 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVID-AD: A Dataset for Image-Level Logical Anomaly Detection under Vision-Induced Distraction
Mar 14, 2026Logical anomaly detection in industrial inspection remains challenging due to variations in visual appearance (e.g., background clutter, illumination shift, and blur), which often distract vision-centric detectors from identifying rule-level violations. However, existing benchmarks rarely provide controlled settings where logical states are fixed while such nuisance factors vary. To address this gap, we introduce VID-AD, a dataset for logical anomaly detection under vision-induced distraction. It comprises 10 manufacturing scenarios and five capture conditions, totaling 50 one-class tasks and 10,395 images. Each scenario is defined by two logical constraints selected from quantity, length, type, placement, and relation, with anomalies including both single-constraint and combined violations. We further propose a language-based anomaly detection framework that relies solely on text descriptions generated from normal images. Using contrastive learning with positive texts and contradiction-based negative texts synthesized from these descriptions, our method learns embeddings that capture logical attributes rather than low-level features. Extensive experiments demonstrate consistent improvements over baselines across the evaluated settings. The dataset is available at: https://github.com/nkthiroto/VID-AD.
3D Human-Human Interaction Anomaly Detection
Dec 15, 2025Human-centric anomaly detection (AD) has been primarily studied to specify anomalous behaviors in a single person. However, as humans by nature tend to act in a collaborative manner, behavioral anomalies can also arise from human-human interactions. Detecting such anomalies using existing single-person AD models is prone to low accuracy, as these approaches are typically not designed to capture the complex and asymmetric dynamics of interactions. In this paper, we introduce a novel task, Human-Human Interaction Anomaly Detection (H2IAD), which aims to identify anomalous interactive behaviors within collaborative 3D human actions. To address H2IAD, we then propose Interaction Anomaly Detection Network (IADNet), which is formalized with a Temporal Attention Sharing Module (TASM). Specifically, in designing TASM, we share the encoded motion embeddings across both people such that collaborative motion correlations can be effectively synchronized. Moreover, we notice that in addition to temporal dynamics, human interactions are also characterized by spatial configurations between two people. We thus introduce a Distance-Based Relational Encoding Module (DREM) to better reflect social cues in H2IAD. The normalizing flow is eventually employed for anomaly scoring. Extensive experiments on human-human motion benchmarks demonstrate that IADNet outperforms existing Human-centric AD baselines in H2IAD.
Few-shot Human Action Anomaly Detection via a Unified Contrastive Learning Framework
Aug 25, 2025


Human Action Anomaly Detection (HAAD) aims to identify anomalous actions given only normal action data during training. Existing methods typically follow a one-model-per-category paradigm, requiring separate training for each action category and a large number of normal samples. These constraints hinder scalability and limit applicability in real-world scenarios, where data is often scarce or novel categories frequently appear. To address these limitations, we propose a unified framework for HAAD that is compatible with few-shot scenarios. Our method constructs a category-agnostic representation space via contrastive learning, enabling AD by comparing test samples with a given small set of normal examples (referred to as the support set). To improve inter-category generalization and intra-category robustness, we introduce a generative motion augmentation strategy harnessing a diffusion-based foundation model for creating diverse and realistic training samples. Notably, to the best of our knowledge, our work is the first to introduce such a strategy specifically tailored to enhance contrastive learning for action AD. Extensive experiments on the HumanAct12 dataset demonstrate the state-of-the-art effectiveness of our approach under both seen and unseen category settings, regarding training efficiency and model scalability for few-shot HAAD.
Label-Consistent Dataset Distillation with Detector-Guided Refinement
Jul 17, 2025Dataset distillation (DD) aims to generate a compact yet informative dataset that achieves performance comparable to the original dataset, thereby reducing demands on storage and computational resources. Although diffusion models have made significant progress in dataset distillation, the generated surrogate datasets often contain samples with label inconsistencies or insufficient structural detail, leading to suboptimal downstream performance. To address these issues, we propose a detector-guided dataset distillation framework that explicitly leverages a pre-trained detector to identify and refine anomalous synthetic samples, thereby ensuring label consistency and improving image quality. Specifically, a detector model trained on the original dataset is employed to identify anomalous images exhibiting label mismatches or low classification confidence. For each defective image, multiple candidates are generated using a pre-trained diffusion model conditioned on the corresponding image prototype and label. The optimal candidate is then selected by jointly considering the detector's confidence score and dissimilarity to existing qualified synthetic samples, thereby ensuring both label accuracy and intra-class diversity. Experimental results demonstrate that our method can synthesize high-quality representative images with richer details, achieving state-of-the-art performance on the validation set.
