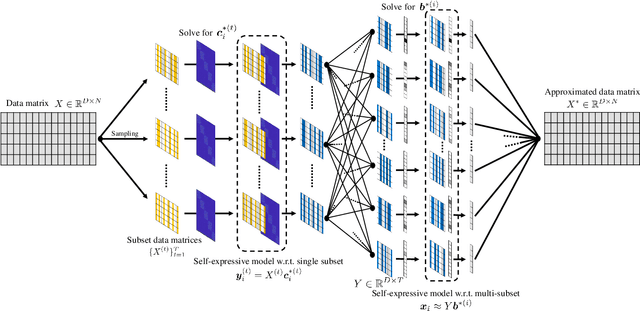
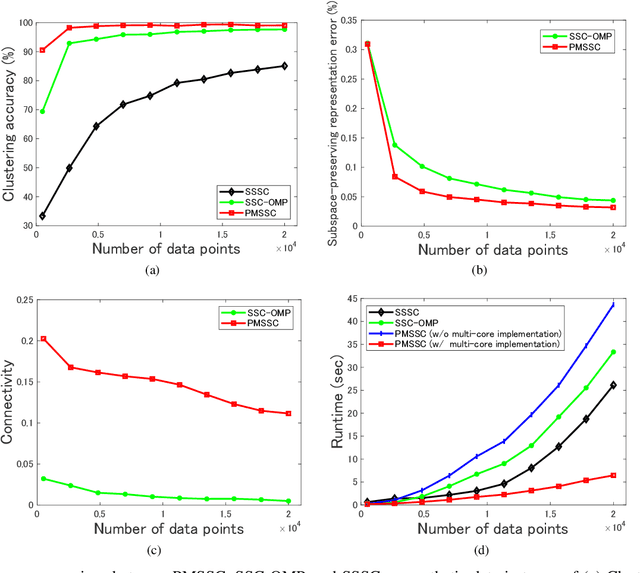

Subspace clustering methods embrace a self-expressive model that represents each data point as a linear combination of other data points in the dataset are powerful unsupervised learning techniques. However, when dealing with large-scale datasets, the representation of each data point by referring to all data points as a dictionary suffers from high computational complexity. To alleviate this issue, we introduce a parallelizable multi-subset based self-expressive model (PMS) which represents each data point by combing multiple subsets, with each consisting of only a small percentage of samples. The adoption of PMS in subspace clustering (PMSSC) leads to computational advantages because each optimization problem decomposed into each subset is small, and can be solved efficiently in parallel. Besides, PMSSC is able to combine multiple self-expressive coefficient vectors obtained from subsets, which contributes to the improvement of self-expressiveness. Extensive experiments on synthetic data and real-world datasets show the efficiency and effectiveness of our approach against competitive methods.
G2MF-WA: Geometric Multi-Model Fitting with Weakly Annotated Data
Jan 20, 2020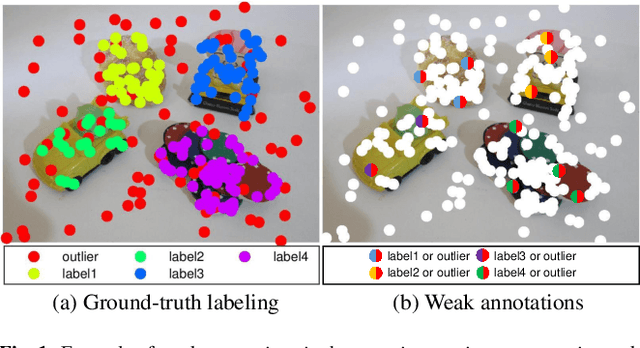
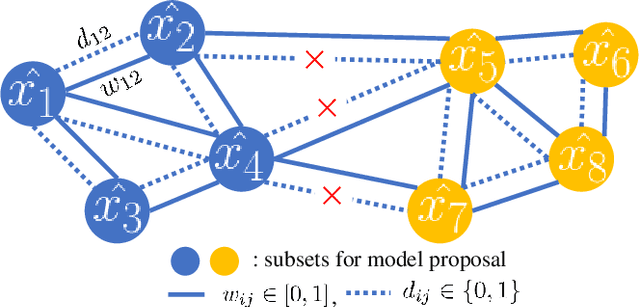

In this paper we attempt to address the problem of geometric multi-model fitting with resorting to a few weakly annotated (WA) data points, which has been sparsely studied so far. In weak annotating, most of the manual annotations are supposed to be correct yet inevitably mixed with incorrect ones. The WA data can be naturally obtained in an interactive way for specific tasks, for example, in the case of homography estimation, one can easily annotate points on the same plane/object with a single label by observing the image. Motivated by this, we propose a novel method to make full use of the WA data to boost the multi-model fitting performance. Specifically, a graph for model proposal sampling is first constructed using the WA data, given the prior that the WA data annotated with the same weak label has a high probability of being assigned to the same model. By incorporating this prior knowledge into the calculation of edge probabilities, vertices (i.e., data points) lie on/near the latent model are likely to connect together and further form a subset/cluster for effective proposals generation. With the proposals generated, the $\alpha$-expansion is adopted for labeling, and our method in return updates the proposals. This works in an iterative way. Extensive experiments validate our method and show that the proposed method produces noticeably better results than state-of-the-art techniques in most cases.