 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMethod of Tracking and Analysis of Fluorescent-Labeled Cells Using Automatic Thresholding and Labeling
Feb 27, 2024



High-throughput screening using cell images is an efficient method for screening new candidates for pharmaceutical drugs. To complete the screening process, it is essential to have an efficient process for analyzing cell images. This paper presents a new method for efficiently tracking cells and quantitatively detecting the signal ratio between cytoplasm and nuclei. Existing methods include those that use image processing techniques and those that utilize artificial intelligence (AI). However, these methods do not consider the correspondence of cells between images, or require a significant amount of new learning data to train AI. Therefore, our method uses automatic thresholding and labeling algorithms to compare the position of each cell between images, and continuously measure and analyze the signal ratio of cells. This paper describes the algorithm of our method. Using the method, we experimented to investigate the effect of the number of opening and closing operations during the binarization process on the tracking of the cells. Through the experiment, we determined the appropriate number of opening and closing processes.
Subspace-Aware Feature Reconstruction for Unsupervised Anomaly Localization
Sep 25, 2023Unsupervised anomaly localization, which plays a critical role in industrial manufacturing, is to identify anomalous regions that deviate from patterns established exclusively from nominal samples. Recent mainstream methods focus on approximating the target feature distribution by leveraging embeddings from ImageNet models. However, a common issue in many anomaly localization methods is the lack of adaptability of the feature approximations to specific targets. Consequently, their ability to effectively identify anomalous regions relies significantly on the data coverage provided by the finite resources in a memory bank. In this paper, we propose a novel subspace-aware feature reconstruction framework for anomaly localization. To achieve adaptive feature approximation, our proposed method involves the reconstruction of the feature representation through the self-expressive model designed to learn low-dimensional subspaces. Importantly, the sparsity of the subspace representation contributes to covering feature patterns from the same subspace with fewer resources, leading to a reduction in the memory bank. Extensive experiments across three industrial benchmark datasets demonstrate that our approach achieves competitive anomaly localization performance compared to state-of-the-art methods by adaptively reconstructing target features with a small number of samples.
PMSSC: Parallelizable Multi-Subset based Self-Expressive Model for Subspace Clustering
Nov 24, 2021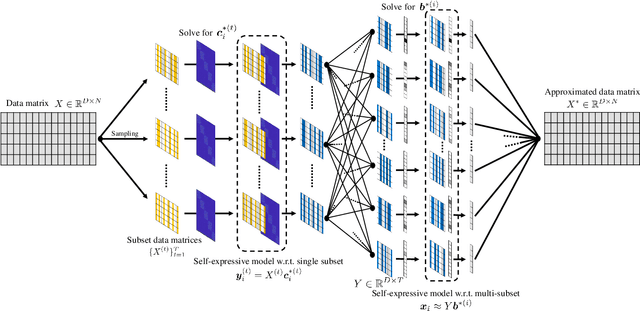
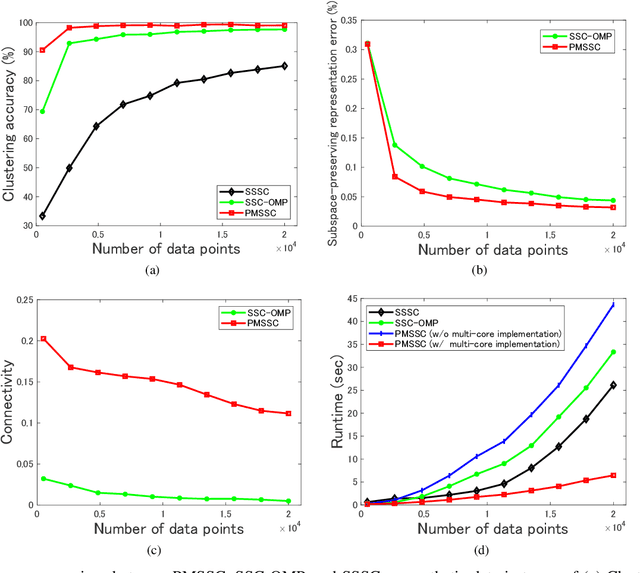

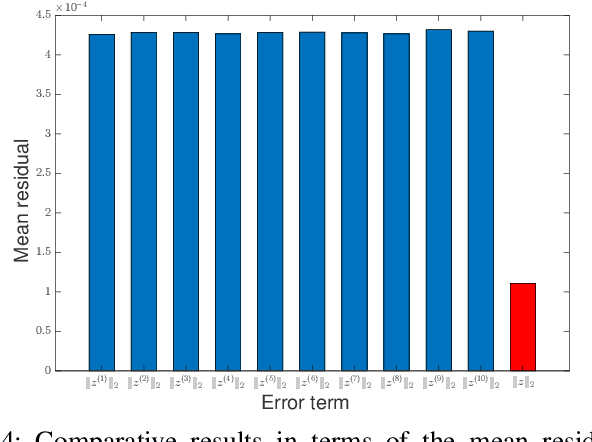
Subspace clustering methods embrace a self-expressive model that represents each data point as a linear combination of other data points in the dataset are powerful unsupervised learning techniques. However, when dealing with large-scale datasets, the representation of each data point by referring to all data points as a dictionary suffers from high computational complexity. To alleviate this issue, we introduce a parallelizable multi-subset based self-expressive model (PMS) which represents each data point by combing multiple subsets, with each consisting of only a small percentage of samples. The adoption of PMS in subspace clustering (PMSSC) leads to computational advantages because each optimization problem decomposed into each subset is small, and can be solved efficiently in parallel. Besides, PMSSC is able to combine multiple self-expressive coefficient vectors obtained from subsets, which contributes to the improvement of self-expressiveness. Extensive experiments on synthetic data and real-world datasets show the efficiency and effectiveness of our approach against competitive methods.