Diverse Code Query Learning for Speech-Driven Facial Animation
Sep 27, 2024



Speech-driven facial animation aims to synthesize lip-synchronized 3D talking faces following the given speech signal. Prior methods to this task mostly focus on pursuing realism with deterministic systems, yet characterizing the potentially stochastic nature of facial motions has been to date rarely studied. While generative modeling approaches can easily handle the one-to-many mapping by repeatedly drawing samples, ensuring a diverse mode coverage of plausible facial motions on small-scale datasets remains challenging and less explored. In this paper, we propose predicting multiple samples conditioned on the same audio signal and then explicitly encouraging sample diversity to address diverse facial animation synthesis. Our core insight is to guide our model to explore the expressive facial latent space with a diversity-promoting loss such that the desired latent codes for diversification can be ideally identified. To this end, building upon the rich facial prior learned with vector-quantized variational auto-encoding mechanism, our model temporally queries multiple stochastic codes which can be flexibly decoded into a diverse yet plausible set of speech-faithful facial motions. To further allow for control over different facial parts during generation, the proposed model is designed to predict different facial portions of interest in a sequential manner, and compose them to eventually form full-face motions. Our paradigm realizes both diverse and controllable facial animation synthesis in a unified formulation. We experimentally demonstrate that our method yields state-of-the-art performance both quantitatively and qualitatively, especially regarding sample diversity.
Incremental Pseudo-Labeling for Black-Box Unsupervised Domain Adaptation
May 26, 2024Black-Box unsupervised domain adaptation (BBUDA) learns knowledge only with the prediction of target data from the source model without access to the source data and source model, which attempts to alleviate concerns about the privacy and security of data. However, incorrect pseudo-labels are prevalent in the prediction generated by the source model due to the cross-domain discrepancy, which may substantially degrade the performance of the target model. To address this problem, we propose a novel approach that incrementally selects high-confidence pseudo-labels to improve the generalization ability of the target model. Specifically, we first generate pseudo-labels using a source model and train a crude target model by a vanilla BBUDA method. Second, we iteratively select high-confidence data from the low-confidence data pool by thresholding the softmax probabilities, prototype labels, and intra-class similarity. Then, we iteratively train a stronger target network based on the crude target model to correct the wrongly labeled samples to improve the accuracy of the pseudo-label. Experimental results demonstrate that the proposed method achieves state-of-the-art black-box unsupervised domain adaptation performance on three benchmark datasets.
Frequency-Guided Multi-Level Human Action Anomaly Detection with Normalizing Flows
Apr 26, 2024



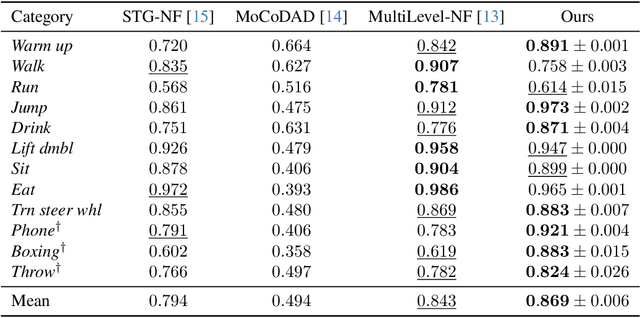
We introduce the task of human action anomaly detection (HAAD), which aims to identify anomalous motions in an unsupervised manner given only the pre-determined normal category of training action samples. Compared to prior human-related anomaly detection tasks which primarily focus on unusual events from videos, HAAD involves the learning of specific action labels to recognize semantically anomalous human behaviors. To address this task, we propose a normalizing flow (NF)-based detection framework where the sample likelihood is effectively leveraged to indicate anomalies. As action anomalies often occur in some specific body parts, in addition to the full-body action feature learning, we incorporate extra encoding streams into our framework for a finer modeling of body subsets. Our framework is thus multi-level to jointly discover global and local motion anomalies. Furthermore, to show awareness of the potentially jittery data during recording, we resort to discrete cosine transformation by converting the action samples from the temporal to the frequency domain to mitigate the issue of data instability. Extensive experimental results on two human action datasets demonstrate that our method outperforms the baselines formed by adapting state-of-the-art human activity AD approaches to our task of HAAD.
