 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DKeyAD: High-Resolution 3D Point Cloud Anomaly Detection via Keypoint-Guided Point Clustering
Jul 17, 2025
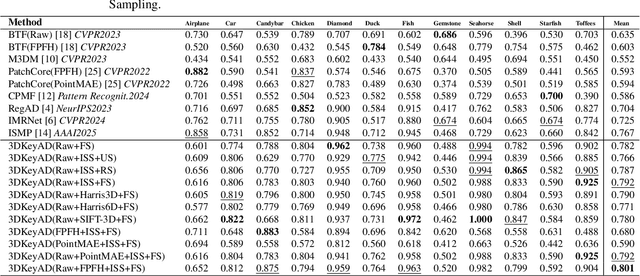

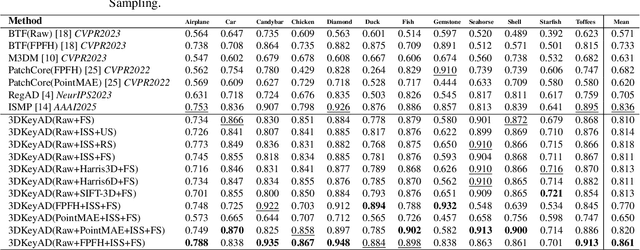
High-resolution 3D point clouds are highly effective for detecting subtle structural anomalies in industrial inspection. However, their dense and irregular nature imposes significant challenges, including high computational cost, sensitivity to spatial misalignment, and difficulty in capturing localized structural differences. This paper introduces a registration-based anomaly detection framework that combines multi-prototype alignment with cluster-wise discrepancy analysis to enable precise 3D anomaly localization. Specifically, each test sample is first registered to multiple normal prototypes to enable direct structural comparison. To evaluate anomalies at a local level, clustering is performed over the point cloud, and similarity is computed between features from the test sample and the prototypes within each cluster. Rather than selecting cluster centroids randomly, a keypoint-guided strategy is employed, where geometrically informative points are chosen as centroids. This ensures that clusters are centered on feature-rich regions, enabling more meaningful and stable distance-based comparisons. Extensive experiments on the Real3D-AD benchmark demonstrate that the proposed method achieves state-of-the-art performance in both object-level and point-level anomaly detection, even using only raw features.
Label-Consistent Dataset Distillation with Detector-Guided Refinement
Jul 17, 2025Dataset distillation (DD) aims to generate a compact yet informative dataset that achieves performance comparable to the original dataset, thereby reducing demands on storage and computational resources. Although diffusion models have made significant progress in dataset distillation, the generated surrogate datasets often contain samples with label inconsistencies or insufficient structural detail, leading to suboptimal downstream performance. To address these issues, we propose a detector-guided dataset distillation framework that explicitly leverages a pre-trained detector to identify and refine anomalous synthetic samples, thereby ensuring label consistency and improving image quality. Specifically, a detector model trained on the original dataset is employed to identify anomalous images exhibiting label mismatches or low classification confidence. For each defective image, multiple candidates are generated using a pre-trained diffusion model conditioned on the corresponding image prototype and label. The optimal candidate is then selected by jointly considering the detector's confidence score and dissimilarity to existing qualified synthetic samples, thereby ensuring both label accuracy and intra-class diversity. Experimental results demonstrate that our method can synthesize high-quality representative images with richer details, achieving state-of-the-art performance on the validation set.
Incremental Pseudo-Labeling for Black-Box Unsupervised Domain Adaptation
May 26, 2024Black-Box unsupervised domain adaptation (BBUDA) learns knowledge only with the prediction of target data from the source model without access to the source data and source model, which attempts to alleviate concerns about the privacy and security of data. However, incorrect pseudo-labels are prevalent in the prediction generated by the source model due to the cross-domain discrepancy, which may substantially degrade the performance of the target model. To address this problem, we propose a novel approach that incrementally selects high-confidence pseudo-labels to improve the generalization ability of the target model. Specifically, we first generate pseudo-labels using a source model and train a crude target model by a vanilla BBUDA method. Second, we iteratively select high-confidence data from the low-confidence data pool by thresholding the softmax probabilities, prototype labels, and intra-class similarity. Then, we iteratively train a stronger target network based on the crude target model to correct the wrongly labeled samples to improve the accuracy of the pseudo-label. Experimental results demonstrate that the proposed method achieves state-of-the-art black-box unsupervised domain adaptation performance on three benchmark datasets.