Multi-scale Template Matching with Scalable Diversity Similarity in an Unconstrained Environment
Jul 02, 2019
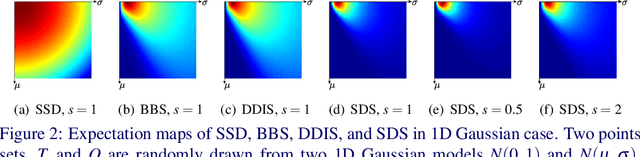
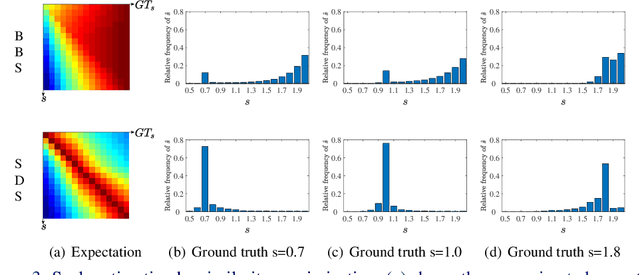
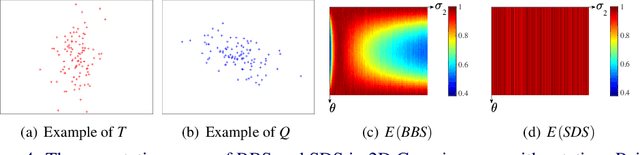
We propose a novel multi-scale template matching method which is robust against both scaling and rotation in unconstrained environments. The key component behind is a similarity measure referred to as scalable diversity similarity (SDS). Specifically, SDS exploits bidirectional diversity of the nearest neighbor (NN) matches between two sets of points. To address the scale-robustness of the similarity measure, local appearance and rank information are jointly used for the NN search. Furthermore, by introducing penalty term on the scale change, and polar radius term into the similarity measure, SDS is shown to be a well-performing similarity measure against overall size and rotation changes, as well as non-rigid geometric deformations, background clutter, and occlusions. The properties of SDS are statistically justified, and experiments on both synthetic and real-world data show that SDS can significantly outperform state-of-the-art methods.
A Probabilistic Bitwise Genetic Algorithm for B-Spline based Image Deformation Estimation
Mar 26, 2019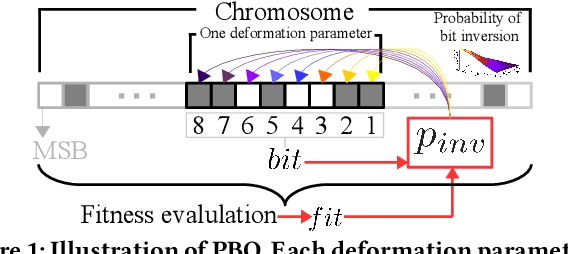
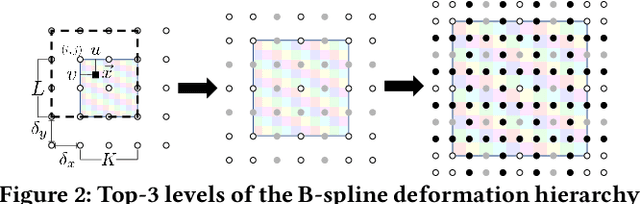
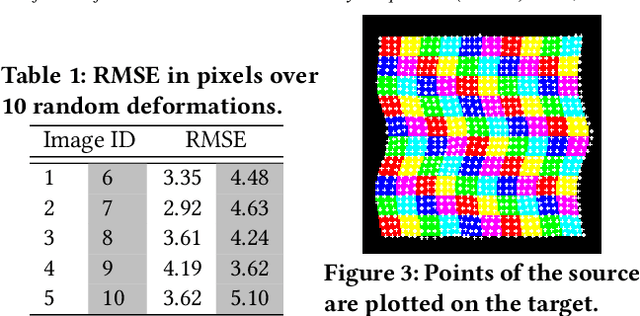
We propose a novel genetic algorithm to solve the image deformation estimation problem by preserving the genetic diversity. As a classical problem, there is always a trade-off between the complexity of deformation models and the difficulty of parameters search in image deformation. 2D cubic B-spline surface is a highly free-form deformation model and is able to handle complex deformations such as fluid image distortions. However, it is challenging to estimate an apposite global solution. To tackle this problem, we develop a genetic operation named probabilistic bitwise operation (PBO) to replace the crossover and mutation operations, which can preserve the diversity during generation iteration and achieve better coverage ratio of the solution space. Furthermore, a selection strategy named annealing selection is proposed to control the convergence. Qualitative and quantitative results on synthetic data show the effectiveness of our method.