Multilevel Saliency-Guided Self-Supervised Learning for Image Anomaly Detection
Nov 30, 2023Anomaly detection (AD) is a fundamental task in computer vision. It aims to identify incorrect image data patterns which deviate from the normal ones. Conventional methods generally address AD by preparing augmented negative samples to enforce self-supervised learning. However, these techniques typically do not consider semantics during augmentation, leading to the generation of unrealistic or invalid negative samples. Consequently, the feature extraction network can be hindered from embedding critical features. In this study, inspired by visual attention learning approaches, we propose CutSwap, which leverages saliency guidance to incorporate semantic cues for augmentation. Specifically, we first employ LayerCAM to extract multilevel image features as saliency maps and then perform clustering to obtain multiple centroids. To fully exploit saliency guidance, on each map, we select a pixel pair from the cluster with the highest centroid saliency to form a patch pair. Such a patch pair includes highly similar context information with dense semantic correlations. The resulting negative sample is created by swapping the locations of the patch pair. Compared to prior augmentation methods, CutSwap generates more subtle yet realistic negative samples to facilitate quality feature learning. Extensive experimental and ablative evaluations demonstrate that our method achieves state-of-the-art AD performance on two mainstream AD benchmark datasets.
Image-Pointcloud Fusion based Anomaly Detection using PD-REAL Dataset
Nov 07, 2023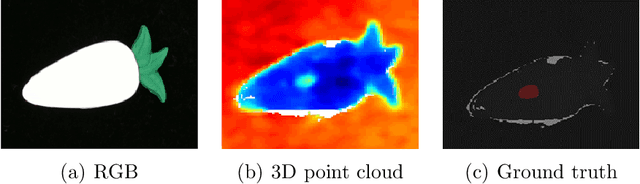
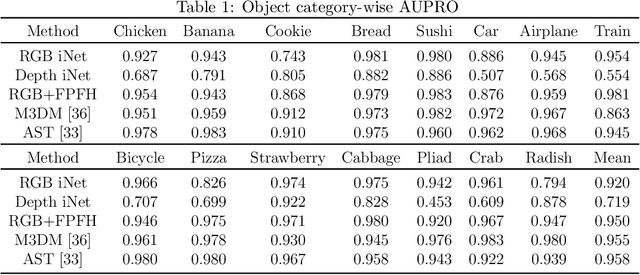
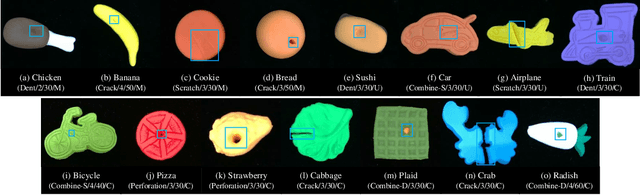
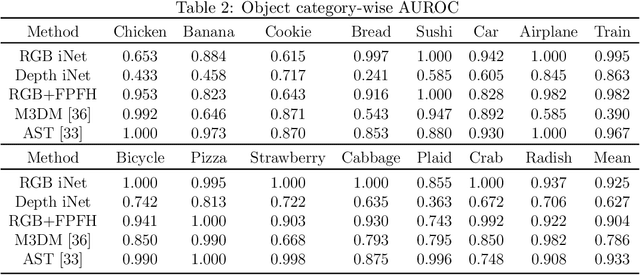
We present PD-REAL, a novel large-scale dataset for unsupervised anomaly detection (AD) in the 3D domain. It is motivated by the fact that 2D-only representations in the AD task may fail to capture the geometric structures of anomalies due to uncertainty in lighting conditions or shooting angles. PD-REAL consists entirely of Play-Doh models for 15 object categories and focuses on the analysis of potential benefits from 3D information in a controlled environment. Specifically, objects are first created with six types of anomalies, such as dent, crack, or perforation, and then photographed under different lighting conditions to mimic real-world inspection scenarios. To demonstrate the usefulness of 3D information, we