Cross-domain Deep Feature Combination for Bird Species Classification with Audio-visual Data
Nov 26, 2018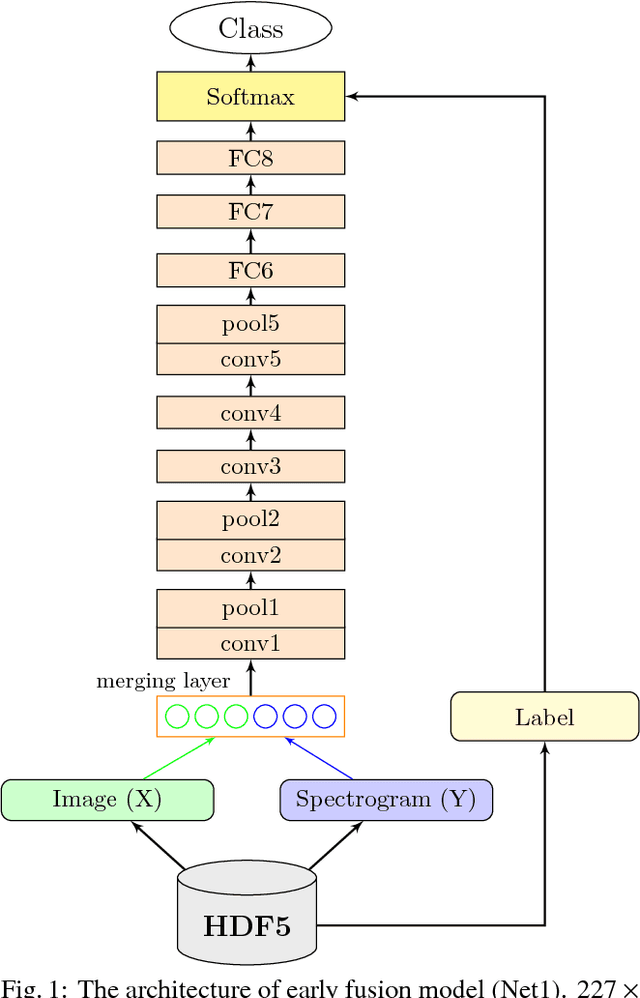

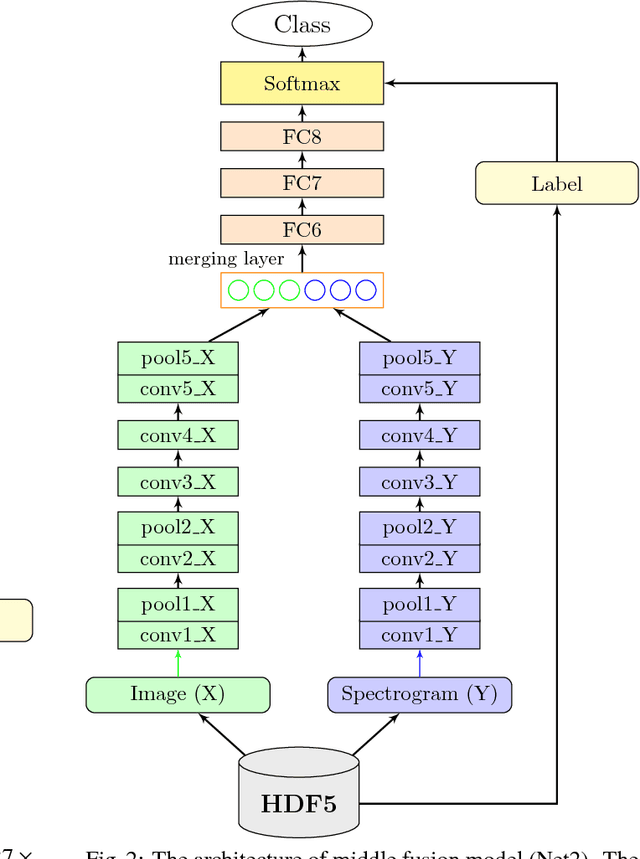

In recent decade, many state-of-the-art algorithms on image classification as well as audio classification have achieved noticeable successes with the development of deep convolutional neural network (CNN). However, most of the works only exploit single type of training data. In this paper, we present a study on classifying bird species by exploiting the combination of both visual (images) and audio (sounds) data using CNN, which has been sparsely treated so far. Specifically, we propose CNN-based multimodal learning models in three types of fusion strategies (early, middle, late) to settle the issues of combining training data cross domains. The advantage of our proposed method lies on the fact that We can utilize CNN not only to extract features from image and audio data (spectrogram) but also to combine the features across modalities. In the experiment, we train and evaluate the network structure on a comprehensive CUB-200-2011 standard data set combing our originally collected audio data set with respect to the data species. We observe that a model which utilizes the combination of both data outperforms models trained with only an either type of data. We also show that transfer learning can significantly increase the classification performance.