use a commercially available RealSense camera to capture RGB and depth images. Compared to the existing 3D dataset for AD tasks, the data acquisition of PD-REAL is significantly cheaper, easily scalable and easier to control variables. Extensive evaluations with state-of-the-art AD algorithms on our dataset demonstrate the benefits as well as challenges of using 3D information. Our dataset can be downloaded from https://github.com/Andy-cs008/PD-REAL
Orientation-Aware Leg Movement Learning for Action-Driven Human Motion Prediction
Oct 23, 2023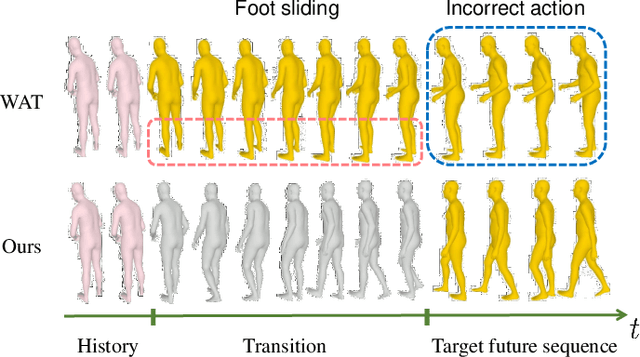
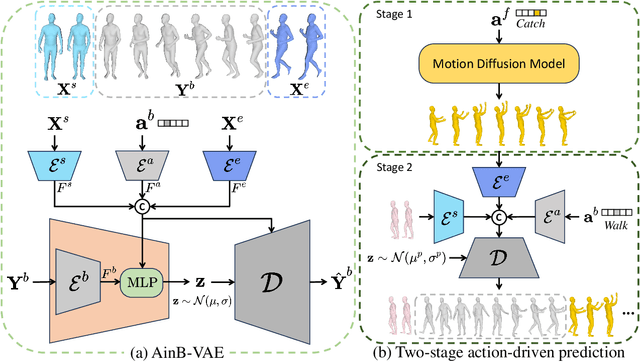
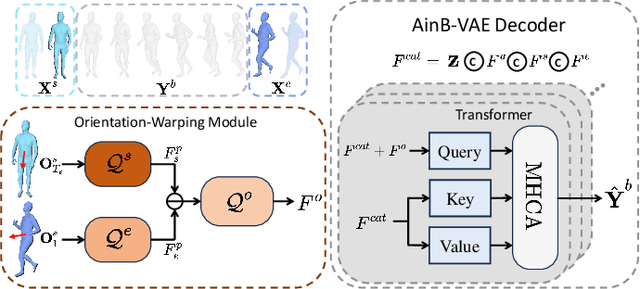
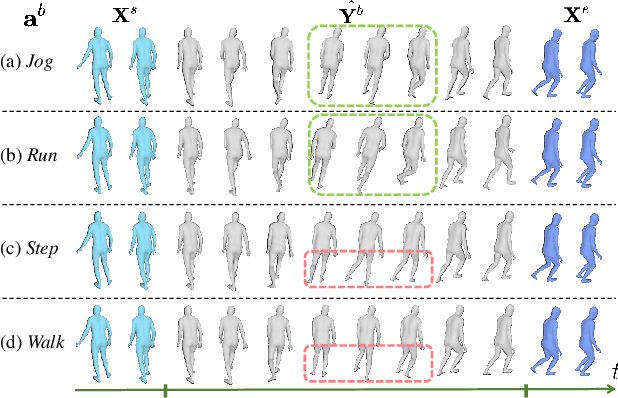
The task of action-driven human motion prediction aims to forecast future human motion from the observed sequence while respecting the given action label. It requires modeling not only the stochasticity within human motion but the smooth yet realistic transition between multiple action labels. However, the fact that most of the datasets do not contain such transition data complicates this task. Existing work tackles this issue by learning a smoothness prior to simply promote smooth transitions, yet doing so can result in unnatural transitions especially when the history and predicted motions differ significantly in orientations. In this paper, we argue that valid human motion transitions should incorporate realistic leg movements to handle orientation changes, and cast it as an action-conditioned in-betweening (ACB) learning task to encourage transition naturalness. Because modeling all possible transitions is virtually unreasonable, our ACB is only performed on very few selected action classes with active gait motions, such as Walk or Run. Specifically, we follow a two-stage forecasting strategy by first employing the motion diffusion model to generate the target motion with a specified future action, and then producing the in-betweening to smoothly connect the observation and prediction to eventually address motion prediction. Our method is completely free from the labeled motion transition data during training. To show the robustness of our approach, we generalize our trained in-betweening learning model on one dataset to two unseen large-scale motion datasets to produce natural transitions. Extensive methods on three benchmark datasets demonstrate that our method yields the state-of-the-art performance in terms of visual quality, prediction accuracy, and action faithfulness.