Blur-Countering Keypoint Detection via Eigenvalue Asymmetry
Sep 05, 2018
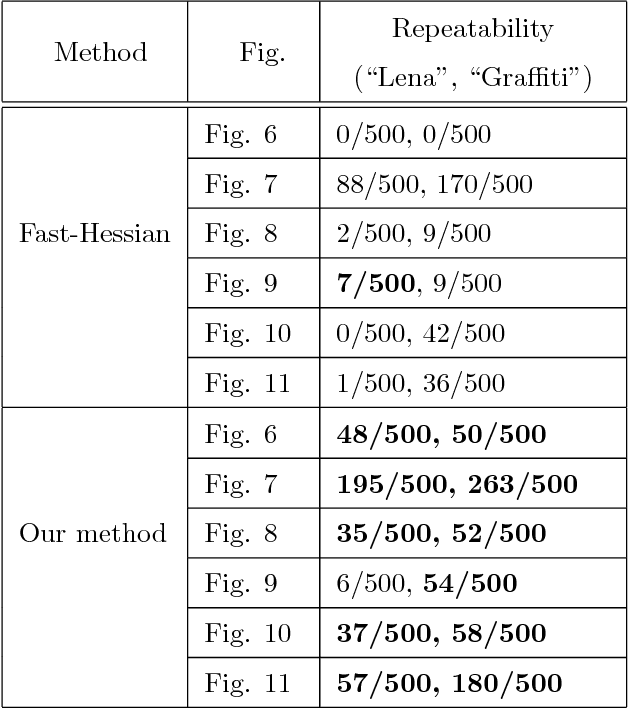
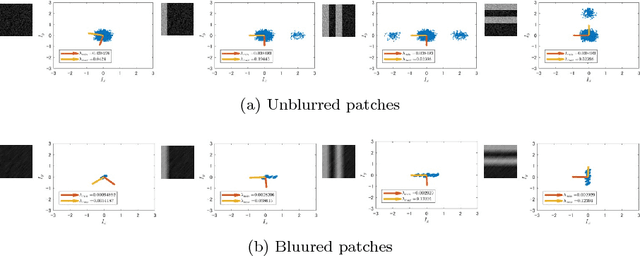
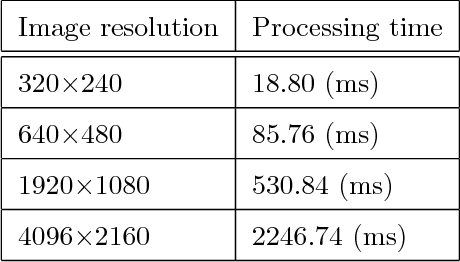
Well-known corner or local extrema feature based detectors such as FAST and DoG have achieved noticeable successes. However, detecting keypoints in the presence of blur has remained to be an unresolved issue. As a matter of fact, various kinds of blur (e.g., motion blur, out-of-focus, and space-variant) remarkably increase challenges for keypoint detection. As a result, those methods have limited performance. To settle this issue, we propose a blur-countering method for detecting valid keypoints for various types and degrees of blurred images. Specifically, we first present a distance metric for derivative distributions, which preserves the distinctiveness of patch pairs well under blur. We then model the asymmetry by utilizing the difference of squared eigenvalues based on the distance metric. To make it scale-robust, we also extend it to scale space. The proposed detector is efficient as the main computational cost is the square of derivatives at each pixel. Extensive visual and quantitative results show that our method outperforms current approaches under different types and degrees of blur. Without any parallelization, our implementation\footnote{We will make our code publicly available upon the acceptance.} achieves real-time performance for low-resolution images (e.g., $320\times240$ pixel).